過学習を防ぐ正則化とは

AIの初心者
「正則化」って難しくてよくわかりません。簡単にいうと何をする技術なんですか?

AI専門家
正則化は、AIや機械学習のモデルが複雑になりすぎないように調整する仕組みだよ。訓練データに完全に合わせるより、全体の傾向を捉える形に近づけるイメージだね。
AIの初心者
訓練データにぴったり合わせる方が良さそうなのに、なぜ少し抑える必要があるんですか?
AI専門家
ぴったり合わせすぎると、訓練データのノイズや例外まで覚えてしまうことがあるんだ。正則化で複雑さを抑えると、新しいデータにも対応しやすい汎用的なモデルを作りやすくなるよ。
正則化とは。
正則化とは、機械学習モデルが訓練データに合わせすぎることを防ぐために、モデルの複雑さへペナルティを与える手法です。過学習を抑え、未知のデータに対しても安定して予測できるモデルを目指すときに使われます。
機械学習では、予測値と正解値のずれを小さくするようにモデルを学習します。しかし、訓練データだけに過度に適応すると、訓練時の精度は高く見えても、実際に新しいデータを入れたときの精度が下がることがあります。この状態が過学習です。
正則化は、損失関数に「重みが大きくなりすぎないようにする項」を加え、モデルが細かなノイズに反応しすぎないようにします。本記事では、正則化の仕組み、L1正則化とL2正則化の違い、使いどころ、正規化との違いを初心者向けに整理します。
正則化の役割
機械学習の目的は、訓練データを覚えることではなく、まだ見ていない未知のデータに対しても正しく予測できることです。この未知データへの対応力を汎化性能と呼びます。正則化は、汎化性能を高めるための代表的な方法です。
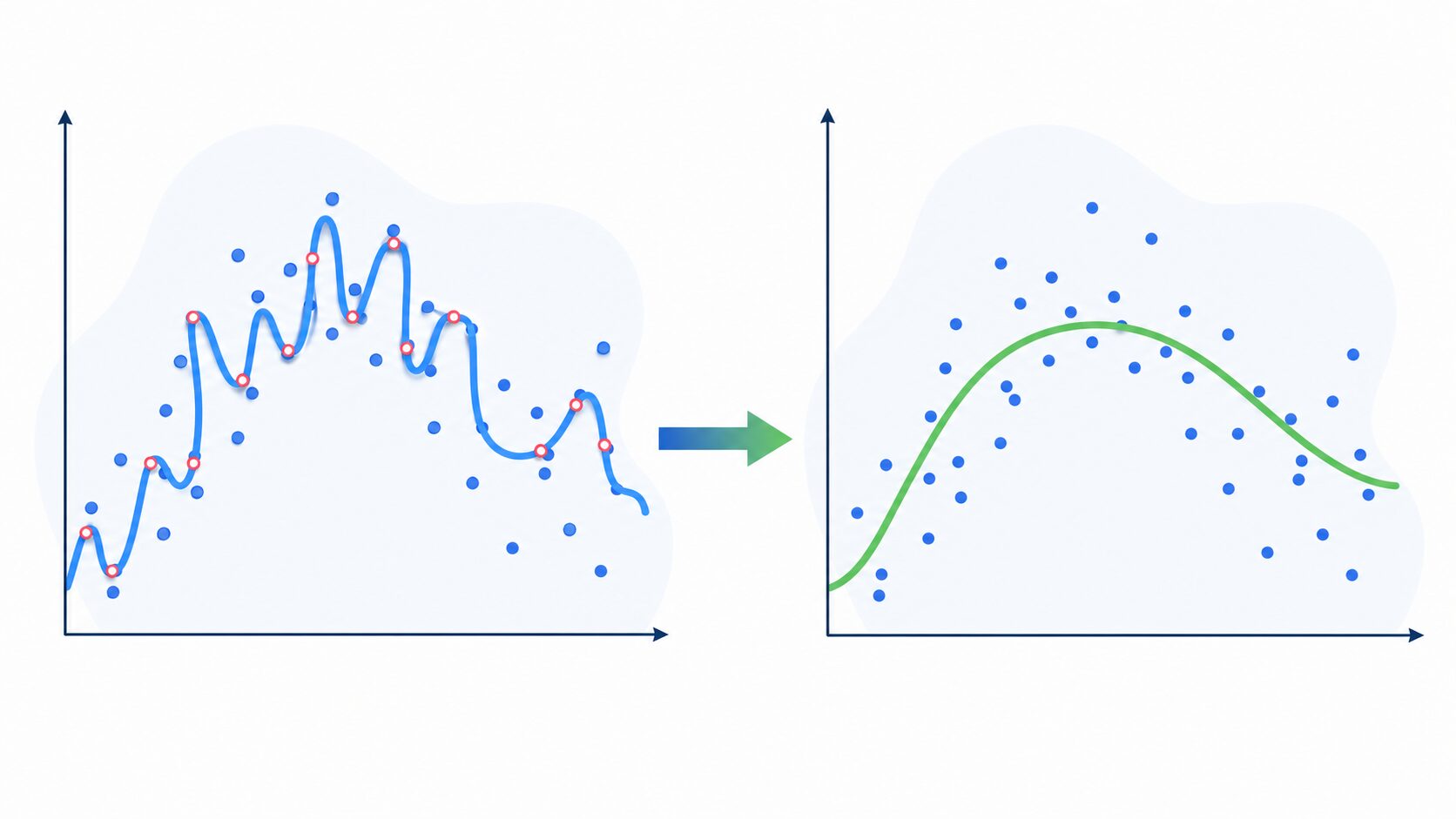
