GBDTとは?勾配ブースティング決定木の仕組み・使いどころ・注意点

AIの初心者
機械学習の説明でGBDTという言葉を見かけました。決定木の仲間だとは思うのですが、何がすごいのでしょうか?

AI専門家
GBDTは、弱い決定木を順番に足しながら予測の誤差を小さくしていく手法です。表形式のデータで強く、実務でもよく使われます。
AIの初心者
ランダムフォレストや普通の決定木とは違うのですか?名前が似ていて混乱します。
AI専門家
違いは「木をどう増やすか」にあります。この記事では、GBDTの定義、仕組み、使いどころ、関連手法との違い、学ぶときの注意点を順番に整理します。
GBDTとは。
GBDTとは、Gradient Boosting Decision Treesの略で、日本語では勾配ブースティング決定木と呼ばれる機械学習アルゴリズムです。複数の小さな決定木を順番に学習し、前のモデルが外した部分を次のモデルが補うことで、分類や回帰の予測精度を高めます。
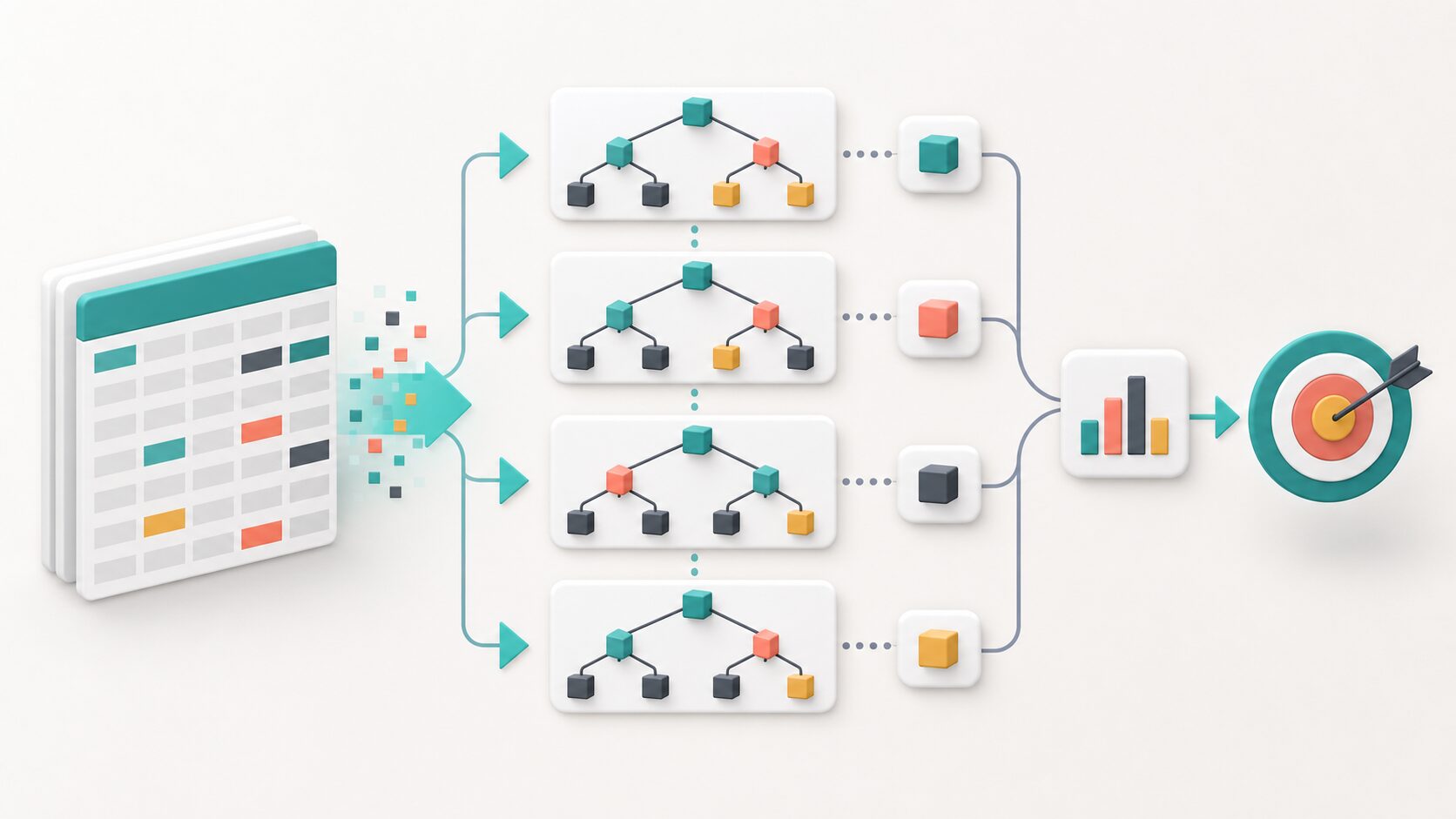
GBDTは、AIや機械学習の学習を進めるとかなり早い段階で出会う重要な用語です。特に、顧客属性、購買履歴、アクセスログ、センサー値、アンケート結果、金融取引のような表形式のデータを扱う場面では、ニューラルネットワークよりもGBDT系のモデルが堅実な選択肢になることがあります。
一方で、名前だけを見ると難しく感じます。「Gradient」は勾配、「Boosting」はブースティング、「Decision Trees」は決定木です。単語を直訳しても、なぜそれで予測精度が上がるのかはすぐには分かりません。そこでこの記事では、数式の暗記ではなく、GBDTが何をしているのか、どのようなデータに向いているのか、どのような点で失敗しやすいのかを、初心者が実務や学習に使える粒度で説明します。
GBDTを一言でいうと、誤差を順番に直す決定木のチーム
GBDTを一言で表すなら、小さな決定木を順番に作り、前の予測の間違いを後の木が少しずつ修正する方法です。1本の決定木だけで複雑な判断をさせると、学習データに合わせすぎたり、逆に単純すぎて大事な傾向を拾えなかったりします。GBDTでは、1本ずつの木をあえて比較的弱いモデルとして作り、それらを積み重ねることで全体として強いモデルにします。
たとえば、あるECサイトで「この利用者が来月も購入するか」を予測したいとします。最初の木は、過去の購入回数や最終購入日から大まかに予測します。しかし、最初の木だけでは「購入回数は少ないが、最近高額商品を見ている利用者」や「セール時だけ購入する利用者」などをうまく扱えないかもしれません。次の木は、最初の木が外した利用者の傾向に注目します。さらに次の木は、まだ残っている外れ方に注目します。このように、予測のズレを段階的に減らしていく考え方がGBDTの中心です。
