開発環境
開発環境 機械学習の賢者:TensorFlow入門
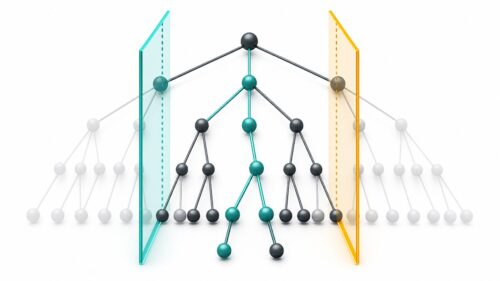
「テンソル・フロー」とは、機械学習を扱うための便利な道具集のようなもので、誰でも無料で使うことができます。これは、まるでたくさんの部品が入った箱のようなもので、開発者は自分のプログラムにこれらの部品を組み込むことで、難しい機械学習の機能を簡単に実現できます。この道具集は、人間の脳の神経回路の仕組みを真似た「ニューラルネットワーク」を作るのが得意です。
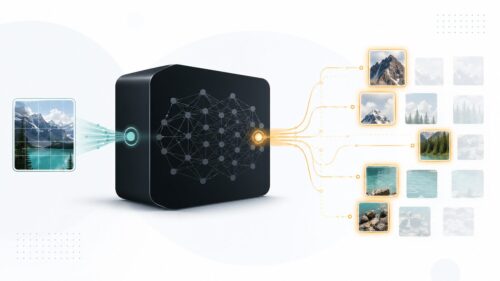
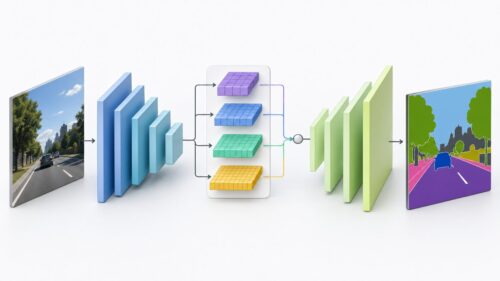
テンソル・フローは、特に画像を認識したり、人間の言葉を理解したりする技術で広く使われています。例えば、写真に写っているのが犬なのか猫なのかを判断したり、文章を翻訳したり、文章の内容を要約したりといった作業が可能です。また、医療の分野では、レントゲン写真から病気を診断するのを助けたり、創薬の研究にも役立っています。
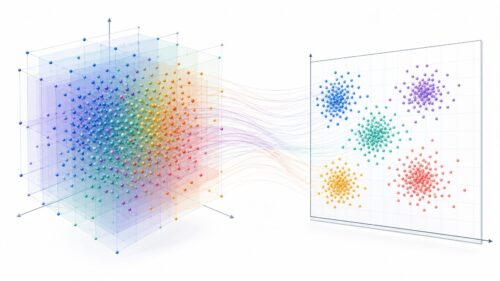
テンソル・フローは、まるで学習の達人のように、膨大な量のデータを読み解き、複雑な規則性を学ぶことができます。この能力のおかげで、機械は大量のデータから隠れたパターンを見つけ出すことができます。例えば、過去の気象データから未来の天気を予測したり、顧客の購買履歴からおすすめの商品を提案したりすることが可能になります。
テンソル・フローは、私たちが普段使っている様々な技術をより賢く、便利にしてくれる、縁の下の力持ちのような存在です。例えば、スマートフォンの音声認識や検索エンジンの予測変換、自動運転技術など、様々な場面で活躍しています。今後もテンソル・フローの進化によって、さらに生活が豊かになり、新しい技術が生まれてくることが期待されます。