たとえば、散らばった点に曲線を当てはめる場面を考えます。すべての点を無理に通る複雑な曲線は、訓練データにはよく合います。しかし、その点の中に偶然の誤差やノイズが含まれていると、曲線は本来の傾向ではなくノイズまで学習してしまいます。
一方、少しだけ点から外れることを許し、全体の流れを捉える滑らかな曲線にすると、新しいデータに対して安定した予測をしやすくなります。正則化は、この「当てはまりの良さ」と「モデルの単純さ」のバランスを取る技術です。
正則化が抑える主な対象は、モデル内部の重みと呼ばれるパラメータです。重みが極端に大きいと、入力のわずかな変化が予測結果を大きく変えてしまうことがあります。正則化は重みを抑えることで、過敏なモデルになりにくくします。
正則化項と数式の見方
正則化は、モデルが最小化する損失関数に、重みの大きさに応じた追加項を加えることで実現します。この追加項を正則化項と呼びます。
\(\)正則化を含む目的関数は、概念的には次のように表せます。
目的関数 = 損失関数 + λ × 正則化項
ここで損失関数は「予測の外れ具合」、正則化項は「モデルの複雑さ」、λ(ラムダ)は正則化の強さを表します。λが大きいほど、重みを小さくする力が強くなります。
ただし、λを大きくすればよいわけではありません。正則化が強すぎると、モデルは単純になりすぎて、本来学ぶべき傾向まで捉えられません。この状態は学習不足です。反対に、正則化が弱すぎると、モデルは複雑になりすぎて過学習しやすくなります。
L1正則化とL2正則化の違い
正則化にはいくつかの種類がありますが、代表的なのがL1正則化とL2正則化です。どちらも過学習を防ぐために使われますが、重みに対する働き方が異なります。
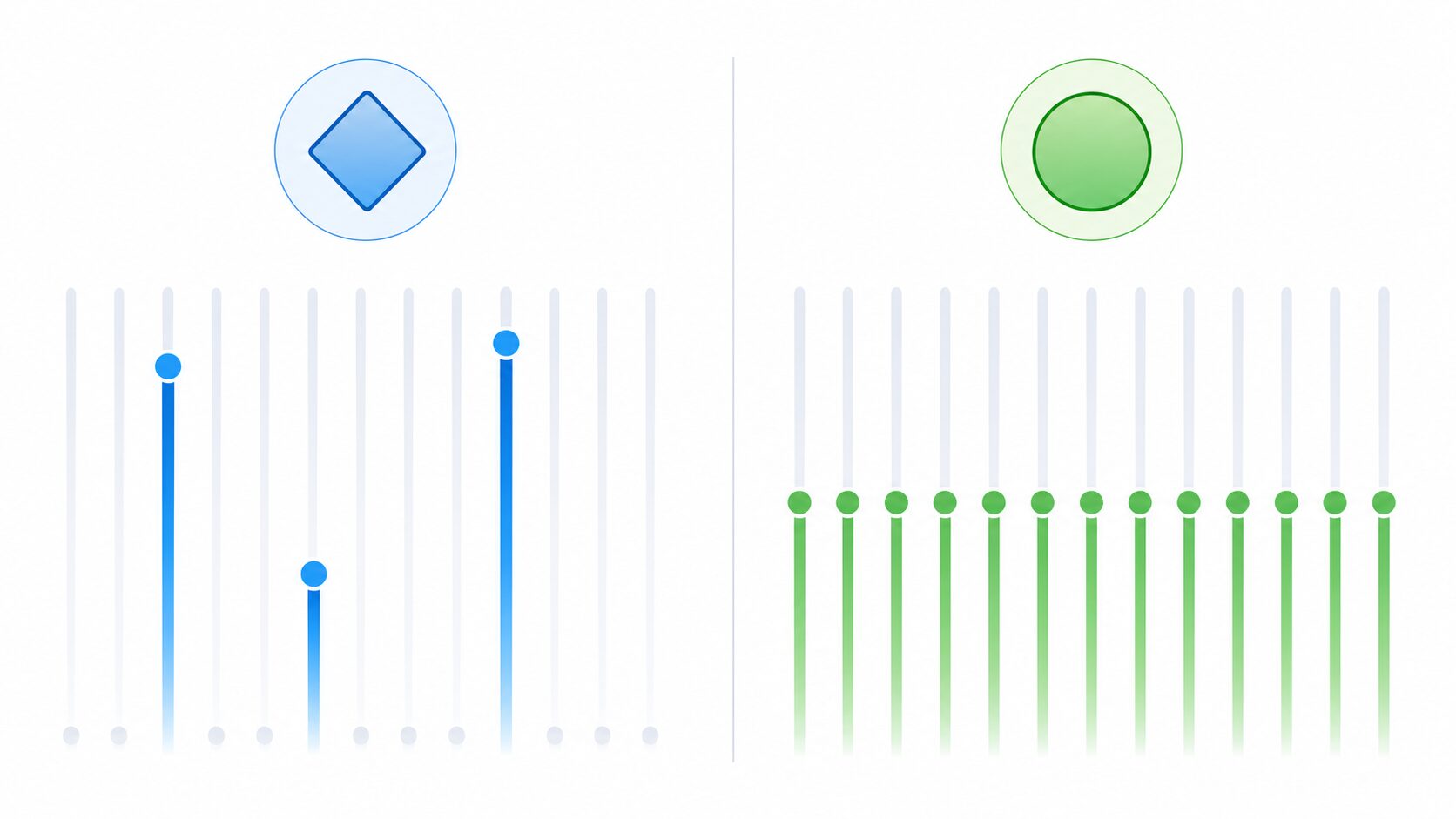
L1正則化は、重みの絶対値の合計を正則化項として加える方法です。特徴量の中に不要なものがある場合、その重みをゼロに近づけやすい性質があります。そのため、重要な特徴量だけを残したいときや、モデルを解釈しやすくしたいときに役立ちます。
