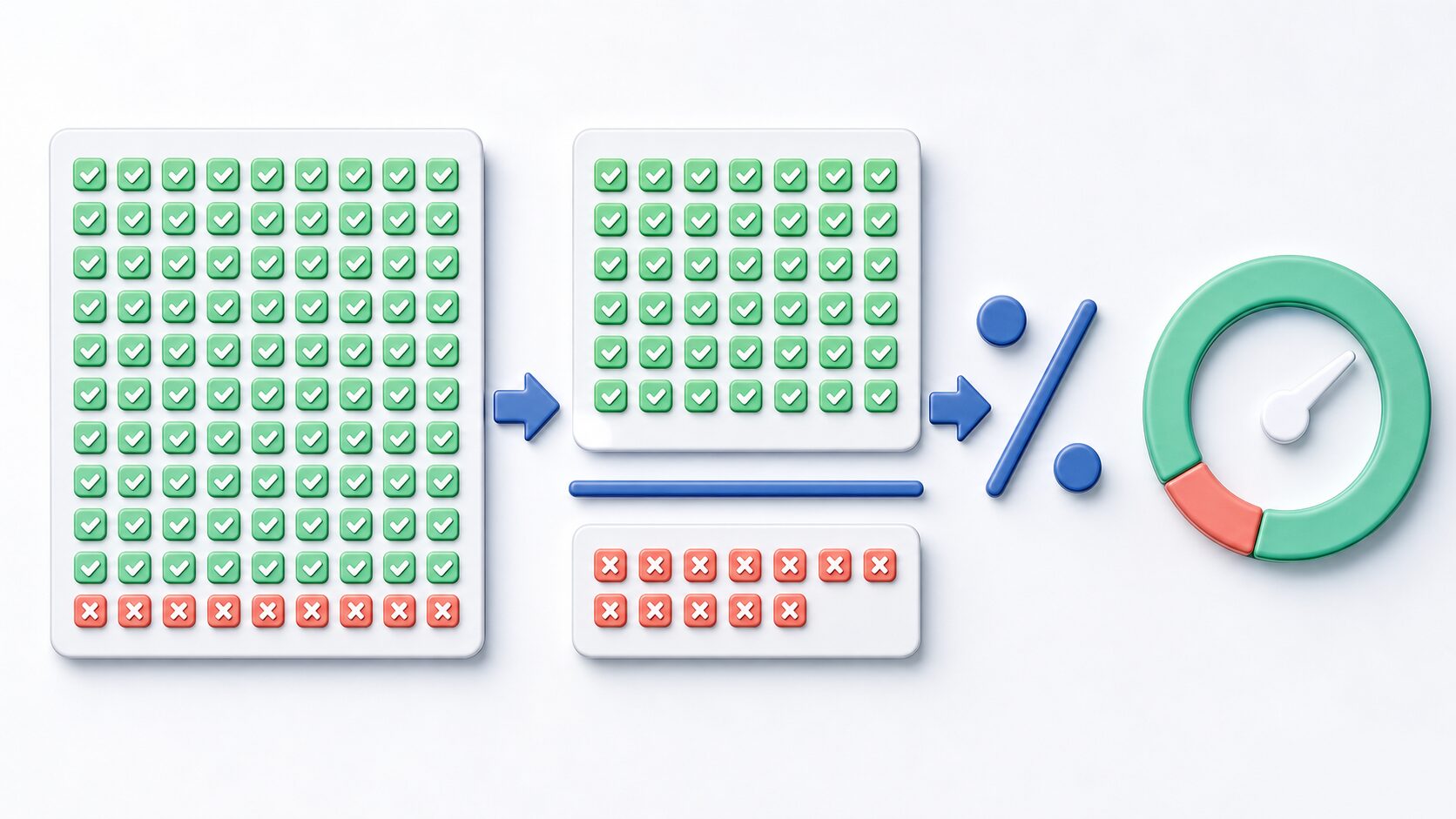
正解率とは?意味・計算方法・注意点をわかりやすく解説

AIの初心者
「正解率」ってよく聞くんですけど、具体的には何を表す指標なんですか?

