学習
学習 データリーケージとは?機械学習で精度を誤る原因と対策
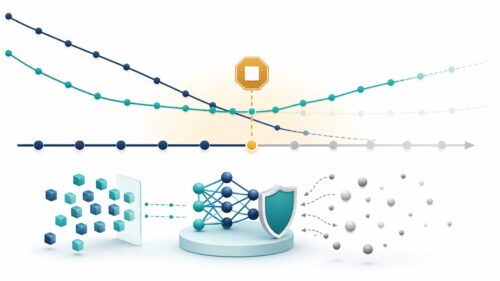
データリーケージとは、機械学習の模型を作る過程で、本来使ってはいけない情報が、こっそりと入り込んでしまう現象のことを指します。水道の管から水が漏れるように、予想外の情報が模型に入り込む様子から、この名前が付けられました。一見すると、漏れた情報によって模型の正答率は上がるように見えます。しかし、これは表面的なものに過ぎません。なぜなら、現実世界で使う状況では、漏れた情報は使えないからです。
例を挙げると、病気の診断支援をする模型を作るとします。この時、訓練データに患者の血液検査データだけでなく、将来の診断結果も含まれていたとしましょう。模型は将来の結果も見て学習するため、非常に高い正答率を叩き出します。しかし、現実の診断現場では、将来の結果は当然ながら分かりません。そのため、高い正答率を誇っていた模型も、実際の診断では全く役に立たないものになってしまいます。これは、まるで試験中に解答を見て高得点を取ったものの、実際の仕事では何もできない人材を育てるようなものです。
リークは、模型開発における重大な問題です。その影響を正しく理解し、対策を講じる必要があります。具体的には、データの準備段階で、目的変数(予測したい値)に影響を与える情報が、説明変数(予測に使う情報)に含まれていないかを注意深く確認する必要があります。また、時間的なずれにも注意が必要です。例えば、未来の情報が過去の情報を予測するために使われていないかを確認する必要があります。このような注意深い確認作業を行うことで、データリーケージを防ぎ、信頼性の高い機械学習模型を作ることができます。