L2正則化は、重みの二乗の合計を正則化項として加える方法です。L1のように重みを完全にゼロにするよりも、全体の重みをなだらかに小さくする働きがあります。ノイズの影響を抑え、安定した予測をしたいときによく使われます。
L1正則化とL2正則化は、どちらが常に優れているという関係ではありません。特徴量が多く、その中から有効なものを選びたいならL1、全体的に安定したモデルを作りたいならL2が候補になります。両方の性質を組み合わせたElastic Netという方法もあります。
| 項目 | L1正則化 | L2正則化 |
|---|---|---|
| 正則化項 | 重みの絶対値の合計 | 重みの二乗の合計 |
| 重みへの影響 | 不要な重みをゼロにしやすい | 重み全体を小さくしやすい |
| 主な効果 | 特徴選択、モデルの簡素化 | 過学習の抑制、予測の安定化 |
| 向いている場面 | 多数の特徴量から重要なものを見つけたい場合 | ノイズに強い安定したモデルを作りたい場合 |
正則化はどのモデルで使われるか
正則化は、特定のモデルだけで使う特殊な技術ではありません。線形回帰、ロジスティック回帰、サポートベクターマシン、ニューラルネットワークなど、幅広い機械学習モデルで使われます。
線形回帰では、説明変数が多いと重みが不安定になり、訓練データに強く引っ張られることがあります。L1正則化やL2正則化を使うことで、重みを抑え、予測を安定させることができます。
ニューラルネットワークでは、パラメータ数が非常に多くなるため、過学習が起きやすくなります。L2正則化のほか、ドロップアウトや早期終了なども広い意味で過学習を抑える手法として使われます。
正則化の強さをどう決めるか