AI専門家
正解率は、AIや機械学習モデルが出した予測のうち、どれだけが実際に正しかったかを表す割合だよ。たとえば、猫と犬の画像を分類する問題で考えると分かりやすいね。
AIの初心者
全部の予測のうち、当たった数を見るんですね。
AI専門家
その通り。100枚の画像のうち70枚を正しく分類できたなら、正解率は70%になる。ただし、正解率だけでモデルの良し悪しを決めてよいとは限らない点も大切だよ。
Accuracyとは。
正解率は英語で Accuracy と呼ばれ、機械学習モデルの評価でよく使われる基本的な指標です。分類問題で、モデルが出した予測のうち、実際の答えと一致した割合を表します。
「はい・いいえ」を判定する二値分類でも、猫・犬・鳥のように複数の候補から選ぶ多クラス分類でも、正解と不正解を数えられる問題であれば正解率を計算できます。一方で、正解率は分かりやすい反面、データの偏りや目的によっては性能を見誤ることがあります。
正解率とは何か
正解率とは、全データのうちモデルが正しく予測できたデータの割合です。たとえば、100件のデータを分類して85件が正解だった場合、正解率は85%です。
この指標は、モデルの結果を一目で説明しやすいのが利点です。学校のテストで「100問中85問正解」と聞くと出来具合を想像しやすいのと同じで、正解率はモデルの全体的な当たり具合を直感的に伝えます。
ただし、正解率は「どの種類の間違いをしたか」までは教えてくれません。猫を犬と間違えたのか、病気の人を健康と見逃したのかでは、同じ不正解でも意味が大きく違います。そのため、正解率は便利な入口の指標ですが、目的によっては他の評価指標と組み合わせて読む必要があります。
| 項目 | 説明 |
|---|---|
| 正解率 | 全予測のうち、実際の答えと一致した予測の割合 |
| 使いやすい場面 | 各クラスの件数が大きく偏っておらず、間違いの重みも近い分類問題 |
| 注意が必要な場面 | 珍しい病気の検出など、少数派を見逃すことが大きな問題になる場面 |
正解率の計算方法

正解率の計算は、正しく予測できた件数を全データ数で割るだけです。