ここで大切なのは、GBDTが「たくさんの木を作る」だけの手法ではないことです。木を並べる順番、どの誤差を次に直すか、どれくらい強く修正するかが重要です。そのため、ランダムに木をたくさん作って平均するランダムフォレストとは、似ているようで学習の思想が異なります。
Gradient Boosting Decision Treesという名前の意味
GBDTの正式名称であるGradient Boosting Decision Treesは、3つの要素に分けると理解しやすくなります。Decision Treesは決定木です。条件分岐を使ってデータを分け、最後に予測値やクラスを出すモデルです。Boostingは、弱いモデルを組み合わせて強いモデルを作る考え方です。Gradientは、損失関数を小さくする方向、つまり予測を改善する方向を使って次のモデルを学習することを表します。
機械学習では、モデルの良し悪しを「損失」で測ります。回帰なら予測値と正解値の差、分類なら正しいクラスにどれだけ確信を持てたかなどが損失に関係します。GBDTは、今のモデルがどの方向に予測を修正すれば損失が減るかを見ながら、次の決定木を追加します。この「改善方向」を手がかりにするため、Gradientという言葉が入っています。
ただし、初心者の段階では、勾配という言葉を高度な微分計算としてだけ捉える必要はありません。まずは「今の予測の外れ方を見て、次の木がその外れ方を減らす」と理解すれば十分です。細かい数式は、分類、回帰、損失関数、最適化の学習が進んでから深掘りすると、無理なく理解できます。
GBDTの仕組み:最初の予測から少しずつ改善する
GBDTの学習は、いきなり完成度の高い大きな木を作るのではなく、段階的に進みます。まず、全データに対して単純な初期予測を置きます。回帰であれば平均値、二値分類であれば全体の陽性率のようなものを出発点にできます。次に、その初期予測がどのデータでどのように外れているかを計算します。そして、その外れ方を説明する小さな決定木を作ります。
この小さな木を追加すると、予測は少し改善されます。しかし、1本追加しただけで完全になるわけではありません。そこで、改善後の予測に対して再び誤差を見ます。まだ外れている部分を次の木が補います。この処理を繰り返すことで、全体の予測が徐々に正解に近づきます。
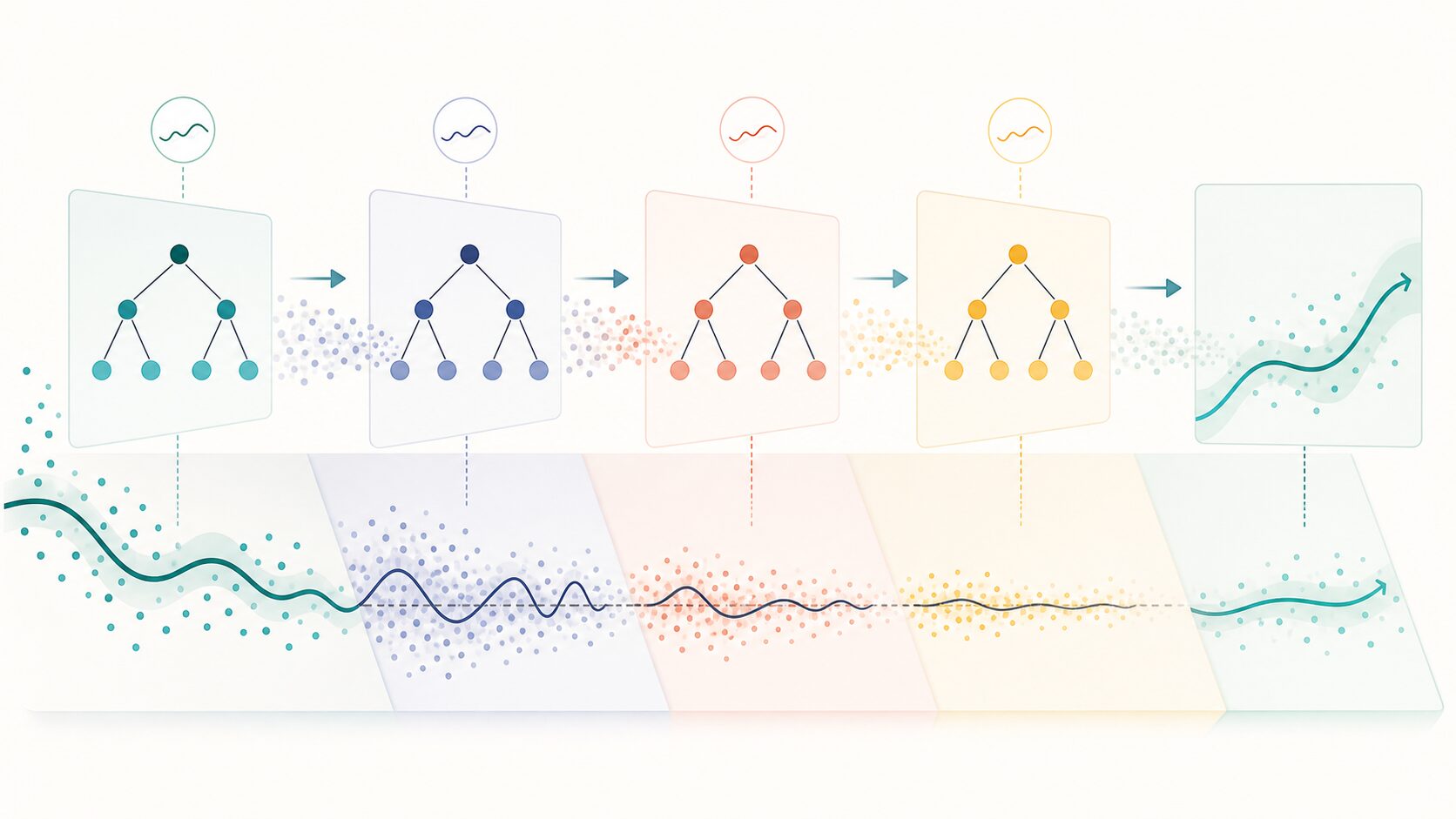
この仕組みを理解すると、GBDTのパラメータの意味も見えやすくなります。木の本数は、修正を何回重ねるかに関係します。学習率は、1本の木による修正をどれくらい控えめに反映するかに関係します。木の深さは、1本の木がどれくらい複雑な条件分岐を覚えられるかに関係します。つまり、GBDTのチューニングは、単に数字を大きくする作業ではなく、少しずつ直す力と、覚えすぎを防ぐ力のバランス調整です。
