
訓練誤差とは?意味・過学習との関係・モデル評価での見方を解説

AIの初心者
「訓練誤差」って、学習を続ければ必ず小さくなるものなんですか?

AI専門家
基本的には、学習は訓練データへの予測のずれを小さくするように進むよ。訓練誤差は、練習問題に対する間違いの大きさを見る指標だと考えると分かりやすいね。
AIの初心者
では、訓練誤差が小さければ小さいほど良いモデルなんですか?
AI専門家
そこが大切な点だね。練習問題だけを丸暗記しても、本番の応用問題に強いとは限らない。AIでも訓練データに合わせすぎると、未知のデータへの対応力が下がることがある。これを過学習というんだ。
訓練誤差とは。
訓練誤差とは、機械学習モデルが学習に使ったデータに対して出した予測と、正解とのずれを表す指標です。小さいほど訓練データにはよく合っていますが、それだけで未知のデータにも強いとは判断できません。
訓練誤差とは何か

訓練誤差とは、モデルが訓練データに対してどれくらい間違えたかを数値で表したものです。機械学習では、入力データから答えを予測するモデルを作ります。その予測値と、本来の正解値の差を集計したものが訓練誤差です。
たとえば猫と犬を見分ける画像分類モデルなら、学習に使った画像に対して「猫」「犬」をどれだけ正しく判定できたかを見ます。住宅価格を予測する回帰モデルなら、予測価格と実際の価格のずれを見ます。分類では誤分類率や交差エントロピー、回帰では平均二乗誤差や平均絶対誤差など、目的に応じて誤差の測り方が変わります。
訓練誤差は、学習が進んでいるかを確認する基本的な手がかりです。誤差が大きいままなら、モデルが訓練データの特徴を十分に捉えられていない可能性があります。一方で、訓練誤差だけを追いかけると、モデル評価を誤ることがあります。なぜなら、訓練誤差はあくまで学習に使ったデータ上での成績だからです。
訓練誤差の計算イメージ
訓練誤差の考え方は、予測値と正解値の差を各データで求め、それを全体で平均するイメージです。回帰の例では、次のように平均二乗誤差で表せます。
\( \mathrm{Training\ Error} = \frac{1}{n}\sum_{i=1}^{n}(y_i-\hat{y}_i)^2 \)ここで、\(n\) は訓練データの件数、\(y_i\) は正解値、\(\hat{y}_i\) はモデルの予測値です。差を二乗しているため、大きな外れはより強く評価されます。分類問題では、正解クラスにどれだけ高い確率を置けたかを測る交差エントロピーなどがよく使われます。
重要なのは、誤差の数値そのものを単独で見るのではなく、使っている指標の意味を理解することです。同じモデルでも、平均二乗誤差、平均絶対誤差、誤分類率では見える問題が少しずつ異なります。実務では、予測ミスの影響が大きいケースを重く見るのか、平均的なずれを安定して見たいのかによって指標を選びます。
訓練誤差が小さいほど良いとは限らない

