
動画生成AI:Make-a-Videoとは?意味・仕組み・活用例をわかりやすく解説

AIの初心者
「Make-a-Video」は、どんな動画生成AIなんですか?

AI専門家
Make-a-Videoは、文章で指示した内容を短い動画として作る技術だよ。例えば「赤い車が砂漠を走る」と書くと、その場面に近い動画を生成する仕組みなんだ。
AIの初心者
文章だけでなく、写真から動画を作ることもできるんですか?
AI専門家
うん。静止画と文章を組み合わせて、写真の被写体が動いているような動画を作る考え方にもつながっている。現在の動画生成AIを理解するうえで、重要な出発点の一つだね。
Make-a-Videoとは。
Make-a-Videoは、Metaが2022年9月に発表したテキストから動画を生成するAI技術です。文章で場面や動きを指示すると、その内容に合う短い動画を作ることを目指した研究で、画像生成AIから動画生成AIへ発展する流れを示した技術として知られています。
Make-a-Videoとは

Make-a-Videoは、名前の通り「動画を作る」ためのAIです。利用者が「夕焼けの海辺を犬が歩く」「水彩画風の空を鳥が飛ぶ」といったプロンプトを入力すると、AIが言葉の意味を読み取り、場面や動きのある短い映像として出力します。
ここでいうプロンプトとは、AIに対する指示文のことです。画像生成AIではプロンプトから1枚の静止画を作りますが、Make-a-Videoでは時間の流れを持つ複数のフレームを作る点が大きく異なります。単に絵を1枚作るだけでなく、対象がどの方向へ動くのか、背景がどのように変化するのか、前後のフレームで見た目が崩れないかを扱う必要があります。
元記事では「言葉による指示で動画を作る人工知能の先駆け」として紹介されています。現在ではさまざまな動画生成AIが登場していますが、Make-a-Videoは、テキスト・トゥ・イメージの技術を土台に動画へ広げる考え方を示した点で重要です。
| 項目 | 内容 |
|---|---|
| 技術名 | Make-a-Video |
| 発表 | Metaが2022年9月に発表 |
| 主な特徴 | 文章や画像をもとに、動きのある短い動画を生成する |