なぜ表データでGBDTが強いのか
GBDTが実務でよく使われる大きな理由は、表データに強いことです。表データとは、行がサンプル、列が特徴量になっているデータです。たとえば、顧客IDごとに年齢、居住地域、購入回数、平均購入金額、最終ログイン日、問い合わせ回数などが並ぶデータです。企業や行政、研究現場の多くの予測問題は、この形で整理されます。
表データでは、特徴量同士の関係が単純な直線ではないことがよくあります。年齢が高いほど購入率が上がる、という単純な関係だけではなく、「過去購入回数が一定以上で、かつ最終購入日が近く、さらに特定カテゴリの閲覧が多い場合に購入率が上がる」というような組み合わせが効くことがあります。決定木は条件分岐によって、このような非線形な関係や特徴量の組み合わせを扱いやすいモデルです。
また、GBDTは特徴量のスケールに比較的強いという利点があります。線形モデルやニューラルネットワークでは、特徴量の標準化や正規化が重要になる場面が多いですが、決定木ベースのモデルは「ある値より大きいか、小さいか」という分岐を使うため、単位が異なる特徴量をそのまま扱いやすい傾向があります。もちろん前処理が不要という意味ではありませんが、表データ分析の出発点として扱いやすいのは大きな魅力です。
さらに、GBDT系の実装では欠損値やカテゴリ変数への対応が工夫されているものもあります。LightGBMやCatBoostなどは、実務でありがちな不完全なデータに対して使いやすい機能を備えています。ただし、実装によって扱いは異なるため、「GBDTだから何でも自動でうまくいく」と考えるのは危険です。データの意味、欠損の理由、カテゴリの粒度は必ず確認する必要があります。
決定木・ランダムフォレスト・GBDTの違い
GBDTを理解するには、単体の決定木とランダムフォレストとの違いを押さえると整理しやすくなります。3つとも木構造を使いますが、モデルの作り方と予測の安定性が異なります。
| 手法 | 基本的な考え方 | 強み | 注意点 |
|---|---|---|---|
| 決定木 | 条件分岐を1本の木として作る | 構造が分かりやすく説明しやすい | 深くすると過学習しやすい |
| ランダムフォレスト | 複数の木を並列に作り、平均や多数決を取る | 単体の木より安定しやすい | 細かな誤差修正より分散低減が中心 |
| GBDT | 複数の木を順番に作り、前の誤差を補う | 表データで高い精度を出しやすい | 学習率や木の深さの調整が重要 |
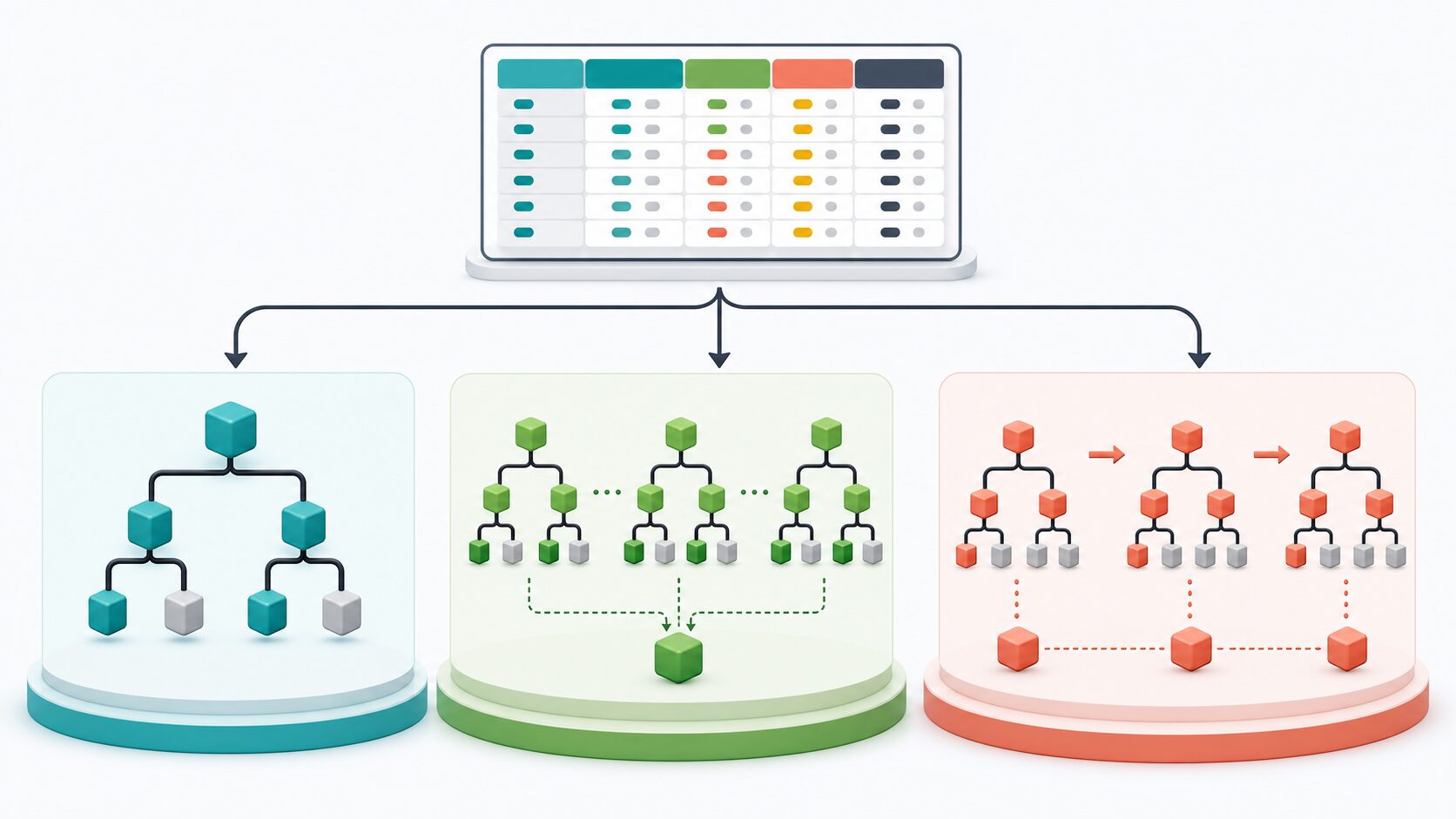
