過学習を防ぐ早期終了とは?意味・仕組み・使い方を初心者向けに解説

AIの初心者
「早期終了」ってどういう意味ですか?AIの学習を途中で止めると聞くと、まだ不十分な気がします。

AI専門家
早期終了は、学習を続けすぎてAIが訓練データだけに詳しくなりすぎる前に、ちょうどよいところで学習を止める方法です。試験勉強で、例題だけを丸暗記しすぎると応用問題に弱くなるのに似ています。
AIの初心者
なるほど。では、どのタイミングで止めればよいのでしょうか?
AI専門家
学習に使っていない検証データで性能を確認し、性能がよくならなくなった時点を目安にします。訓練データでは成績が上がっているのに、検証データでは悪くなり始めたら、過学習のサインです。
早期終了とは。
早期終了とは、機械学習モデルの学習中に検証データの性能を監視し、過学習が進む前に学習を止める方法です。
訓練データでは正解できるのに、初めて見るデータではうまく予測できない状態を過学習といいます。早期終了は、この状態を避けるための代表的な過学習対策です。
ポイントは、訓練データだけでなく、学習に使っていない検証データの誤差や精度を見ることです。検証データでの性能が最もよい時点のモデルを採用することで、未知のデータに対応しやすいモデルを目指します。
早期終了とは何か
早期終了とは、機械学習の訓練をあらかじめ決めた最大回数まで必ず続けるのではなく、検証データでの性能を見ながら適切な時点で打ち切る手法です。英語では early stopping と呼ばれます。
機械学習では、モデルに多数の例題を与えてパターンを学ばせます。この例題が訓練データです。学習が進むと、モデルは訓練データに含まれる特徴をうまく捉え、訓練データに対する誤差は小さくなっていきます。
しかし、学習を続ければ続けるほどよいモデルになるとは限りません。訓練データの細かな癖や偶然のノイズまで覚えてしまうと、初めて見るデータへの予測精度が下がります。これが過学習です。
早期終了では、訓練データとは別に用意した検証データを使い、学習途中のモデルを定期的に評価します。検証データでの誤差が下がらなくなったり、精度が伸びなくなったりしたら、そこで学習を止めます。目的は、訓練データにだけ強いモデルではなく、未知のデータにも対応できる汎化性能の高いモデルを作ることです。
過学習の兆候と学習を止めるタイミング

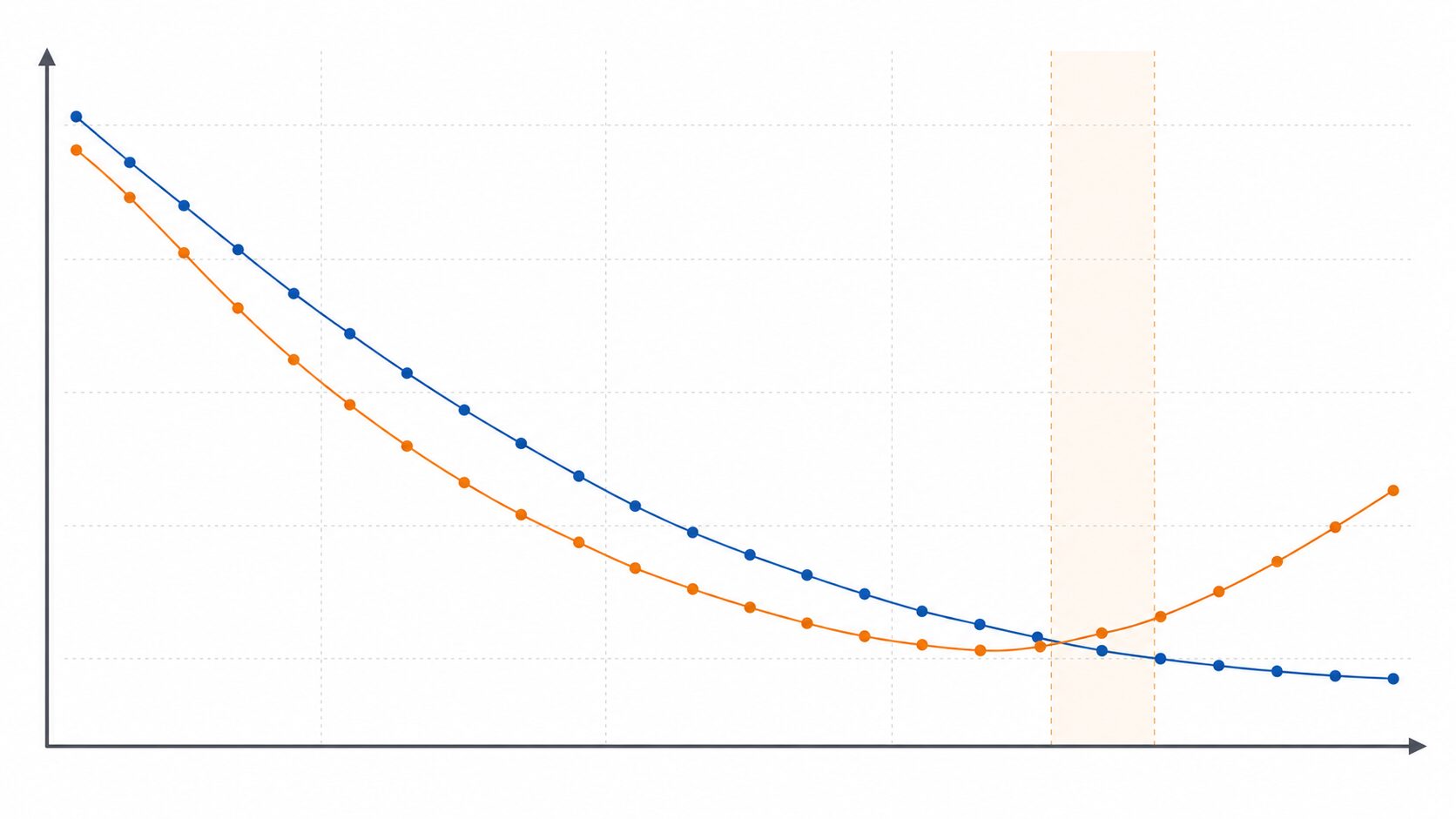
早期終了を理解するには、訓練誤差と検証誤差の違いを押さえる必要があります。訓練誤差は、学習に使ったデータに対する間違いの大きさです。検証誤差は、学習には使っていない検証データに対する間違いの大きさです。
学習の初期段階では、訓練誤差も検証誤差も下がることが多く、モデルが本質的なパターンを学んでいる状態と考えられます。ところが途中から、訓練誤差は下がり続けているのに、検証誤差が横ばいになったり上昇したりすることがあります。この変化が過学習の分かりやすい兆候です。
たとえば、試験勉強で特定の例題を何度も解くと、その例題は完璧に解けるようになります。しかし、例題の数字や表現に依存して覚えてしまうと、少し形が変わった応用問題に対応できません。機械学習でも同じように、訓練データに合わせ込みすぎると、新しいデータへの対応力が落ちます。