正則化の強さは、通常、学習前に人が設定するハイパーパラメータで調整します。大切なのは、訓練データの精度だけで判断しないことです。訓練精度が高くても、検証データでの性能が低ければ過学習している可能性があります。
正則化の強さを決める代表的な方法が交差検証です。データを複数のグループに分け、学習と評価を何度か繰り返すことで、特定の分割に偏らない評価を行います。複数のλを試し、検証性能が最も安定する値を選びます。
正則化が弱すぎると過学習、強すぎると学習不足、適切なら汎化性能の向上につながります。実務では、候補値を広めに試し、検証データでの誤差や評価指標を確認しながら調整します。
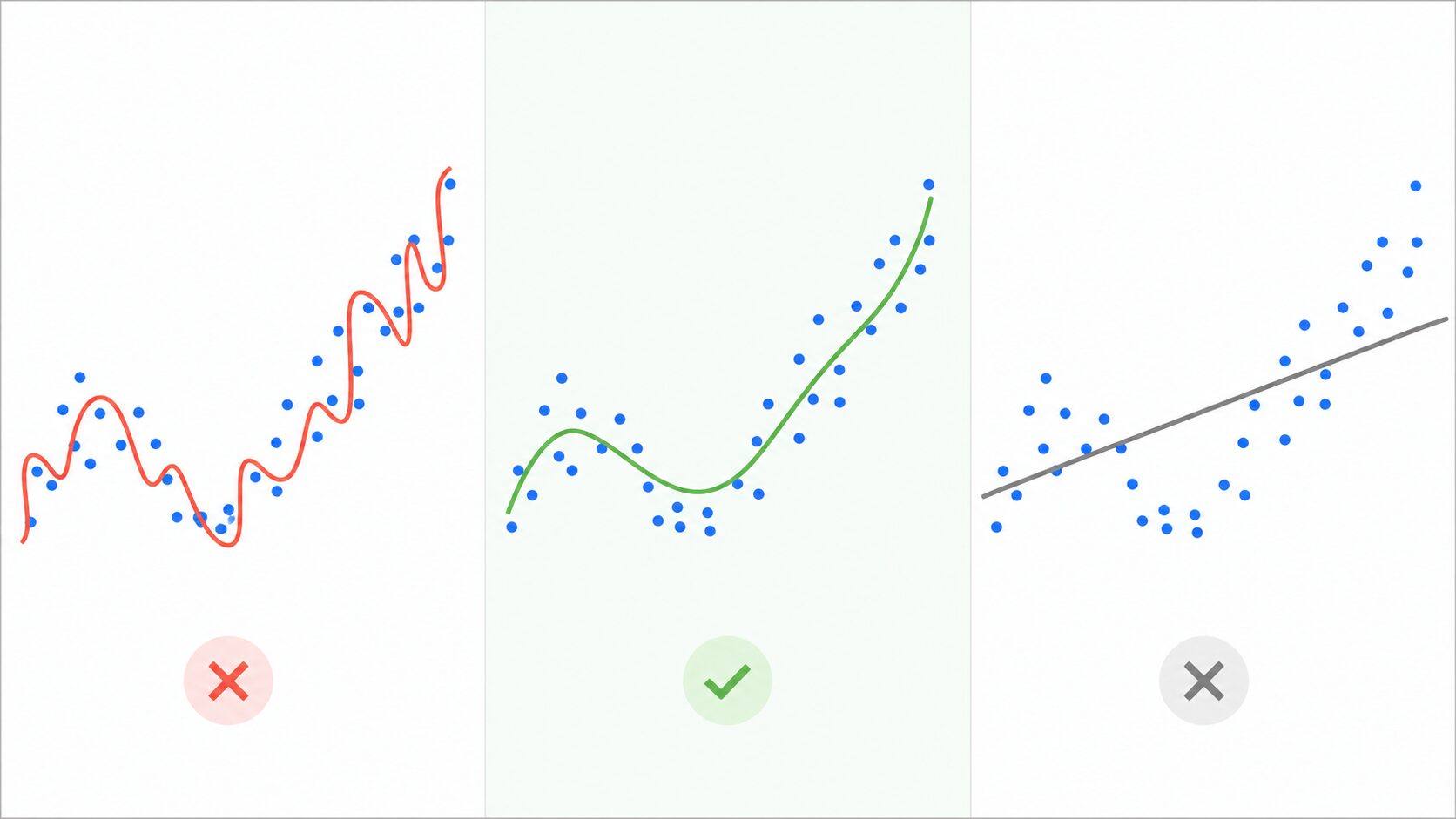
正則化の利点と注意点
正則化の大きな利点は、過学習を抑えて汎化性能を高めやすいことです。訓練データに含まれる偶然の揺らぎやノイズの影響を受けにくくなり、新しいデータに対しても安定した予測が期待できます。
L1正則化には、特徴選択によってモデルを解釈しやすくする利点があります。どの特徴量が予測に効いているのかを知りたい場合、不要な特徴量の重みがゼロに近づくことは有用です。
L2正則化には、重みを全体的に抑えることで数値計算を安定させる利点があります。重みが極端に大きくなると、学習が不安定になったり、入力の小さな変化で予測が大きく変わったりするためです。
一方で、正則化を入れれば必ず性能が上がるわけではありません。データ量、特徴量の質、モデルの種類、評価方法によって効果は変わります。また、特徴量のスケールが大きく異なる場合、正則化の前に標準化などの前処理が必要になることがあります。
正則化と正規化の違い
初心者が混同しやすい言葉に、正則化と正規化があります。名前は似ていますが、目的は異なります。
正則化はモデルの複雑さを抑える手法です。過学習を防ぎ、汎化性能を高めることを目的にします。一方、正規化はデータの尺度をそろえる前処理です。たとえば、年齢と年収のように単位や値の範囲が大きく違う特徴量を、学習しやすいスケールに変換します。
