AI活用
AI活用 AI規制とは?必要性・課題・生成AIへの対応を初心者向けに解説
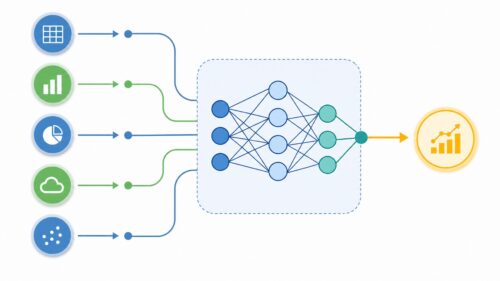
近頃、人工知能は驚くほどの進歩を遂げ、私たちの暮らしの様々な場面で見かけるようになりました。例えば、車を自動で走らせる技術や、病気の診断を助ける技術、お客さまへのサービスなど、様々な分野で使われており、社会を大きく変える力を持っています。
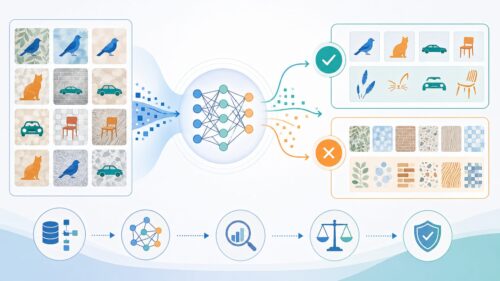
しかし、人工知能の進化は良いことばかりではありません。いくつかの問題も出てきています。例えば、人工知能がどのように判断しているのかが分かりにくいことや、その判断が本当に公平なのかどうか、個人の情報をきちんと守れるのか、そして誰かが悪いことに使ったり、間違った使い方をしたりする危険性など、解決しなければならない課題がたくさんあります。
だからこそ、人工知能が正しく発展し、安全に社会で使われるように、適切なルール作りが必要なのです。人工知能の良い点を最大限に活かし、危険な点を最小限に抑えるためには、技術の進歩に合わせて、柔軟で効果的なルールが必要です。
人工知能の開発者、利用者、そして社会全体で、この重要な課題について理解を深め、共に考えていく必要があります。例えば、どのような情報を人工知能に学習させるのか、どのようにその判断過程を分かりやすく説明するのか、そしてもしも問題が起きた場合、誰が責任を取るのかなど、様々な点を議論し、ルール作りに反映させることが大切です。また、技術は常に進化しているので、ルールもそれに合わせて変えていく必要があります。
人工知能は、私たちの未来をより良くする大きな可能性を秘めています。しかし、その力を正しく使い、安全を確保するためには、継続的な議論と適切なルール作りが欠かせません。私たちは皆で協力し、人工知能と共存できる社会を築いていく必要があるのです。