| 学習段階 | 訓練誤差 | 検証誤差 | モデルの状態 |
|---|---|---|---|
| 学習初期 | 減少 | 減少 | 基本的な特徴を学び、訓練データにも検証データにも対応しやすくなる |
| 過学習の始まり | 減少 | 横ばいまたは増加 | 訓練データの細部に適合しすぎ、未知データへの性能が落ち始める |
| 早期終了の候補 | 十分に小さい | 最小付近 | 検証データでの性能が最もよく、汎化性能を期待しやすい |
実務では、検証誤差が一度だけ悪化しただけで必ず止めるとは限りません。評価値には揺れがあるため、数回分の様子を見てから止める設定にすることが一般的です。
早期終了の実装方法
早期終了の基本的な流れはシンプルです。まず、データを訓練データと検証データに分けます。次に、学習を進めながら一定の間隔で検証データの性能を確認します。最後に、改善が止まったと判断した時点で学習を終了し、検証性能が最もよかったモデルを採用します。
判断に使う評価指標はタスクによって変わります。分類なら正解率、F1スコア、損失などを使います。回帰なら平均二乗誤差や平均絶対誤差などを使います。重要なのは、訓練データの成績だけで判断しないことです。
多くのライブラリでは、早期終了に忍耐回数という設定があります。これは、検証性能が改善しない状態を何回まで許すかを表す値です。たとえば忍耐回数を5にすると、検証誤差の最小値が5回連続で更新されなかった場合に学習を止める、といった動きになります。
忍耐回数が小さすぎると、まだ学習の途中なのに早く止まりすぎる可能性があります。逆に大きすぎると、過学習が進んでから止まる可能性があります。そのため、データ量、モデルの大きさ、評価値の揺れ方を見ながら調整します。
| 設定項目 | 役割 | 初心者向けの目安 |
|---|---|---|
| 検証データ | 学習中のモデルを公平に確認するためのデータ | 訓練データとは分けて用意する |
| 評価指標 | 改善したかどうかを判断する基準 | 分類なら精度や損失、回帰なら誤差を確認する |
| 忍耐回数 | 改善しない状態を何回待つか | 小さすぎる停止、大きすぎる過学習に注意する |
| 最良モデルの保存 | 検証性能が最もよかった時点の重みを残す | 最後のモデルではなく最良時点のモデルを使う |
早期終了を使う利点
早期終了の最も大きな利点は、過学習を防ぎやすくなることです。訓練データに対する性能だけを追い続けると、モデルは訓練データの細かい癖まで覚えようとします。検証データの性能を見ながら止めることで、未知のデータに対する性能を意識した学習になります。
次に、計算時間を削減できる点も重要です。深層学習のように学習に時間がかかるモデルでは、不要なエポックを減らせるだけで、学習時間や電力、クラウド費用の節約につながります。
さらに、エポック数を手作業で決める負担も軽くなります。あらかじめ大きめの最大エポック数を設定しておき、実際には検証性能が止まったところで終了させれば、必要以上に長く学習させるリスクを下げられます。
| 利点 | 説明 |
|---|---|
| 過学習の防止 | 検証データの性能悪化を手がかりに、訓練データへの合わせ込みすぎを抑える |