単体の決定木は説明しやすい反面、データの少しの違いで構造が大きく変わることがあります。ランダムフォレストは、さまざまな木を並列に作って平均することで、1本の木の不安定さを減らします。GBDTは、並列ではなく順番に木を作り、前の木で残った誤差を次の木が狙って補います。
この違いは、学習の失敗パターンにも影響します。ランダムフォレストは比較的扱いやすく、初期設定でも安定した結果が得られることが多いです。GBDTは高い精度を狙える一方で、木を増やしすぎたり、1本あたりの木を深くしすぎたり、学習率を大きくしすぎたりすると、学習データに合わせすぎることがあります。つまりGBDTは、強力な分だけ検証の設計が重要です。
線形モデルやニューラルネットワークとの使い分け
GBDTは万能ではありません。線形モデル、ニューラルネットワーク、GBDTは、それぞれ得意なデータや目的が異なります。線形モデルは、特徴量と目的変数の関係が比較的単純で、説明性や係数の解釈を重視する場面に向いています。ニューラルネットワークは、画像、音声、自然言語のように、データから複雑な表現を学習する必要がある場面で強みを発揮します。
一方、GBDTは、すでに列として整理された特徴量から予測したい場面に向いています。売上予測、離反予測、信用リスク、広告クリック率、需要予測、スコアリングなどでは、表データをうまく作ることができれば、GBDTが非常に強いベースラインになります。実務では、まず線形モデルで単純な基準を作り、次にGBDTで非線形な関係を拾い、必要に応じて深層学習やアンサンブルへ進む、という流れもよくあります。
ただし、画像そのものや文章そのものを入力する場合、GBDTだけでは生データの表現を学ぶのが苦手です。そのような場合は、ニューラルネットワークで特徴を抽出し、その特徴量をGBDTに渡す、あるいは最初から深層学習モデルを使う、という設計が考えられます。重要なのは、アルゴリズム名だけで選ぶのではなく、データの形と課題の性質から選ぶことです。
実務での使いどころ
GBDTは、実務の予測タスクで幅広く使われます。代表的なのは、分類と回帰です。分類では、ユーザーが解約するか、問い合わせが重大化するか、取引が不正か、広告がクリックされるかなどを予測します。回帰では、来月の売上、商品の需要、配送にかかる時間、設備の残り寿命など、連続的な数値を予測します。
GBDTが特に活躍しやすいのは、データが表として整っており、特徴量に業務上の意味がある場合です。たとえば、顧客の契約期間、利用頻度、サポート履歴、料金プラン、最近の行動変化などがある場合、それぞれの列は予測に役立つ可能性があります。GBDTは、こうした列の単独効果だけでなく、複数列の組み合わせによる効果も拾いやすいモデルです。

