自己符号化器の仕組みと応用

AIの初心者
先生、「自動符号化器」って一体何ですか?名前から何となく想像はできるのですが、詳しく教えてください。

AI専門家
そうだね。「自動符号化器」は、データを圧縮して、また元の形に戻すことを学習する仕組みだよ。 例えば、手書きの数字の画像をもっと少ないデータ量で表現して、また元の画像に近いものを復元できるように学習するんだ。
AIの初心者
なるほど。でも、なぜそんなことをする必要があるんですか?
AI専門家
良い質問だね。データの重要な特徴を学習することで、画像のノイズ除去やデータの次元削減といったことに役立つんだよ。 つまり、データの本質を捉えるのに役立つんだ。
AutoEncoderとは。
人工知能に関わる言葉である「自動符号化器」について説明します。自動符号化器は、人の神経の仕組みをまねた、学習を助けるための仕組みの一つで、特に答えを教えることなく学習させる方法で使われます。
自己符号化器とは

自己符号化器とは、自らに符号を与え、それを自ら解き明かす、まるで鏡に映った自身を見つめ直すような学習を行う仕組みです。これは、人工知能の分野で用いられる、人間の脳の神経細胞の繋がりを模したしくみ、すなわち「神経回路網」の一種です。
この神経回路網は、入力された情報をより少ない情報量に圧縮し、その圧縮された情報から元の情報を復元するように学習を行います。例えるなら、たくさんの荷物を小さな箱に詰め込み、後でその箱から元の荷物を取り出すような作業です。この過程で、本当に必要な情報は何なのかを自ら学び取っていきます。
一見、情報を圧縮して復元するという作業は無駄なように思えます。しかし、この「圧縮」と「復元」の繰り返しこそが、データに潜む本質的な特徴を捉える鍵となるのです。たくさんの荷物の中から必要な物だけを選び出すことで、荷物の特徴が明確になるように、データの本質を浮かび上がらせることができます。
自己符号化器は、入力されたデータと同じデータを復元することを目指すため、正解となるデータを別に用意する必要がありません。つまり、データ自身を教師として学習を行う「教師なし学習」に分類されます。これは、膨大な量のデータの中から、人の手で分類や整理を行うことなく、自動的にデータの特徴を抽出できるという利点があります。まるで、たくさんの写真の中から、似た風景の写真を自動的に分類してくれるようなものです。
このように、自己符号化器は、大量のデータの中から本質的な特徴を捉え、様々な応用を可能にする、強力な道具と言えるでしょう。
| 自己符号化器の特性 | 説明 | 例え |
|---|---|---|
| 機能 | 入力情報を圧縮し、その圧縮情報から元の情報を復元する。 | 多くの荷物を小さな箱に詰め込み、後でその箱から元の荷物を取り出す。 |
| 学習方法 | データに潜む本質的な特徴を捉えるために「圧縮」と「復元」を繰り返す。 | 多くの荷物から必要な物だけを選び出すことで、荷物の特徴を明確にする。 |
| 学習の種類 | 入力データと同じデータを復元することを目指す教師なし学習。 | 多くの写真の中から、似た風景の写真を自動的に分類する。 |
| メリット | データ自身を教師として学習できるため、大量のデータから自動的に特徴を抽出できる。 | – |
構造と学習

自己符号化器は、大きく分けて符号化器と復号化器の二つの部分からできています。この二つの部分は、まるで合わせ鏡のように連携して働きます。
まず、符号化器について説明します。符号化器は、入力されたデータを受け取ると、それをより少ない情報量で表現するように圧縮します。たとえば、たくさんの数字の列が与えられたとき、その数字の列が持つ本質的な特徴を抽出して、もっと少ない数の数字で表現するような働きをします。この圧縮された表現は潜在変数と呼ばれ、元のデータの持つ重要な特徴が凝縮されていると考えられます。潜在変数は、データの核となる情報を効率的に表現したものと言えます。
次に、復号化器について説明します。復号化器は、符号化器によって圧縮された潜在変数を受け取ります。そして、その潜在変数をもとに、元のデータに近い形を復元しようとします。これは、少ない情報から元の絵を描き出すような作業に似ています。復号化器がうまく機能すれば、元のデータと復元されたデータは非常に近いものになるはずです。
自己符号化器の学習は、入力データと復号化器が復元したデータの差をできるだけ小さくするように行われます。この差のことを損失関数と呼び、この損失関数の値が小さければ小さいほど、自己符号化器の性能が良いことを示します。損失関数を小さくするために、符号化器と復号化器の中の様々な細かい設定値(パラメータ)が調整されます。
学習が進むにつれて、自己符号化器はデータの特徴を捉える能力が向上していきます。まるで職人が経験を積むことで技術が上達するように、自己符号化器も学習を繰り返すことで、データから重要な特徴を効率的に抽出し、不要な情報を取り除くことができるようになります。これにより、データに含まれる雑音(ノイズ)を減らしたり、データの本質的な特徴を際立たせることができるようになります。
様々な種類