モデル学習では、訓練誤差を小さくすること自体は必要です。しかし、訓練誤差が小さいことと、未知のデータに強いことは同じではありません。訓練データの細かな癖や偶然のノイズまで覚えてしまうと、新しいデータに対する予測が外れやすくなります。
この状態を過学習と呼びます。試験勉強で言えば、練習問題の答えだけを丸暗記して、少し形の違う問題に対応できない状態です。モデルは訓練データには非常によく合っているため、訓練誤差は小さく見えます。しかし、検証データや本番データでは誤差が大きくなります。
過学習が起きやすいのは、モデルが複雑すぎる、データ量が少ない、ノイズの多いデータをそのまま使っている、特徴量が多すぎるといった場合です。訓練誤差が順調に下がっていると良く見えますが、同時に検証誤差が上がり始めていないかを確認する必要があります。
検証誤差との違いとモデル評価
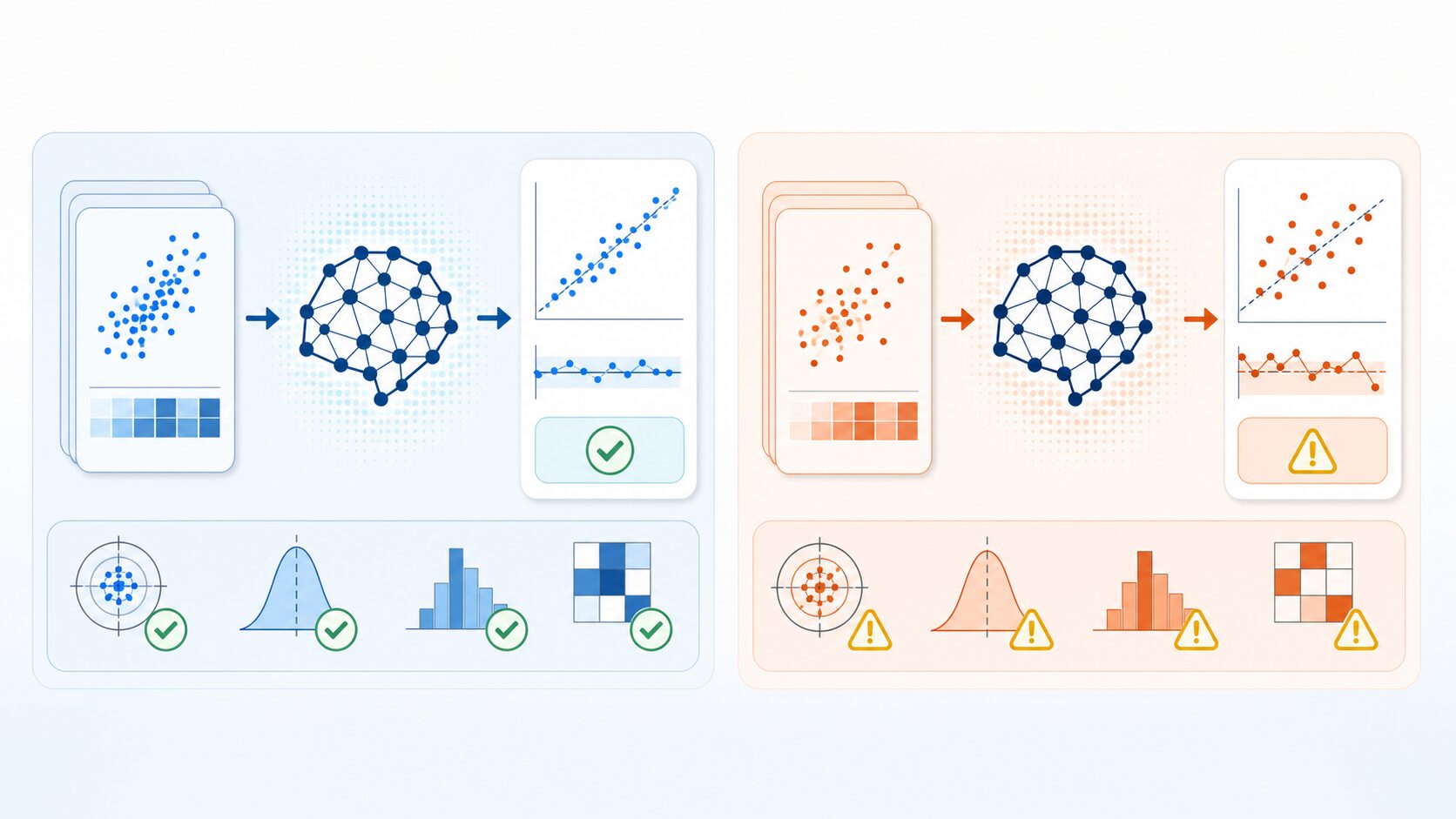
検証誤差とは、学習には使っていない検証データに対する予測のずれです。訓練誤差が「練習問題の成績」なら、検証誤差は「初見問題に近い確認テストの成績」です。モデルの目的は訓練データに当てることではなく、まだ見ていないデータにも使える規則性を学ぶことにあります。
そのため、モデル評価では訓練誤差と検証誤差を並べて見ます。代表的な見方は次の通りです。
| 訓練誤差 | 検証誤差 | 状態 | 考えられる対応 |
|---|---|---|---|
| 小さい | 小さい | 訓練データから汎化しやすい規則性を学べている | 本番条件に近いテストデータでも確認する |
| 小さい | 大きい | 過学習の可能性が高い | 正則化、早期停止、データ追加、モデル単純化を検討する |
| 大きい | 大きい | 学習不足またはモデルが単純すぎる可能性がある | 特徴量、モデル構造、学習量、データ品質を見直す |
限られたデータで安定した評価をしたい場合は、交差検証も有効です。データを複数のグループに分け、学習用と検証用を入れ替えながら性能を測ることで、たまたま分け方が良かった、悪かったという偏りを減らせます。
学習曲線で何を見るか
学習曲線は、学習の進行やデータ量の変化に対して、訓練誤差と検証誤差がどう動くかを示すグラフです。訓練誤差だけを単独で見るよりも、2つの誤差の差と変化の方向が分かりやすくなります。
学習初期やデータが少ない段階では、モデルが少数の例をすぐ覚え込むため、訓練誤差は低く見えることがあります。しかし検証誤差が高いままなら、未知データに通用する特徴を十分に学べていません。データ量を増やしたり、モデルの制約を調整したりすると、検証誤差が下がり、訓練誤差との差が縮まることがあります。
反対に、学習を続けるほど訓練誤差だけが下がり、検証誤差が途中から上がる場合は、過学習が進んでいるサインです。このような場合は、検証誤差が悪化し始める前に学習を止める早期停止や、モデルの自由度を抑える正則化が候補になります。
実務で訓練誤差を活用するポイント