実務で使うときは、モデルそのものよりもデータ設計が成果を左右します。何を予測するのか、いつの時点で使える情報だけを特徴量にするのか、予測結果を誰がどのように使うのかを先に決める必要があります。たとえば解約予測なら、「翌月に解約するか」を予測するのか、「90日以内に解約するか」を予測するのかで、正解ラベルも特徴量の作り方も変わります。
また、GBDTの出力は意思決定の材料であって、意思決定そのものではありません。高リスクと予測された顧客に何をするのか、予測が外れたときの影響は何か、モデルが特定の属性に偏った判断をしていないか、といった運用上の検討も必要です。精度指標だけを見て導入すると、現場で使えないモデルになることがあります。
代表的なGBDT系ライブラリ
実際にGBDTを使うとき、多くの場合は自分でアルゴリズムを一から実装するのではなく、既存のライブラリを使います。代表的なものに、XGBoost、LightGBM、CatBoost、scikit-learnのGradientBoosting系モデルやHistGradientBoosting系モデルがあります。
| ライブラリ | 特徴 | 向いている場面 |
|---|---|---|
| XGBoost | GBDT系の代表的な実装で、性能と実績が豊富 | 幅広い表データタスク、コンペ、実務検証 |
| LightGBM | 高速で大規模データに強い設計 | 行数や特徴量が多い表データ |
| CatBoost | カテゴリ変数の扱いに工夫がある | カテゴリ列が多い業務データ |
| scikit-learn | Pythonの学習・検証ワークフローに組み込みやすい | 基礎学習、比較実験、小中規模の検証 |
初心者が学ぶ場合は、まずscikit-learnで決定木、ランダムフォレスト、勾配ブースティングの違いを試すと理解しやすくなります。その後、実務的な速度や精度を求める場合にLightGBMやXGBoostを触ると、パラメータの意味もつかみやすくなります。CatBoostはカテゴリ変数が多いデータで便利ですが、どのライブラリでもデータ分割や評価方法を誤ると、見かけの精度だけが高いモデルになります。
GBDTでよく出てくるパラメータ
GBDTを使うと、学習率、木の本数、木の深さ、葉の数、サンプリング率、正則化などのパラメータが出てきます。最初は多く見えますが、考え方を整理すると理解しやすくなります。
| 項目 | 意味 | 初心者向けの見方 |
|---|---|---|
| 学習率 | 1本の木の修正をどれくらい反映するか | 小さいほど慎重だが、多くの木が必要になりやすい |
| 木の本数 | 誤差修正を何回重ねるか | 増やすほど表現力は上がるが過学習に注意 |
| 木の深さ | 1本の木がどれくらい複雑な分岐を持てるか | 深いほど複雑な関係を拾うが覚えすぎやすい |