自己符号化器には、データの特性や解析の目的に合わせて様々な種類があります。それぞれの仕組みや得意分野を理解することで、最適な自己符号化器を選ぶことができます。まず、基本となるのは標準的な自己符号化器です。これは、入力されたデータと同じ大きさの出力データを生成するように学習します。入力データの特徴をそのまま捉え、再構築することを目指すため、データの全体像を把握するのに役立ちます。次に、低次元自己符号化器について説明します。これは、入力データよりも少ない情報量で表現するように学習します。膨大なデータの中から本質的な特徴を抽出し、データの次元を削減することで、計算の負担を軽くしたり、データの可視化を容易にしたりできます。また、ノイズ除去自己符号化器は、あえてノイズを加えたデータを入力として学習します。ノイズの影響を受けにくい頑健な特徴表現を学習することで、元のデータに含まれる本質的な情報をより正確に捉えることができます。画像データの生成に特化した変分自己符号化器も存在します。これは、データの確率分布を学習することで、新しい画像データを生成することができます。このように、自己符号化器には様々な種類があり、それぞれ異なる目的や特性を持っています。データの性質や分析の目的に合わせて適切な種類を選択することで、データ解析の精度向上や新たな知見の発見につながります。
| 自己符号化器の種類 | 説明 | 得意分野 |
|---|---|---|
| 標準的な自己符号化器 | 入力データと同じ大きさの出力データを生成。データの特徴をそのまま捉え、再構築。 | データの全体像把握 |
| 低次元自己符号化器 | 入力データよりも少ない情報量で表現。本質的な特徴を抽出し、データの次元を削減。 | 計算の負担軽減、データの可視化 |
| ノイズ除去自己符号化器 | ノイズを加えたデータを入力として学習。ノイズの影響を受けにくい頑健な特徴表現を学習。 | 本質的な情報の正確な把握 |
| 変分自己符号化器 | データの確率分布を学習し、新しい画像データを生成。 | 画像データの生成 |
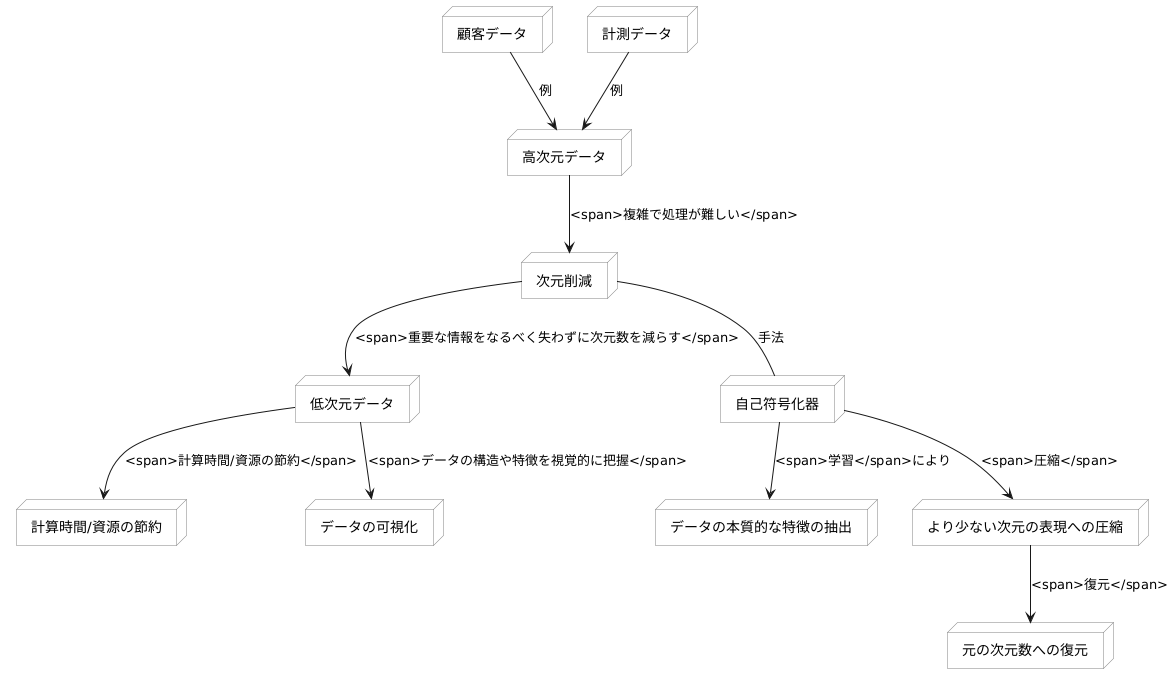
次元削減