実務で訓練誤差を見る目的は、単に数値を下げることではありません。モデルが何を学べていて、どこで失敗しているかを判断するために使います。訓練誤差が高いなら、入力特徴量が不足している、モデルが単純すぎる、学習が足りない、データのラベルに問題があるといった原因を疑います。
訓練誤差が低いのに検証誤差が高い場合は、過学習対策を考えます。代表的な対策には、学習データを増やす、データ拡張を行う、正則化を強める、モデルを単純化する、特徴量を整理する、早期停止を使う、といった方法があります。どの対策が効くかは、データの性質とモデルの種類によって変わります。
また、訓練誤差は本番で重要な評価指標と必ず一致するとは限りません。たとえば不正検知では、全体の正解率よりも見逃しを減らすことが重視される場合があります。医療、金融、品質検査などでは、誤差の平均値だけでなく、どの種類のミスが危険なのかも合わせて確認する必要があります。
訓練誤差を見るときの注意点
訓練誤差を見るときにまず避けたいのは、訓練データと評価データを混ぜてしまうことです。検証に使うはずのデータが学習に入り込むと、検証誤差まで不自然に小さくなり、モデルの実力を過大評価します。このような問題はデータ漏洩と呼ばれます。
次に、誤差指標の選び方にも注意が必要です。外れ値に敏感な指標を使うと、一部の極端なデータに評価が引っ張られます。逆に、平均的な誤差だけを見ると、重要な少数ケースでの失敗を見落とすことがあります。分類問題では、データの偏りが大きいと正解率だけでは判断しにくいため、適合率、再現率、F値なども検討します。
最後に、訓練誤差はモデル改善の出発点であり、最終判断ではありません。検証誤差、テストデータでの評価、本番に近い条件での確認を組み合わせることで、機械学習モデルの汎化性能をより正しく見積もれます。
まとめ
訓練誤差は、機械学習モデルが訓練データに対してどれくらい正しく予測できているかを示す基本指標です。学習の進み具合を確認するうえで欠かせませんが、訓練誤差が小さいだけでは良いモデルとは判断できません。
重要なのは、訓練誤差と検証誤差を合わせて見て、過学習や学習不足の兆候を読み取ることです。学習曲線、交差検証、誤差指標の選び方も組み合わせれば、モデルが単に訓練データを覚えただけなのか、未知のデータにも使える規則性を学んだのかを判断しやすくなります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年1月31日 | 初回公開 |
| 2026年6月20日 | 過学習との関係、評価指標、実務での見方を補強 |