\(\text{Accuracy} = \frac{\text{正しく予測できた件数}}{\text{全データ数}}\)たとえば、猫と犬の画像を合計100枚分類したとします。猫80枚のうち70枚、犬20枚のうち15枚を正しく分類できた場合、正しく分類できた画像は合計85枚です。したがって、正解率は85 ÷ 100 = 0.85、つまり85%になります。
この例では、猫と犬のどちらもある程度正しく分類できているため、正解率はモデルの全体像をつかむ助けになります。しかし、もし猫が99枚、犬が1枚のように偏っている場合は、犬を一度も当てられなくても高い正解率が出る可能性があります。計算式は簡単ですが、数字を読むときにはデータの内訳も確認しましょう。
| 内容 | 件数 |
|---|---|
| 全画像 | 100枚 |
| 正しく分類できた猫画像 | 70枚 |
| 正しく分類できた犬画像 | 15枚 |
| 正しく分類できた合計 | 85枚 |
| 正解率 | 85 ÷ 100 = 85% |
正解率が使われる場面
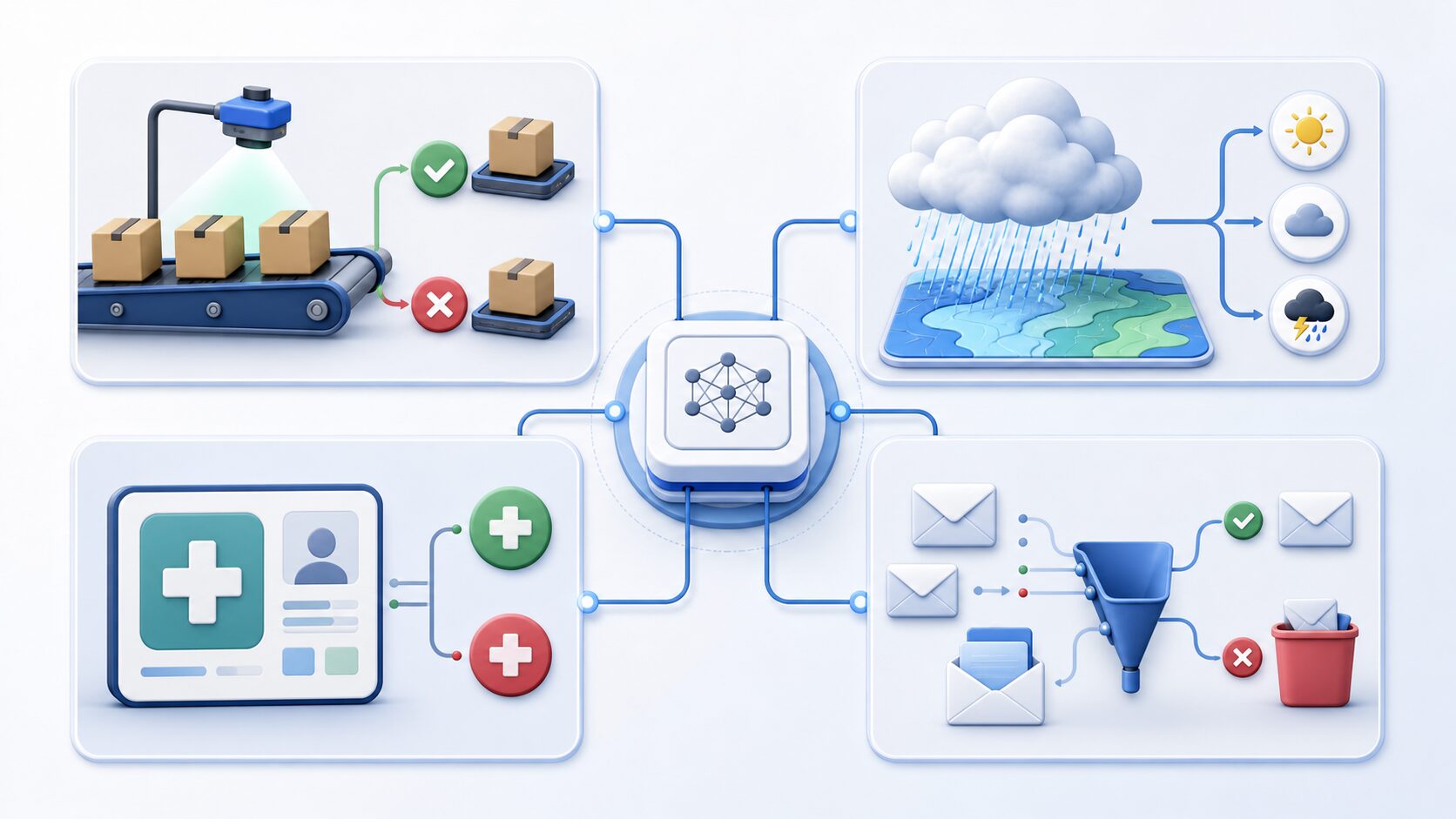
正解率は、予測が当たったか外れたかを数えられる場面で広く使われます。機械学習の分類モデルだけでなく、品質管理や判定システムの説明にも応用しやすい指標です。
製造業では、画像検査で良品と不良品を分類するモデルの評価に使えます。天気予報では、過去の予報が実際の天気とどれくらい一致したかを確認する考え方に近いです。迷惑メール判定では、メールを通常メールとスパムに正しく分けられた割合を測れます。
医療診断の支援モデルでも正解率は計算できますが、この分野では特に注意が必要です。病気の人を見逃すことと、健康な人を誤って病気と判定することでは、影響の大きさが異なります。正解率は全体の当たり具合を示すだけなので、どの誤りを避けたいのかを別の指標で確認する必要があります。
| 分野 | 正解率で見られること |
|---|---|
| 製造業 | 良品と不良品を正しく分類できた割合 |
| 情報通信 | スパムメールと通常メールを正しく判定できた割合 |
| 画像分類 | 写真や画像を正しいカテゴリへ分類できた割合 |
| 医療診断支援 | 診断結果が実際の状態と一致した割合。ただし見逃しの確認が重要 |
正解率だけでは危ないケース