多くの情報を持つデータは、複雑で処理が難しいことがあります。例えば、たくさんの項目について情報を持つ顧客データや、多数のセンサーから得られる計測データなどです。このようなデータは、項目やセンサーの数だけデータの広がり、つまり次元を持つことになります。次元数が多いと、計算に時間がかかったり、データの特徴を捉えにくくなるといった問題が生じます。そこで、次元削減という手法が用いられます。次元削減とは、重要な情報をなるべく失わずに、データの次元数を減らす技術のことです。
自己符号化器は、この次元削減を実現する有力な方法の一つです。自己符号化器は、入力されたデータと同じデータを出力するように学習する特別な構造を持つ計算機のようなものです。この学習過程で、データの本質的な特徴を捉える能力を獲得します。自己符号化器は、入力データを一度より少ない次元の表現に圧縮し、その後、元の次元数に戻すようにデータを復元します。この圧縮された表現が、次元削減されたデータとなります。
大量の情報を持つデータを自己符号化器で処理することで、計算にかかる時間や資源を節約できます。例えば、顧客データの次元を削減することで、顧客の分類や予測をより効率的に行うことが可能になります。また、計測データの次元を削減することで、異常値の検出やセンサーの故障予測などが容易になります。さらに、次元削減はデータの可視化にも役立ちます。高次元データはそのままではグラフで表示することができませんが、次元を2次元や3次元に削減することで、データの構造や特徴を視覚的に把握することが可能になります。これにより、データ分析の理解が深まり、新たな発見につながる可能性も高まります。
異常検知

ものづくりやお金のやり取りなど、様々な場面で「いつもと違う」ことを見つける技術は大変重要です。これを「異常検知」と言います。近年、この異常検知をうまく行う方法として「自己符号化器」という技術が注目を集めています。
自己符号化器とは、入力された情報を一度圧縮し、その後元の情報に戻そうとする仕組みのことです。例えるなら、ある文章を短いキーワードにまとめ、そのキーワードから元の文章を復元するようなものです。この自己符号化器を、普段よく見られる正常なデータだけを使って学習させます。たくさんの正常なデータを学習することで、自己符号化器は正常なデータの特徴をうまく捉えられるようになります。
学習が終わった自己符号化器に、新しいデータを入力してみましょう。もしそのデータが、学習に使った正常なデータと似たものであれば、自己符号化器は元のデータをほぼ正確に復元できます。しかし、もし入力されたデータが学習データとは大きく異なる、つまり異常なデータであれば、自己符号化器はうまく復元できません。復元されたデータと元のデータの差が大きいほど、そのデータは異常である可能性が高いと考えられます。この復元の際のずれを「復元誤差」と言い、この誤差を見ることで異常を発見することができます。
例えば、クレジットカードの利用履歴を自己符号化器に学習させたとします。いつもと同じように使っていれば、利用履歴は正常なものとして認識され、復元誤差は小さくなります。しかし、もし盗難に遭い、普段と全く違う場所で高額な商品が購入された場合、自己符号化器はこれをうまく復元できず、大きな復元誤差が生じます。この大きな誤差から、不正利用の可能性が高いと判断できます。
このように、自己符号化器を用いた異常検知は、異常なデータの例を事前に用意しなくても異常を発見できるという点で非常に優れています。特に、異常なデータを集めるのが難しい場合や、どのような異常が起こるか予測できない場合に有効です。ものづくりの不良品検知や、ネットワークの不正アクセス検知など、様々な分野で活用が期待されています。

画像生成

絵を描くように、新しい画像を作り出す技術が近年注目を集めています。この技術は「画像生成」と呼ばれ、様々な方法がありますが、中でも「変分自己符号化器」、略して「ブイエイイー」という手法は、特に優れた成果を上げています。
ブイエイイーは、まるで職人が材料から作品を作り出すように、画像を一度分解し、それから再構築するという仕組みを持っています。この分解と再構築の過程で、「潜在変数」と呼ばれる、いわば設計図のような情報が用いられます。
ブイエイイーの最大の特徴は、この設計図に「確率」という要素を取り入れている点です。従来の手法では、一つの画像に対して一つの設計図しか作れませんでしたが、ブイエイイーでは、同じ画像からでも少しずつ異なる設計図をたくさん作ることができます。これは、職人が同じ材料を使っても、毎回微妙に異なる作品を作り出すことに似ています。
この「確率」の導入により、ブイエイイーは、学習に用いた画像にそっくりなコピーを作るだけでなく、全く新しい画像を生み出すことも可能になりました。例えば、様々な顔の画像を学習させたブイエイイーは、学習データには存在しない新しい顔の画像を生成することができます。これは、まるで画家が様々な人物画を参考にしながら、想像で新しい肖像画を描くようなものです。
こうしたブイエイイーの能力は、様々な分野での活用が期待されています。例えば、ファッションデザイナーが新しい服のデザインを考える際に、ブイエイイーは斬新なアイデアを提供してくれるかもしれません。また、古くなって傷ついた写真の修復や、小さな画像を大きく鮮明にする技術にも応用が可能です。ブイエイイーは、まさに画像生成分野における革新的な技術であり、今後の更なる発展が期待されます。
| 項目 | 説明 |
|---|---|
| 技術名 | 画像生成(変分自己符号化器:VAE) |
| 仕組み | 画像を一度分解し、潜在変数を用いて再構築する。 |
| 最大の特徴 | 潜在変数に確率の要素を取り入れている。 |
| 利点 | 同じ画像からでも少しずつ異なる設計図を複数作成可能。学習データにない全く新しい画像を生成可能。 |
| 応用例 | 新しい服のデザイン、古くなった写真の修復、画像の拡大・鮮明化など。 |