| 計算時間の削減 | 改善しない学習を続けないため、学習時間や計算資源を節約できる |
| エポック数調整の効率化 | 最適な学習回数を手作業で探す負担を減らせる |
| 実装しやすい | 多くの機械学習ライブラリで標準的な機能として利用しやすい |
早期終了と正則化の違い・併用
早期終了は、正則化と同じく過学習を防ぐために使われます。ただし、働き方は異なります。早期終了は学習を止めるタイミングを調整する方法です。一方、正則化はモデルが複雑になりすぎないように制約を加える方法です。
代表的な正則化にはL1正則化とL2正則化があります。L1正則化は不要な重みをゼロに近づけ、特徴量を絞り込む効果があります。L2正則化は重みを全体的に小さくし、モデルが極端な値に頼りすぎるのを抑えます。
早期終了と正則化は、どちらか一方だけを使うものではありません。モデルが複雑で過学習しやすい場合は、正則化でモデルの自由度を抑えつつ、早期終了で学習の進みすぎを防ぐと、より安定した結果を得やすくなります。
| 手法 | 主な考え方 | 過学習への効き方 |
|---|---|---|
| 早期終了 | 検証性能を見て学習を止める | 学習しすぎによる性能悪化を防ぐ |
| L1正則化 | 不要な重みをゼロに近づける | モデルを単純化し、重要な特徴に絞りやすくする |
| L2正則化 | 重みを全体的に小さくする | 極端な重みによる合わせ込みを抑える |
| 併用 | モデルの複雑さと学習時間の両方を調整する | より安定した汎化性能を狙いやすい |
早期終了を使うときの注意点
早期終了を使うときは、検証データの扱いに注意が必要です。検証データは、学習中の判断に使うデータです。最終的な性能確認に使うテストデータとは分けておくのが基本です。テストデータを学習停止の判断に使ってしまうと、最終評価が甘くなる可能性があります。
また、検証データが少なすぎると、評価値が偶然に左右されやすくなります。評価が大きく揺れる場合は、忍耐回数を少し大きくする、改善幅の条件を設ける、交差検証を検討するなどの工夫が必要です。
早期終了は便利ですが、すべての問題を自動で解決する魔法の設定ではありません。データの分け方、モデルの大きさ、正則化、学習率、評価指標を合わせて見直すことで、より信頼できるモデルに近づけます。
まとめ
早期終了は、機械学習で過学習を防ぐための基本的で実用的な手法です。訓練データではなく検証データの性能を見ながら、学習を止めるタイミングを決めます。
訓練誤差が下がり続けているのに検証誤差が悪化し始めたら、モデルが訓練データに合わせ込みすぎている可能性があります。その前後で学習を止め、検証性能が最もよかったモデルを採用することで、未知のデータにも対応しやすいモデルを目指せます。
早期終了は、過学習の防止、計算時間の削減、エポック数調整の効率化に役立ちます。正則化と組み合わせることで、さらに安定したモデル学習が期待できます。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年1月31日 | 初回公開 |
| 2026年5月1日 | 早期終了の定義、過学習の兆候、実装手順、正則化との違い、注意点を初心者向けに再構成 |