| 葉の数 | 木が分けられる最終グループの数 | モデルの細かさを調整する重要な項目 |
| サンプリング | 行や列の一部を使って学習する設定 | 過学習を抑え、学習を安定させる目的で使う |
初心者がやりがちな失敗は、精度を上げたいからといって木の本数や深さをひたすら増やすことです。学習データでの精度は上がっても、未知のデータでの精度が落ちるなら意味がありません。GBDTでは、検証データでの性能を見ながら、必要以上に複雑にしないことが大切です。
過学習、データリーク、評価設計に注意する
GBDTは強力なモデルであるため、データに含まれる不自然な手がかりも拾ってしまいます。ここで特に注意したいのが過学習とデータリークです。過学習は、学習データにはよく合うが、未知のデータにはうまく当たらない状態です。データリークは、本来予測時点では使えない情報が特徴量に混ざってしまうことです。
たとえば、解約予測で「解約手続き日」や「解約後アンケート回答」のような列を特徴量に入れてしまうと、モデルは非常に高い精度を出すかもしれません。しかし、それは予測したい時点では存在しない情報です。実運用では使えないため、モデルとしては失敗です。GBDTはこうした強い手がかりを見つけるのが得意なので、データリークがあると見かけの性能が大きく膨らみます。
時系列データでも注意が必要です。将来の情報が過去の予測に混ざらないよう、時間に沿って学習データと検証データを分ける必要があります。ランダム分割だけで評価すると、未来の傾向を間接的に学習してしまい、実際の運用よりも楽な評価になることがあります。需要予測、売上予測、離反予測、異常検知では、いつ使える情報かを明確にしておくことが重要です。
評価指標も目的に合わせて選びます。分類ならAccuracyだけでなく、Precision、Recall、F1、AUC、PR-AUCなどを検討します。陽性が少ない不正検知や解約予測では、単純な正解率が高く見えても、重要な陽性ケースをほとんど拾えていないことがあります。回帰ならMAE、RMSE、MAPEなどを使い分けます。現場での損失や意思決定に近い指標を選ぶことが、GBDTを実務で活かす条件です。
特徴量重要度は便利だが、因果関係とは限らない
GBDT系のモデルでは、特徴量重要度を確認できることが多くあります。どの列が予測に効いているかをざっくり把握できるため、モデルの説明やデータ理解に役立ちます。しかし、特徴量重要度が高いからといって、その特徴量が原因であるとは限りません。
たとえば、あるサービスで「問い合わせ回数」が解約予測に強く効いていたとします。これは、問い合わせが多いから解約するのかもしれませんし、解約を考えている人が問い合わせるからかもしれません。あるいは、特定の料金プランや利用状況と問い合わせ回数が関連しているだけかもしれません。GBDTは予測に役立つ関係を見つけますが、その関係が因果であるかは別問題です。
