 学習
学習 k分割交差検証とは?5分割・10分割の仕組みと精度評価をわかりやすく解説
機械学習の模型の良し悪しを見極める作業は、限られた資料をうまく活用するために欠かせません。様々な手法がありますが、その中で「交差検証」と呼ばれるやり方は、模型の本当の力をより正確に測るための優れた方法です。特に、資料を均等に分割して検証する「k分割交差検証」は、広く使われています。
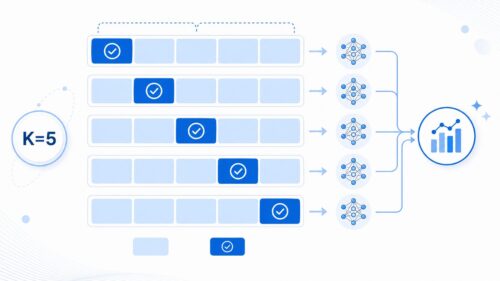
この手法では、まず手元にある資料を同じ大きさのk個のグループに分けます。たとえば、資料が100個あって、kを5に設定すると、20個ずつのグループが5つできます。次に、これらのグループの中から一つを選び、これを試験用の資料として取っておきます。残りのk-1個のグループは全てまとめて、模型の訓練に使います。kが5の場合は、5つのグループのうち1つを試験用、残りの4つを訓練用とするわけです。
この訓練と試験をk回繰り返します。k回目の検証が終わる頃には、それぞれのグループが一度ずつ試験用の資料として使われたことになります。つまり、全ての資料が模型の訓練と試験の両方に役立ったことになり、限られた資料を無駄なく使えるわけです。
分割数であるkの値は、状況に合わせて自由に決めることができます。ただし、一般的には5か10が使われることが多いです。kの値が小さいと、検証の回数が少なくなり、計算の手間は省けますが、検証結果のばらつきが大きくなる可能性があります。逆にkの値が大きいと、検証の精度が上がりますが、計算に時間がかかります。k分割交差検証を使うことで、限られた資料を最大限に活かし、模型の性能をより確実に見積もることができます。




