RAGとは?検索拡張生成の仕組みと活用例を解説

AIの初心者
先生、「RAG」って何ですか?生成AIが検索も使う仕組みだと聞きました。

AI専門家
RAGは、LLMが回答を作る前に外部の文書やデータベースを検索し、その情報を根拠として回答に反映する仕組みです。日本語では検索拡張生成と呼ばれます。
AIの初心者
AIが覚えている知識だけで答えるのとは違うんですね。
AI専門家
その通りです。RAGを使うと、社内資料、FAQ、マニュアル、最新情報などを参照しながら回答できます。ただし、検索された文書の品質や、回答に根拠をどう反映するかがとても重要です。
RAGとは
RAGとは、Retrieval-Augmented Generationの略で、日本語では検索拡張生成と呼ばれます。LLMが回答を生成する前に、外部の文書やデータベースから関連情報を検索し、その内容をもとに回答を作る仕組みです。学習済みの知識だけに頼らず、社内データ、製品マニュアル、FAQ、最新情報などを参照できるため、根拠に基づく回答や業務向けAIの構築でよく使われます。
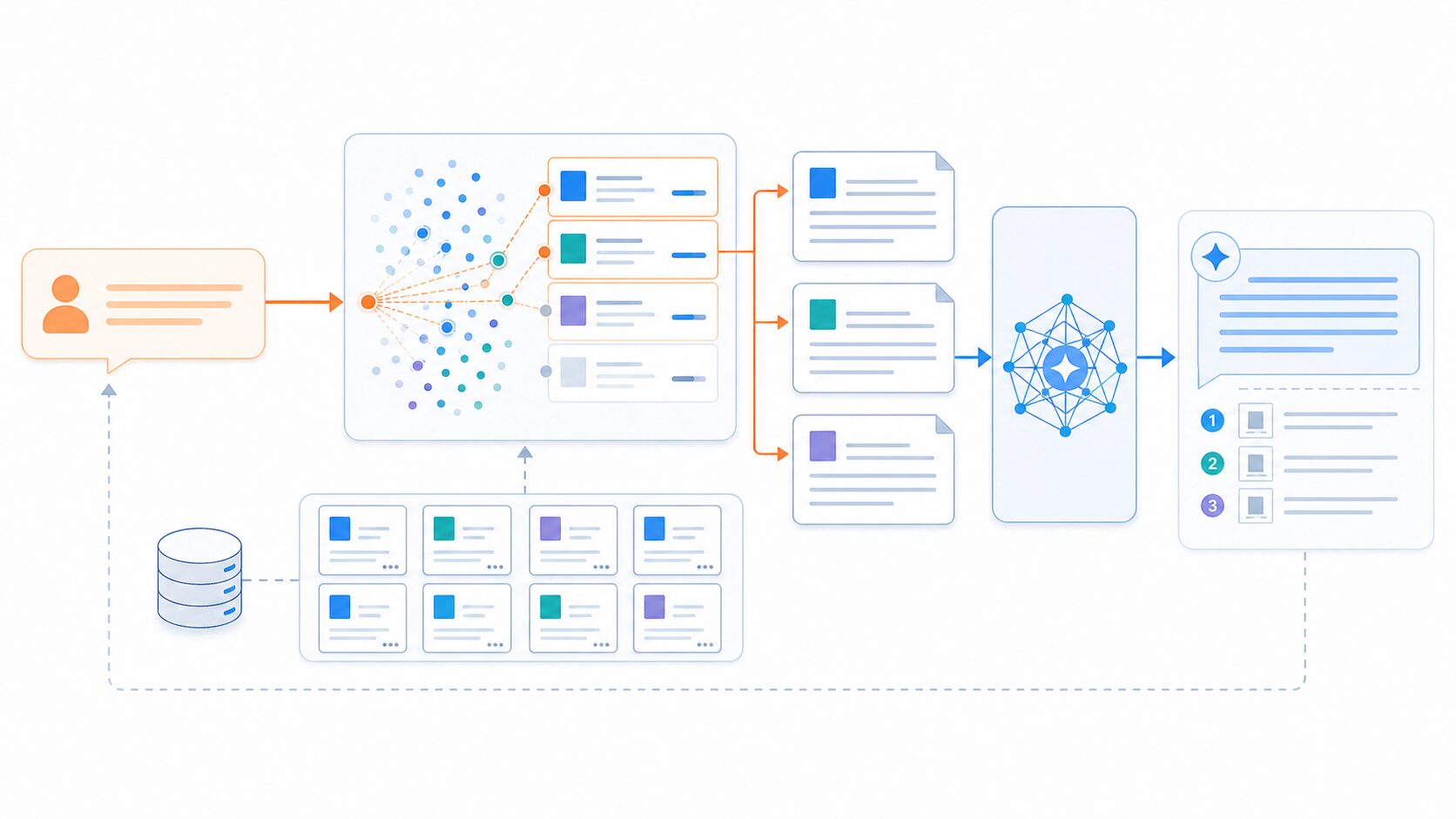
RAGとは
RAGとは、検索した外部情報をLLMの回答生成に組み込む技術です。Retrieval-Augmented Generationを略した言葉で、Retrievalは検索、Augmentedは拡張、Generationは生成を意味します。
通常のLLMは、学習済みデータに基づいて回答を作ります。そのため、学習後に変わった情報、社内だけにある情報、製品ごとの細かい仕様などには弱い場合があります。RAGは、この弱点を補うために、回答前に必要な情報を外部から検索します。
たとえば、ユーザーが「この製品の返品条件を教えて」と質問した場合、RAGシステムは社内の規約文書やFAQを検索し、関連する部分を取得します。そのうえで、LLMが取得した文書をもとに自然な回答を作ります。
| 用語 | 意味 |
