 学習
学習 エポックとは?機械学習の学習回数と決め方を初心者向けに解説
機械学習とは、多くの情報から規則性を見つけて、次に何が起こるかを予測したり、判断したりする技術です。まるで人間が経験から学ぶように、機械も情報から学習します。この学習の際に、集めた情報を何度も繰り返し機械に読み込ませることで、予測や判断の正確さを上げていきます。この繰り返しの回数を示すのが「エポック」です。
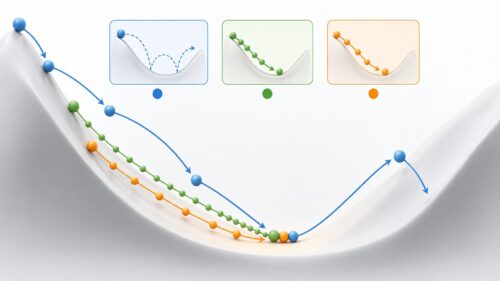
例えるなら、教科書を何度も読むことで内容を理解し、試験で良い点数が取れるようになるのと同じです。一度教科書を読んだだけでは、全ての内容を理解し、覚えることは難しいでしょう。何度も繰り返し読むことで、重要な点や難しい部分が理解できるようになり、最終的には試験で良い点数が取れるようになります。機械学習も同じで、情報を一度学習させただけでは、精度の高い予測や判断はできません。情報を何度も繰り返し学習させる、つまりエポック数を増やすことで、より精度の高いモデルを作ることができます。
このエポックは、機械学習のモデルを作る上で非常に大切な考え方です。エポック数が少なすぎると、モデルが情報を十分に学習できず、予測や判断の精度が低くなってしまいます。これは、教科書を一度しか読まずに試験を受けるようなもので、良い結果は期待できません。反対に、エポック数が多すぎると、モデルが学習用の情報に過剰に適応してしまい、新しい情報に対してうまく対応できなくなることがあります。これは、教科書の内容を丸暗記したものの、応用問題が解けない状態に似ています。
ですから、最適なエポック数を見つけることが重要になります。最適なエポック数は、扱う情報の量や種類、モデルの複雑さなどによって変化します。適切なエポック数を設定することで、モデルの性能を最大限に引き出すことができ、より正確な予測や判断が可能になります。このブログ記事では、後ほどエポック数の適切な設定方法についても詳しく説明していきます。