| 関連技術 | テキスト・トゥ・イメージ、深層学習、動画生成AI |
Make-a-Videoでできること
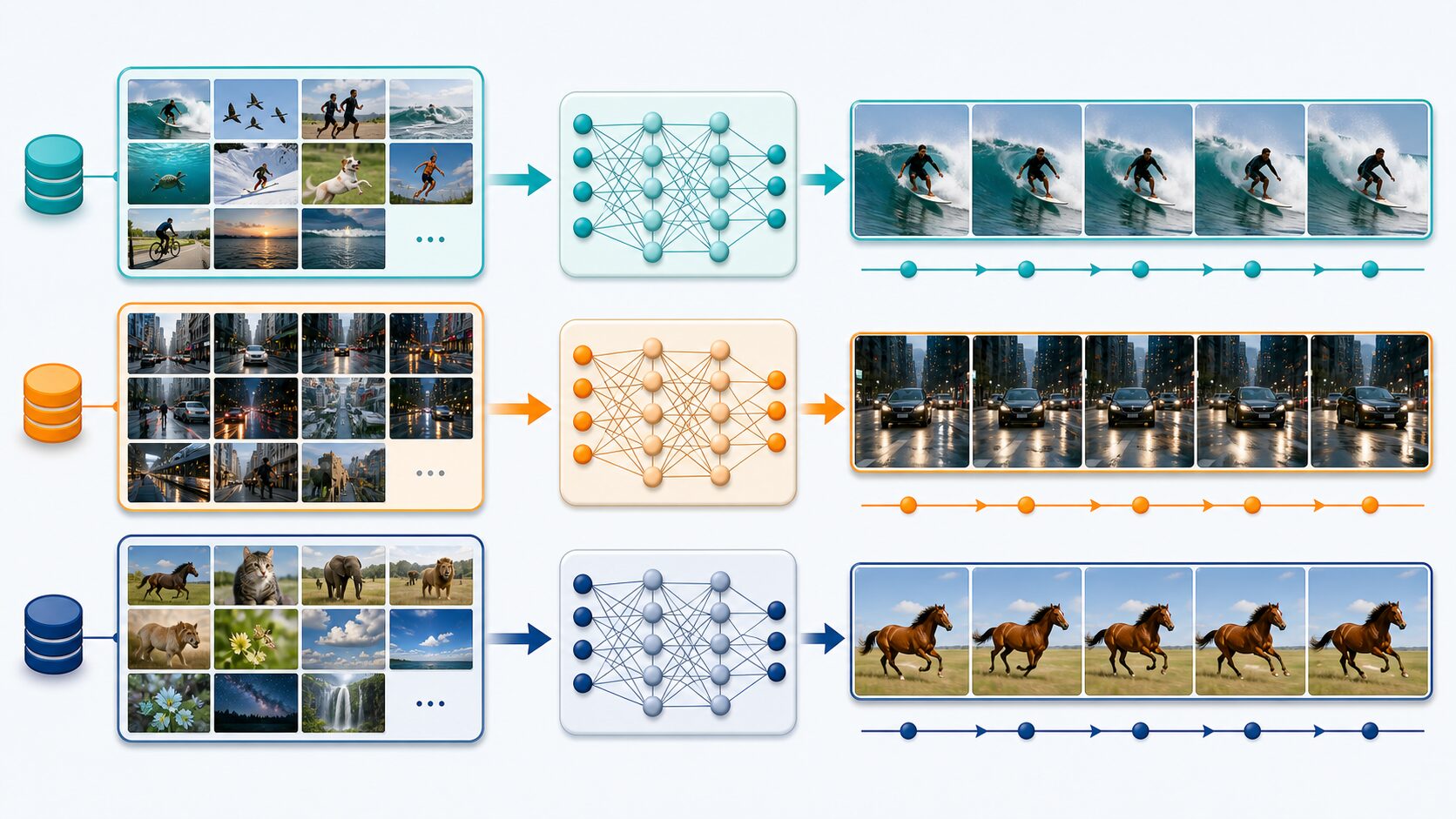
Make-a-Videoの基本は、文章から動画を作ることです。例えば「湖畔を走る犬」「雪の中で回転するロボット」「手描き風の街を通り抜ける自転車」のように、対象、場所、動き、画風を指定すると、それに近い映像を生成するイメージです。
また、元記事にもあるように、静止画と文章を組み合わせる考え方も重要です。猫の写真に「ジャンプする」といった指示を加えると、元の被写体や雰囲気を保ちながら動きを付ける方向に応用できます。これは、商品写真を短い紹介動画にする、イラストを動かして教材に使う、といった実用例につながります。
ただし、初心者が注意したいのは、AIが利用者の意図を完全に理解するわけではない点です。プロンプトが曖昧だと、意図と違う構図や動きになることがあります。動画生成では、静止画よりも「何が、どこで、どのように、どれくらい動くのか」を具体的に書くほど、結果を確認しやすくなります。
テキストから動画を作る仕組み

Make-a-Videoの背景には、大量の画像・動画データと深層学習があります。AIは、画像や動画とそれを説明する言葉の組み合わせを学習し、「犬」「走る」「砂浜」「夕焼け」といった言葉がどのような視覚表現に対応しやすいかを身につけていきます。
動画生成で特に難しいのは、時間的な一貫性です。1枚ずつきれいな画像を作れても、前のフレームでは右にあった物体が次のフレームで突然別の形になると、動画としては不自然に見えます。そのため、動画生成AIでは、物体の位置、形、速度、背景との関係を連続したフレームの中で保つことが重要になります。
例えばボールが跳ねる動画なら、ボールは地面に近づき、接触し、跳ね返り、再び上に移動します。この一連の動きには、時間の順序があります。Make-a-Videoのような技術は、テキストから画像を作る技術に、こうした動きや時間の変化を扱う仕組みを組み合わせて発展してきました。
画像生成AIとの違い
画像生成AIと動画生成AIは似ていますが、求められる処理は同じではありません。画像生成AIは主に「1枚の絵として自然か」を扱います。一方、動画生成AIは「連続する映像として自然か」まで考える必要があります。
