アルゴリズム
アルゴリズム 平均値プーリングで画像認識
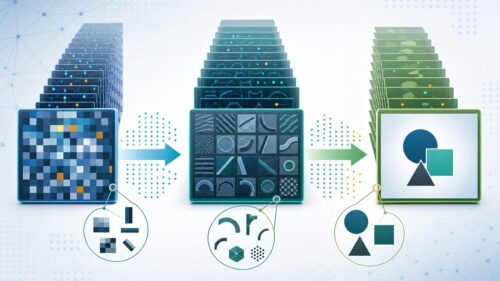
多くの小さな絵が集まって一枚の絵ができているとしましょう。この小さな絵の一つ一つを画素と呼び、全体を画素の集まりとして捉えることができます。これらの画素は、縦横に整然と並んでおり、膨大な数の色の情報を持ちます。この色の情報は、そのままでは処理するには情報量が多すぎて、時間もかかりますし、細かい違いにこだわりすぎて全体像を見失ってしまうこともあります。そこで、画素の集まりをまとめて扱う方法が必要になります。これが、画像認識で重要な役割を持つ「まとめ合わせ」処理、つまりプーリングです。
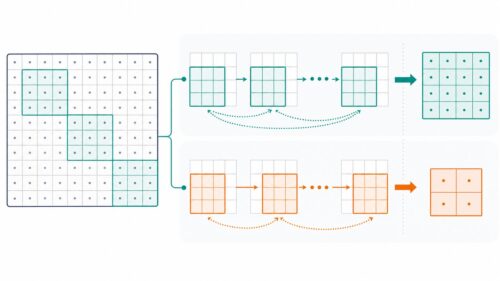
具体的な方法としては、まず絵をいくつかの区画に区切ります。そして、それぞれの区画の中で、代表となる色を一つ選びます。例えば、区画の中に赤、青、緑があったとしたら、一番多い色、例えば赤をその区画の代表色とします。この代表色を選ぶ作業を、全ての区画で行います。そうすることで、元の絵よりもずっと少ない色の情報で絵を表現できるようになります。これがプーリングによる情報の縮小です。
プーリングには、いくつかの利点があります。まず、情報の量が減るので、処理にかかる時間が短縮されます。また、小さな変化や色の違いに過剰に反応することが少なくなり、例えば猫の耳が少しだけ動いただけで別の生き物と認識してしまうような間違いを防ぎやすくなります。さらに、多少絵が汚れていても、全体の特徴を捉えやすくなります。例えば、猫の顔に少し泥がついていても、猫であると正しく認識できるようになります。このように、プーリングは、画像認識において、処理の効率化と正確性の向上に大きく貢献している重要な技術です。