|---|---|
| RAG | 外部情報を検索してから回答を生成する仕組み。 |
| Retrieval | 質問に関連する文書やデータを探す処理。 |
| Generation | 検索結果を踏まえて回答文を生成する処理。 |
| 検索拡張生成 | 検索によってLLMの回答生成を補強する考え方。 |
なぜRAGが必要なのか
LLMは幅広い知識を使って文章を生成できますが、常に最新で正確な情報を持っているわけではありません。学習データに含まれていない情報や、組織内だけにある情報は、そのままでは回答に反映できません。
また、LLMはもっともらしい文章を作るのが得意な一方で、根拠が曖昧なまま回答してしまうことがあります。これはハルシネーションと呼ばれる問題につながります。RAGは、回答時に参照する文書を与えることで、根拠のある回答を作りやすくします。
特に、社内ナレッジ、製品マニュアル、問い合わせ履歴、規約、技術文書のように、正確性が重要な情報を扱う場合にRAGは有効です。LLMの文章生成能力と、検索システムの情報取得能力を組み合わせることで、業務に使いやすいAIを作れます。
| 課題 | RAGで補える点 |
|---|---|
| 最新情報に弱い | 回答時点で参照できる文書を検索する。 |
| 社内情報を知らない | 社内文書やFAQを検索対象にできる。 |
| 根拠が曖昧になりやすい | 取得した文書を根拠として回答に使える。 |
| 再学習の負担が大きい | 文書を更新することで情報を反映しやすい。 |
RAGの基本的な流れ
RAGは、大きく分けると「検索」と「生成」の2段階で動きます。まず、ユーザーの質問をもとに、関連する文書やデータを検索します。次に、取得した情報をLLMに渡し、回答を生成します。
実際のシステムでは、文書をあらかじめ小さな単位に分割し、ベクトル化して検索しやすい形で保存しておくことが多いです。ユーザーの質問もベクトルに変換し、意味が近い文書チャンクを検索します。