そのため、動画生成AIでは、同じ人物や物体がフレームをまたいで同じように見えること、動きが急に破綻しないこと、カメラの視点や光の向きが不自然に変わりすぎないことが重要です。初心者向けに言えば、画像生成AIは写真やイラストを作る技術、動画生成AIは映像の流れごと作る技術と考えると理解しやすいでしょう。
| 比較項目 | 画像生成AI | 動画生成AI |
|---|---|---|
| 出力 | 静止画 | 複数フレームからなる動画 |
| 重視する点 | 構図、画風、被写体の見た目 | 構図に加えて、動き、時間の流れ、一貫性 |
| プロンプトの書き方 | 見た目や雰囲気を中心に指定 | 見た目に加え、動作や変化を具体的に指定 |
活用例と期待される効果
Make-a-Videoのような動画生成AIは、動画制作の入口を広げる技術です。従来の動画制作では、撮影、素材準備、編集、ナレーション、書き出しなど多くの工程が必要でした。動画生成AIを使えば、企画段階のイメージ映像や短い説明動画を、文章から素早く試作できる可能性があります。
教育分野では、歴史上の出来事、科学実験、抽象的な概念を短い動画で見せる使い方が考えられます。広告や商品紹介では、商品の使われ方を説明する短い動画、SNS向けのイメージ映像、キャンペーン案の試作に役立つ可能性があります。個人の創作では、物語の場面を動画化したり、イラストや写真に動きを加えたりする使い方が想定されます。
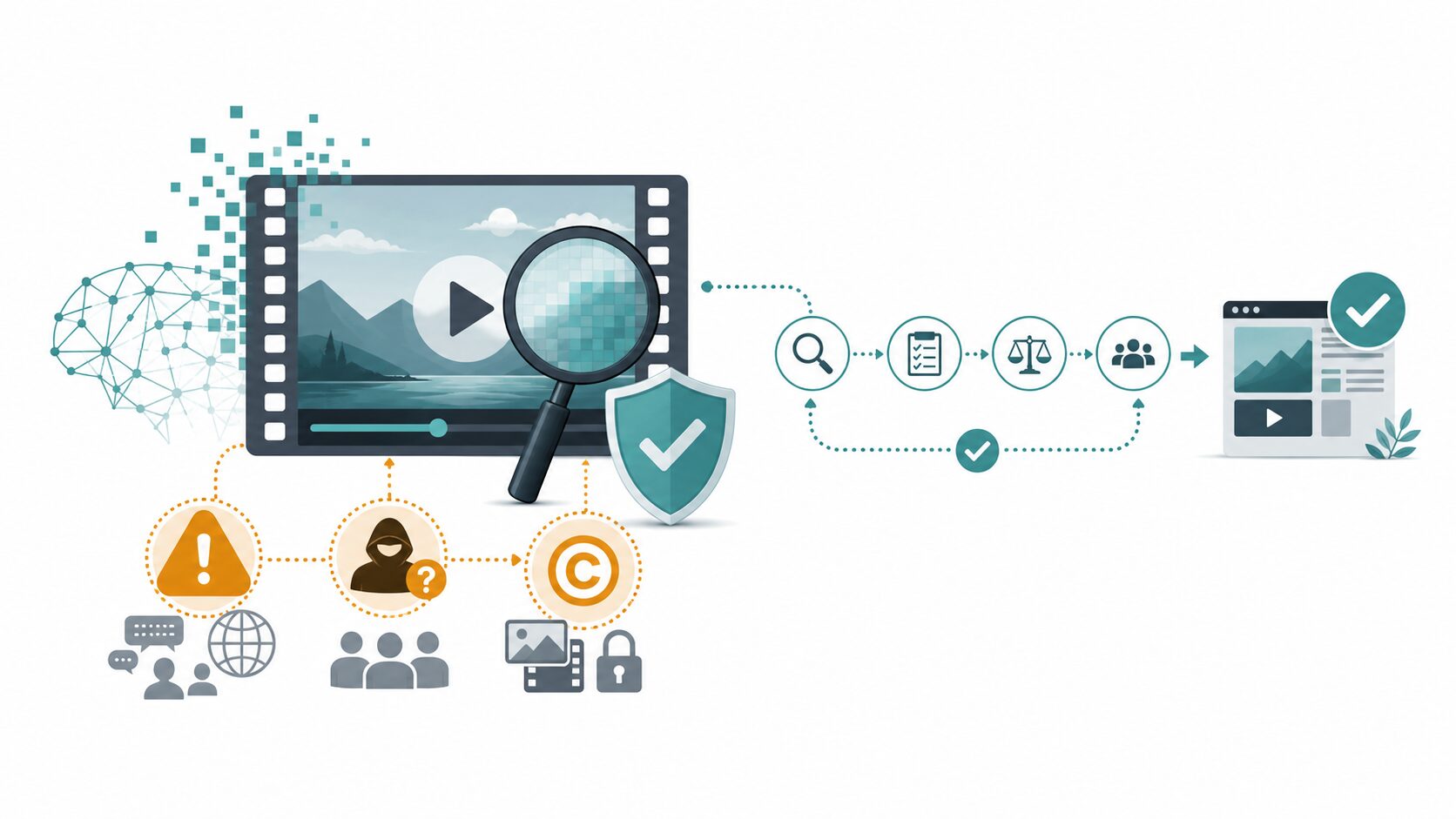
実務では、最初から完成品として使うよりも、絵コンテ、企画共有、アイデア検討、教材の補助素材として使うと効果を確認しやすいでしょう。生成結果には不自然な部分が残る場合があるため、公開前には人が内容、権利、品質を確認する工程が欠かせません。
注意点と倫理的な課題

動画生成AIは便利な一方で、偽情報や権利侵害のリスクもあります。特に映像は、文章や静止画よりも「実際に起きたこと」のように受け取られやすいため、存在しない出来事を本物のように見せる使い方には強い注意が必要です。