そのため、特徴量重要度は「次に調べるべき候補」として使うのが現実的です。業務担当者の知識、データの取得過程、時系列の前後関係、介入したときの変化などと合わせて解釈します。モデルの説明性を重視する場合は、Permutation ImportanceやSHAPなどの手法を使って、予測への寄与をより丁寧に確認することもあります。
GBDTを学ぶときのおすすめ手順
GBDTを学ぶときは、いきなりXGBoostやLightGBMの細かい設定に入るより、決定木から順番に理解する方が近道です。まず、単体の決定木がどのようにデータを分割するかを学びます。次に、複数の木を組み合わせるアンサンブル学習の考え方を学びます。その上で、ランダムフォレストとブースティングの違いを確認すると、GBDTの位置づけが明確になります。
実際に手を動かすなら、まず小さな表データを使って、決定木、ランダムフォレスト、GBDTを同じ評価方法で比較します。このとき、学習データと検証データを分け、学習データだけで前処理や特徴量作成を考える癖をつけます。次に、学習率、木の本数、木の深さを少しずつ変え、検証データでの性能がどう変わるかを見ます。グラフで確認すると、過学習の感覚がつかみやすくなります。
さらに一歩進めるなら、特徴量重要度を確認し、モデルが何を見て予測しているかを考えます。予測が外れたデータを眺めることも重要です。GBDTは高精度なモデルとして語られがちですが、学習に役立つのはスコアだけではありません。外れたケースを調べることで、データの不足、ラベルの曖昧さ、特徴量設計の弱さ、業務ルールとのズレが見えてきます。
GBDTが向いているケースと向いていないケース
GBDTが向いているのは、表形式のデータがあり、特徴量に予測対象と関係する情報が含まれているケースです。データ数が極端に少ない場合は注意が必要ですが、ある程度の行数と意味のある列があれば、強いベースラインになりやすいです。特徴量のスケールがバラバラでも扱いやすく、非線形な関係や条件の組み合わせを拾える点も強みです。
向いていないのは、画像、音声、文章のような非構造データをそのまま入力して、表現そのものを学ばせたいケースです。また、将来の外部環境が大きく変わる問題や、学習データが運用時のデータと大きく異なる問題では、GBDTに限らずモデルの信頼性が落ちます。さらに、説明責任が非常に強く求められる場面では、GBDTの予測理由を補足する仕組みが必要になります。
実務では、「GBDTを使えば解決する」と考えるより、「表データ予測の強い候補としてGBDTを試し、評価と運用条件を満たすか確認する」と考える方が安全です。問題設定、データ品質、評価設計、運用後の監視まで含めて初めて、モデルは価値を持ちます。
