 アルゴリズム
アルゴリズム 全文検索とベクトル検索のインデックス入門|仕組みと使い分け
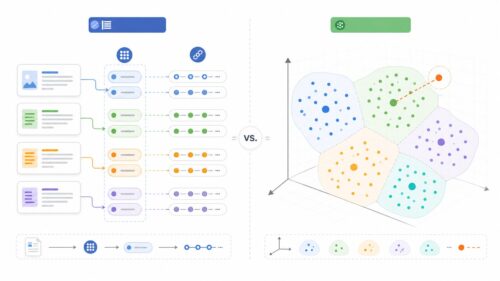
全文検索とベクトル検索のインデックス入門|仕組みと使い分け AIの初心者 AI検索やRAGでは、全文検索とベクトル検索をどう使い分ければよいですか? AI専門家 どちらも検索を速くするためのインデックスですが、対象にするデータが違います。転...
記事数:(46)
アルゴリズム  アルゴリズム
アルゴリズム  セキュリティ
セキュリティ  アルゴリズム
アルゴリズム  セキュリティ
セキュリティ  AI活用
AI活用  AI活用
AI活用  LLM
LLM  LLM
LLM  学習
学習  学習
学習  アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム  セキュリティ
セキュリティ  AIサービス
AIサービス  WEBサービス
WEBサービス  アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム  AIサービス
AIサービス  アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム  学習
学習  AI活用
AI活用