データに偏りがあると、正解率が高くても実用上は役に立たないモデルになることがあります。代表例は、発生頻度の低い病気を見つける診断モデルです。
仮に、ある病気にかかっている人が全体の0.1%しかいないとします。このとき、すべての人を「病気ではない」と予測するモデルを作ると、99.9%という非常に高い正解率になります。しかし、このモデルは病気の人を一人も見つけられません。数字だけを見ると優秀に見えても、本来の目的である早期発見には失敗しています。
このような問題は、少数派のデータを見つけることが重要な場面で起こります。不正取引の検知、故障予兆の検出、迷惑メールの取りこぼし対策なども同じです。全体の正解率だけでなく、少数派をどれだけ拾えているか、誤検知がどれくらいあるかを確認することが欠かせません。
| 状況 | 正解率だけで判断する問題 | 確認したい点 |
|---|---|---|
| 珍しい病気の診断 | 全員を健康と予測しても高い正解率が出る | 病気の人を見逃していないか |
| 不正取引の検知 | 通常取引が多いため不正を無視しても高く見える | 不正をどれだけ発見できているか |
| スパム判定 | 通常メールの多さに引っ張られる | 重要メールの誤分類とスパムの見逃し |
適合率・再現率・F1値との違い
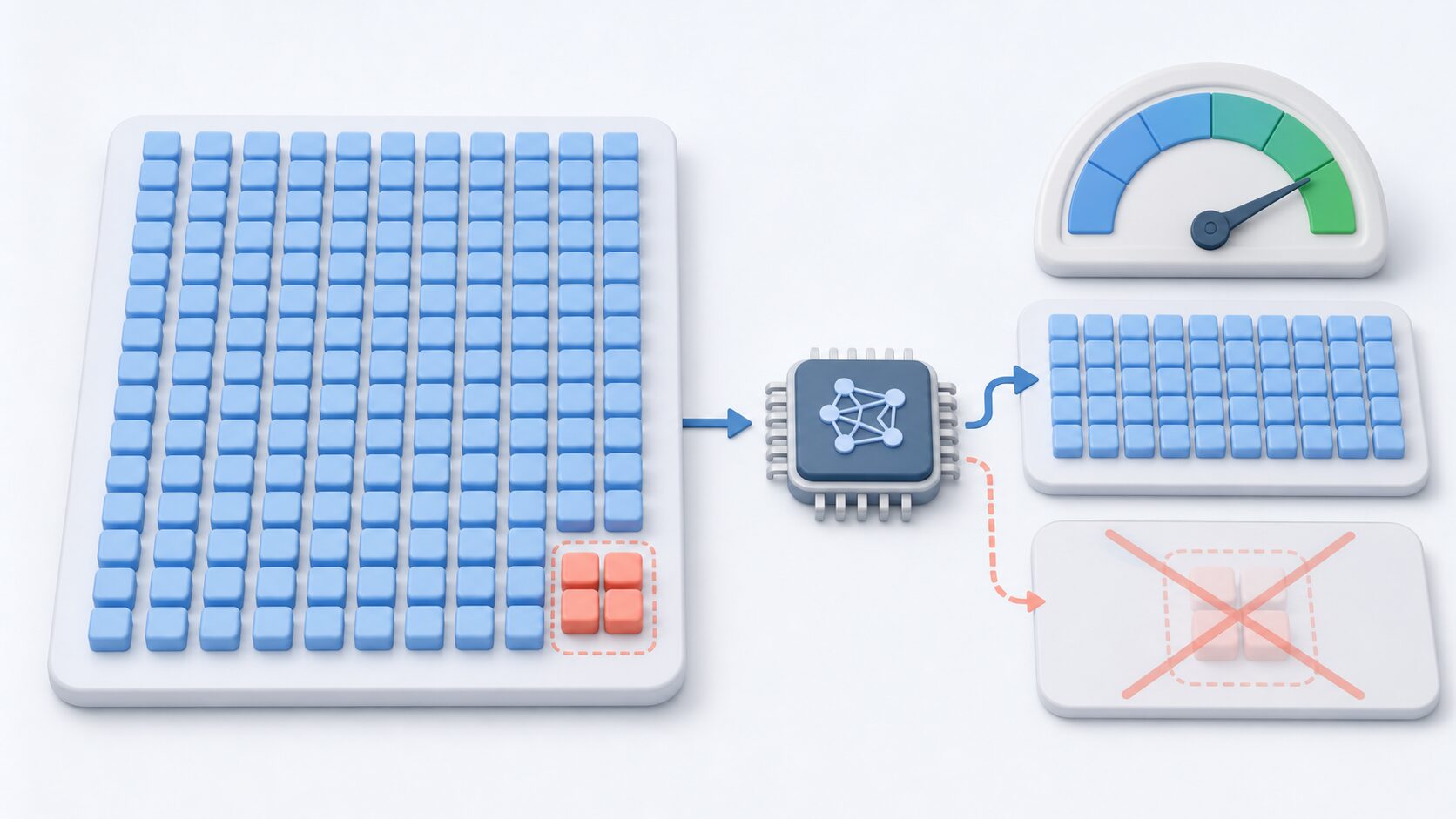
機械学習モデルを評価するときは、正解率だけでなく、適合率、再現率、F1値もよく使われます。これらは、正解率では見えにくい「どの種類の誤りが多いか」を確認するための指標です。
適合率は、モデルが「該当する」と予測したもののうち、実際に該当していた割合です。スパムメール判定なら、スパムと判定したメールの中に本当にスパムがどれくらい含まれていたかを見ます。誤って通常メールをスパム扱いしたくない場合に重要です。
再現率は、実際に該当するもののうち、モデルが正しく見つけられた割合です。病気の診断支援なら、実際に病気の人をどれだけ見つけられたかを見ます。見逃しを減らしたい場合に重要です。
F1値は、適合率と再現率のバランスを見る指標です。片方だけが高くても、もう片方が低いとF1値は高くなりません。正解率が高いモデルでも、適合率や再現率を見ると弱点が分かることがあります。