| 項目 | 正則化 | 正規化 |
|---|---|---|
| 目的 | モデルの複雑さを抑える | データの尺度をそろえる |
| 主な効果 | 過学習の抑制、汎化性能の向上 | 学習の安定化、特徴量の比較しやすさ向上 |
| 使う場面 | 損失関数にペナルティを加える | 学習前のデータ前処理で使う |
より深く学ぶための教材
正則化を理解するには、まず過学習、損失関数、重み、汎化性能の関係を押さえることが重要です。そのうえで、L1正則化とL2正則化を数式とコードの両方から確認すると、理解が深まりやすくなります。
基本を学ぶ段階では、書籍、入門記事、解説動画が役立ちます。視覚的に理解したい場合は、点群に曲線を当てはめる例や、L1/L2の違いを図で説明している教材を選ぶとよいでしょう。
実践力を高めたい場合は、線形回帰やロジスティック回帰で正則化係数を変え、訓練データと検証データの性能がどう変わるかを試すのがおすすめです。正則化は理論だけでなく、実際にパラメータを動かして結果を見ることで感覚をつかみやすくなります。

| 学習レベル | 教材 | 学び方 |
|---|---|---|
| 基本 | 入門記事・書籍 | 過学習、損失関数、重みの関係を整理する |
| 基本 | 解説動画 | L1正則化とL2正則化の直感的な違いを確認する |
| 実践 | プログラム例 | 正則化係数を変えて訓練精度と検証精度を比較する |
| 応用 | 深層学習教材 | ニューラルネットワークでの過学習対策と合わせて学ぶ |
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月1日 | 正則化の定義、過学習との関係、L1/L2正則化の違い、正規化との違い、実務上の注意点を初心者向けに再構成 |