検索された文書は、そのまま回答になるわけではありません。LLMは、取得した文書を読み取り、質問に合う形で要約したり、複数の文書を統合したりして回答を作ります。このとき、参照元を表示できるようにすると、利用者が根拠を確認しやすくなります。
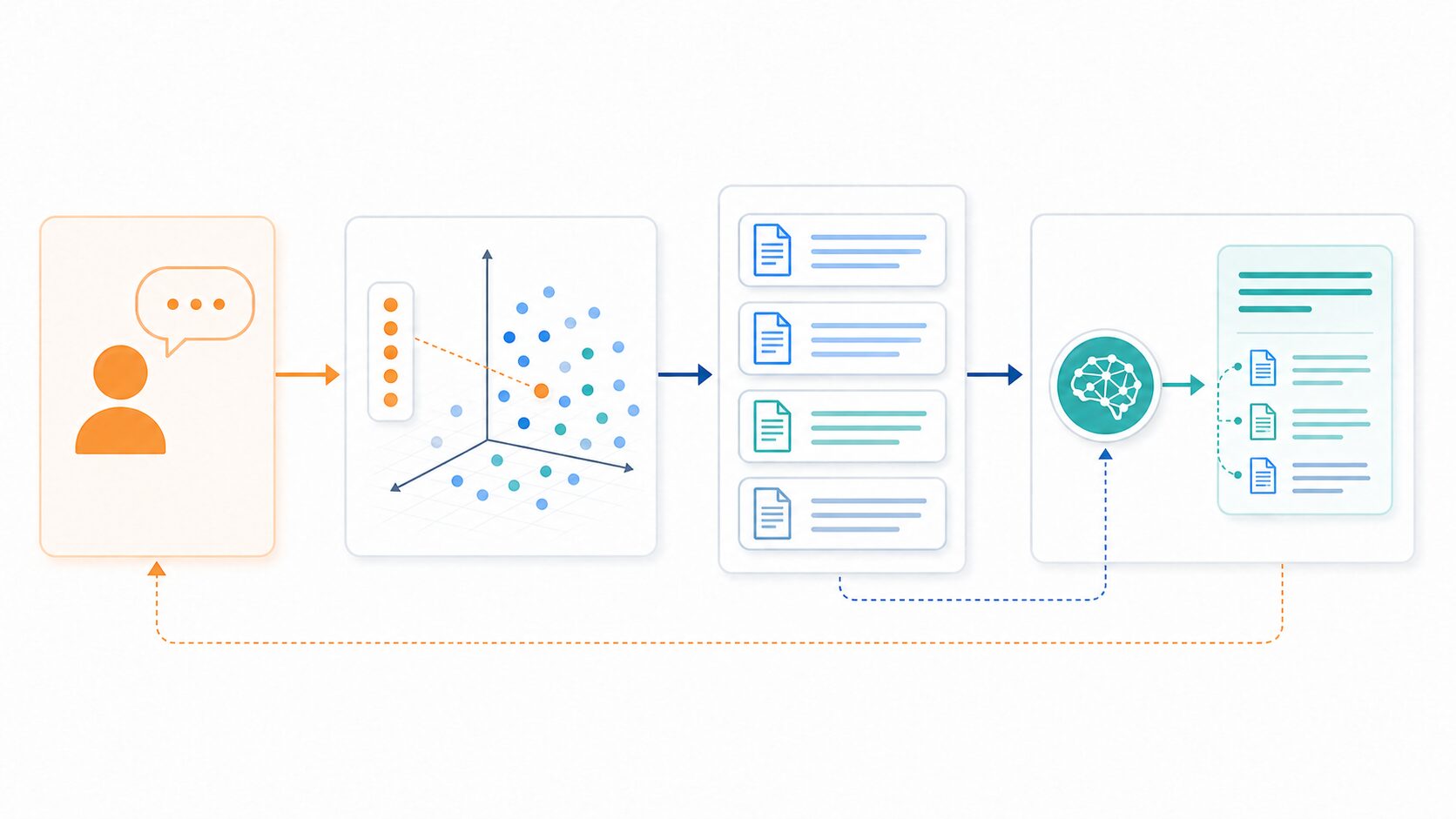
| 手順 | 処理 | 目的 |
|---|---|---|
| 1 | 文書を分割して保存する。 | 検索しやすい単位にする。 |
| 2 | 質問をベクトル化する。 | 意味の近い文書を探せるようにする。 |
| 3 | 関連文書を検索する。 | 回答に使う根拠を集める。 |
| 4 | 検索結果をLLMに渡す。 | 回答の材料を与える。 |
| 5 | LLMが回答を生成する。 | 利用者に分かりやすく返答する。 |
ベクトル検索と類似度
RAGでよく使われるのがベクトル検索です。ベクトル検索では、文章を数値の列に変換し、意味が近い文章同士が近くに配置されるようにします。この数値表現を埋め込みベクトルと呼びます。
たとえば、「返品方法を知りたい」という質問と、「返品は購入日から30日以内に受け付けます」という文書は、単語が完全に一致していなくても意味が近いと判断できます。ベクトル検索を使うと、このような意味の近さをもとに関連文書を探せます。
類似度の計算には、コサイン類似度などが使われます。コサイン類似度は、2つのベクトルの向きがどれだけ近いかを見る指標です。値が高いほど、質問と文書の意味が近いと考えます。
| 要素 | 役割 |
|---|---|
| 埋め込みベクトル | 文章の意味を数値の列で表す。 |
| ベクトルデータベース | 文書ベクトルを保存し、高速に検索する。 |
| 類似度 | 質問と文書がどれだけ近いかを測る。 |
| 文書チャンク | 検索しやすいように分割された文書の一部。 |
通常のLLMとの違い