| 指標 | 見ること | 重視しやすい場面 |
|---|---|---|
| 正解率 | 全体の予測がどれくらい当たったか | クラスの偏りが少ない分類問題 |
| 適合率 | 「該当する」と予測した中で本当に該当した割合 | 誤検知を減らしたい場面 |
| 再現率 | 実際に該当するものをどれだけ見つけたか | 見逃しを減らしたい場面 |
| F1値 | 適合率と再現率のバランス | 誤検知と見逃しの両方を見たい場面 |
正解率を見るときの実務上のポイント
正解率を使うときは、まずデータの内訳を確認します。各クラスの件数が大きく偏っていないか、評価データが実際の利用場面に近いか、学習データと評価データが混ざっていないかを見ます。評価データが偏っていると、正解率は実際の運用時の性能をうまく表せません。
次に、間違いの種類ごとの影響を考えます。医療診断では見逃しが深刻になりやすく、スパム判定では重要メールを誤ってスパム扱いすることが問題になります。どちらの誤りがより避けたいものかによって、正解率以外に重視すべき指標が変わります。
最後に、正解率を単独のゴールにしないことが大切です。モデル改善では、正解率を上げるだけでなく、現場で許容できる誤判定の種類や件数に近づける必要があります。正解率は出発点として便利ですが、最終判断では目的、データ分布、誤りのコストを合わせて確認しましょう。
まとめ
正解率は、機械学習モデルが全体のうちどれだけ正しく予測できたかを示す基本的な評価指標です。計算式はシンプルで、正しく予測できた件数を全データ数で割るだけです。
一方で、正解率が高いからといって、必ずしも良いモデルとは限りません。データが偏っている場合や、少数派の見逃しが重要な場合は、正解率だけでは問題を見落とすことがあります。
モデルを適切に評価するには、正解率に加えて適合率、再現率、F1値などを確認し、目的に合った指標を選ぶことが大切です。正解率は分かりやすい指標だからこそ、数字の背景まで見て判断しましょう。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年1月31日 | 初回公開 |
| 2026年5月21日 | 計算式と不均衡データの例を補い、他指標との違いを追記 |