著作権や肖像権の問題も重要です。既存の映像作品、特定の人物、企業ロゴ、キャラクターなどを無断で模倣した動画は、権利侵害につながるおそれがあります。AIで生成したから自由に使える、と単純には考えられません。公開や商用利用をする場合は、利用規約、権利関係、素材の出どころを確認する必要があります。
また、生成AIは学習データの偏りやプロンプトの曖昧さによって、不正確な表現を作ることがあります。教育や医療、政治、ニュースに近い内容では、見た目の自然さだけで判断せず、事実確認を別途行うことが大切です。動画生成AIは強力な表現手段ですが、人が責任を持って確認し、使いどころを選ぶ技術として扱うべきです。
| 課題 | 確認したいこと |
|---|---|
| 偽情報 | 実在の出来事のように誤解されないか、説明や文脈を補っているか |
| 著作権 | 既存作品、キャラクター、映像表現を無断で模倣していないか |
| 肖像権・プライバシー | 実在人物に見える表現や個人情報を含んでいないか |
| 品質 | 動きの破綻、誤った描写、不自然な表現が残っていないか |
今後の展望
Make-a-Videoは、動画生成AIの可能性を示した初期の重要な技術です。今後は、より長い動画、より高解像度の映像、音声や音楽との連携、細かな編集指示への対応などが進むと考えられます。文章から動画を一度で作るだけでなく、作った動画を部分的に直す、カメラワークを変える、登場人物の動きを調整するといった編集機能も重要になります。
一方で、技術が進むほど、使う側の判断も重要になります。便利さだけを見て使うのではなく、どの場面で役立つのか、どの場面では人間の制作や確認が必要なのかを分けて考えることが大切です。動画生成AIは、クリエイターを置き換えるだけのものではなく、アイデアを形にする速度を上げ、表現の選択肢を増やす道具として活用されていくでしょう。
Make-a-Videoを理解すると、現在の動画生成AI全体の見方もつかみやすくなります。ポイントは、文章を映像に変換するだけでなく、時間の流れ、動きの自然さ、社会的な影響まで含めて考えることです。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月24日 | 仕組み、活用例、権利面の確認ポイントを補強 |