通常のLLMは、モデル内部に学習された知識をもとに回答します。質問に対して自然な文章を作れますが、回答の根拠がどの文書にあるのかを示しにくい場合があります。また、最新情報や社内固有の情報には対応しにくいことがあります。
RAGでは、回答前に検索を行うため、外部文書を根拠として使えます。検索対象を更新すれば、モデル自体を再学習しなくても、新しい情報を反映しやすくなります。社内文書を検索対象にすれば、社内ルールや製品仕様にも対応しやすくなります。
ただし、RAGを使えば必ず正しくなるわけではありません。検索された文書が古い、質問とずれている、文書同士が矛盾している場合は、回答も誤る可能性があります。RAGはLLMの弱点を補う仕組みですが、検索品質と文書管理が前提になります。
| 観点 | 通常のLLM | RAG |
|---|---|---|
| 情報源 | 学習済みの内部知識。 | 検索した外部文書やデータ。 |
| 最新情報 | 学習時点に依存する。 | 検索対象を更新すれば反映しやすい。 |
| 社内情報 | 基本的には知らない。 | 社内文書を検索対象にできる。 |
| 根拠提示 | 難しい場合がある。 | 参照文書や引用箇所を示しやすい。 |
RAGの活用例
RAGは、情報検索と文章生成を組み合わせたい場面で使われます。代表例はカスタマーサポートです。製品マニュアル、FAQ、過去の問い合わせ履歴を検索し、顧客の質問に合わせた回答を作れます。
社内ナレッジ検索にも向いています。就業規則、申請手順、営業資料、技術文書などを検索対象にすれば、社員が必要な情報を自然な文章で探せるようになります。単なるキーワード検索よりも、質問文に近い情報を見つけやすくなります。
教育や研修でも活用できます。教材、マニュアル、社内ルールを参照しながら、受講者の質問に合わせた説明を生成できます。研究開発では、技術文書や論文、実験記録を検索し、調査や要約を支援する使い方もあります。
| 分野 | 検索対象 | 活用例 |
|---|---|---|