初心者が押さえるべきポイント
GBDTを初めて学ぶ人は、次の3点を押さえると理解が安定します。第一に、GBDTは決定木を使ったアンサンブル学習です。1本の木だけで判断するのではなく、複数の木を組み合わせます。第二に、木は並列ではなく順番に追加されます。前の予測の誤差を見て、次の木が補います。第三に、強力なモデルだからこそ、検証方法と過学習対策が重要です。
この3点が分かると、細かい用語も整理しやすくなります。学習率は修正の強さ、木の本数は修正回数、木の深さや葉の数は1本の木の複雑さ、正則化やサンプリングは覚えすぎを抑える工夫です。すべてを一度に暗記する必要はありません。モデルが「どのくらい複雑に、どのくらい慎重に、何回修正するか」を調整していると考えると、パラメータの意味がつながります。
また、GBDTを使う目的は、アルゴリズムを使うこと自体ではありません。最終的には、予測によって何を判断したいのか、どの程度の誤りなら許容できるのか、どの特徴量を使ってよいのか、運用後に性能が落ちたときどう検知するのかを考える必要があります。機械学習の実務では、モデル選択と同じくらい、問題設定と評価設計が重要です。
まとめ
GBDTは、Gradient Boosting Decision Treesの略で、勾配ブースティング決定木と呼ばれる機械学習アルゴリズムです。小さな決定木を順番に追加し、前の予測で残った誤差を次の木が補うことで、全体として高い予測精度を目指します。特に表形式のデータに強く、顧客分析、需要予測、リスク評価、広告配信、不正検知など、実務のさまざまな予測タスクで使われています。
決定木、ランダムフォレスト、GBDTはいずれも木構造を使いますが、学習の考え方は異なります。単体の決定木は分かりやすい反面、過学習しやすいことがあります。ランダムフォレストは複数の木を並列に作って安定性を高めます。GBDTは木を順番に作り、誤差を段階的に修正することで高い精度を狙います。
一方で、GBDTは強力だからこそ、過学習、データリーク、評価設計に注意が必要です。学習データで高いスコアが出ても、未来のデータや実運用で使えるとは限りません。特徴量がいつ使える情報なのか、検証データは運用状況に近いか、評価指標は目的に合っているかを確認することが重要です。
初心者は、まず「GBDTは誤差を順番に直す決定木のチーム」と理解するとよいでしょう。そのうえで、決定木、ランダムフォレスト、GBDTを同じデータで比較し、学習率や木の深さを変えながら挙動を観察すると、理論と実務のつながりが見えてきます。
更新履歴
| 日付 | 内容 |
|---|---|
| 2026年5月23日 | 初回公開 |