| カスタマーサポート | FAQ、製品マニュアル、対応履歴 | 問い合わせへの回答作成。 |
| 社内ナレッジ | 規程、手順書、営業資料 | 社員向けQ&Aや文書検索。 |
| 教育・研修 | 教材、マニュアル、研修資料 | 理解度に合わせた説明。 |
| 研究開発 | 論文、技術文書、実験記録 | 調査、要約、比較検討。 |
導入時の注意点
RAGで最も重要なのは、検索対象となる文書の品質です。古い文書、重複した文書、誤った文書が含まれていると、検索結果も回答も不正確になります。RAGの精度は、LLMだけでなく、文書管理の品質にも大きく左右されます。
検索の精度も重要です。質問に対して関係の薄い文書が取得されると、LLMはその文書をもとにずれた回答を作ることがあります。文書の分割方法、メタデータ、検索クエリの作り方、再ランキングなどを調整する必要があります。
また、権限管理にも注意が必要です。社内文書を扱う場合、ユーザーが閲覧権限を持たない文書をRAGが参照してしまうと、情報漏えいにつながります。検索段階で権限を反映し、回答にも機密情報が含まれないように制御する必要があります。
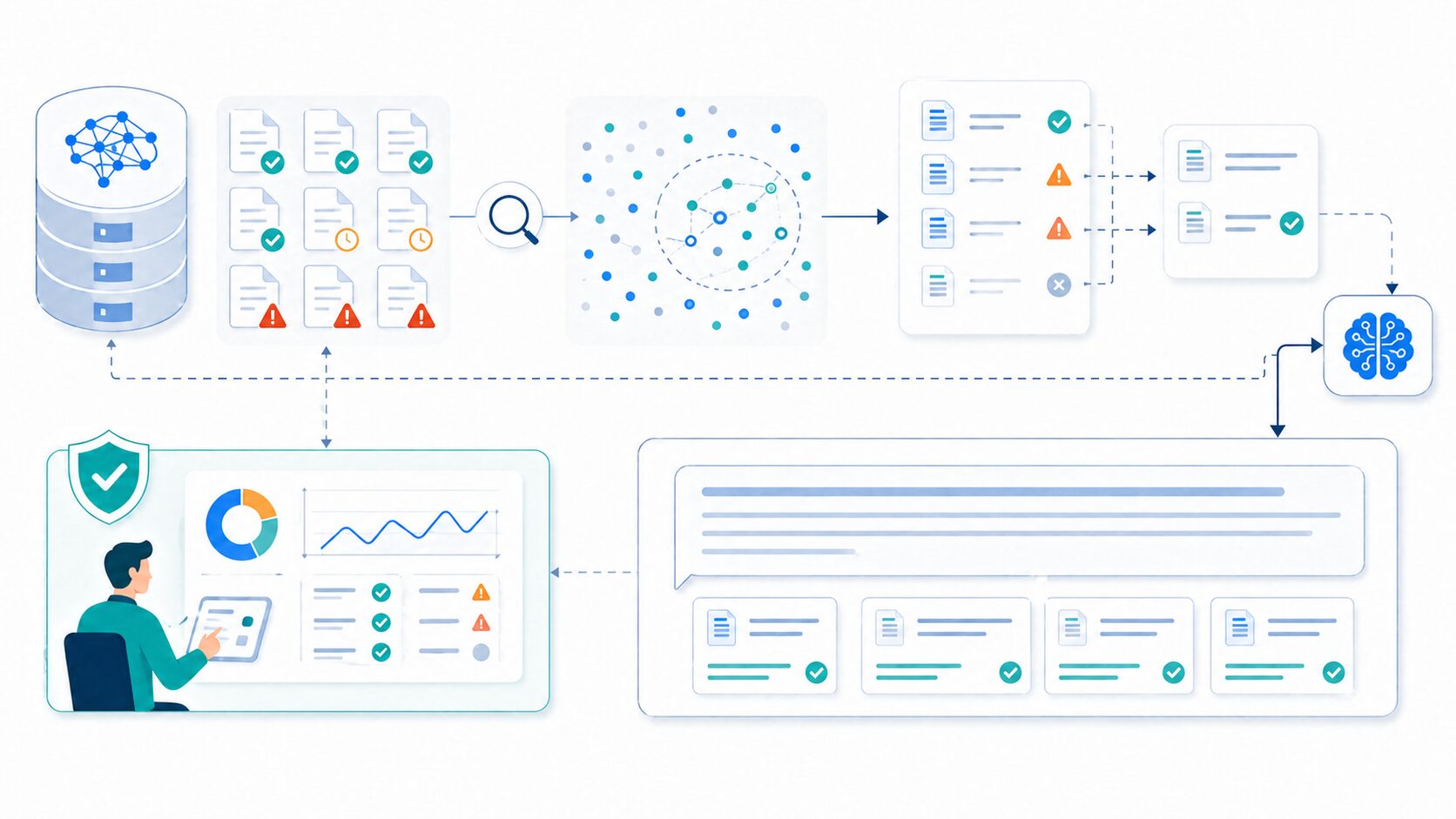
| 注意点 | 内容 | 対策 |
|---|---|---|
| 文書の品質 | 古い文書や誤情報が回答に混ざる。 | 文書の更新、重複整理、レビューを行う。 |
| 検索のずれ | 質問と関係の薄い文書を取得する。 | チャンク設計、メタデータ、再ランキングを調整する。 |
| 権限管理 | 見せてはいけない文書を参照する可能性がある。 | ユーザー権限を検索条件に反映する。 |
| 回答の検証 | 検索結果を誤って解釈することがある。 | 引用元表示、ログ確認、人による確認を組み合わせる。 |
RAGとファインチューニングの違い
RAGと混同されやすい方法に、ファインチューニングがあります。ファインチューニングは、モデルの振る舞いや出力傾向を追加学習で調整する方法です。特定の文体に合わせる、分類タスクに強くする、業務特有の回答形式に寄せるといった目的で使われます。
一方、RAGはモデルを再学習するのではなく、回答時に外部文書を検索して渡す方法です。最新情報や社内文書を反映したい場合は、まずRAGを検討することが多くなります。文書を更新すれば検索対象も更新できるため、情報の入れ替えに対応しやすいからです。
実務では、RAGとファインチューニングを組み合わせることもあります。たとえば、RAGで根拠文書を取得し、ファインチューニングで回答形式やトーンを業務に合わせる、といった使い方です。
| 方法 | 主な目的 | 向いている場面 |
|---|---|---|
| RAG | 外部文書を参照して回答する。 | 最新情報、社内データ、根拠提示が重要な場合。 |
| ファインチューニング | モデルの振る舞いや出力形式を調整する。 | 文体、分類、定型応答、出力形式を安定させたい場合。 |
まとめ
RAGとは、LLMが回答を生成する前に外部の文書やデータベースを検索し、その情報をもとに回答を作る検索拡張生成の仕組みです。学習済みの知識だけに頼らず、社内資料や最新情報を参照できる点が特徴です。
RAGを使うと、カスタマーサポート、社内ナレッジ検索、教育、研究開発などで、根拠に基づく回答を作りやすくなります。一方で、検索対象の文書が古い、検索結果が質問とずれている、権限管理が不十分といった問題があると、誤回答や情報漏えいにつながる可能性があります。
RAGは、LLMを業務で活用するうえで重要な技術です。ただし、導入時はLLMだけでなく、文書管理、検索品質、引用元表示、アクセス制御まで含めて設計することが大切です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2026年4月26日 | RAGの定義、必要性、基本フロー、ベクトル検索、通常のLLMとの違い、活用例、導入時の注意点、ファインチューニングとの違いを中心に本文を全面的に見直しました。 |