マルコフ決定過程モデルとは?意味・仕組み・活用例をわかりやすく解説

AIの初心者
『マルコフ決定過程モデル』は、今の状態だけで未来を考えると聞きました。実際には何を決めるためのモデルなんですか?

AI専門家
例えば、今日の天気が晴れなら、明日の天気は晴れ、曇り、雨のどれかになる可能性があります。このとき、明日の予測に必要な情報を今日の状態にまとめて考えるのがマルコフ過程の考え方です。
AIの初心者
では、マルコフ決定過程では何が追加されるんですか?
AI専門家
「行動」と「報酬」が加わります。洗濯物を外に干す、部屋干しする、乾燥機を使うといった行動を選び、その結果として乾きやすさや電気代のような報酬を考えます。今の状態でどの行動を選ぶと長期的に良い結果になるかを扱うのが、マルコフ決定過程です。
マルコフ決定過程モデルとは。
マルコフ決定過程モデルは、現在の状態で行動を選ぶと、次の状態が確率的に決まり、その結果として報酬を受け取る仕組みを表すモデルです。人工知能や強化学習では、ロボットやソフトウェアが不確実な環境でより良い行動を選ぶための土台として使われます。
マルコフ決定過程モデルとは
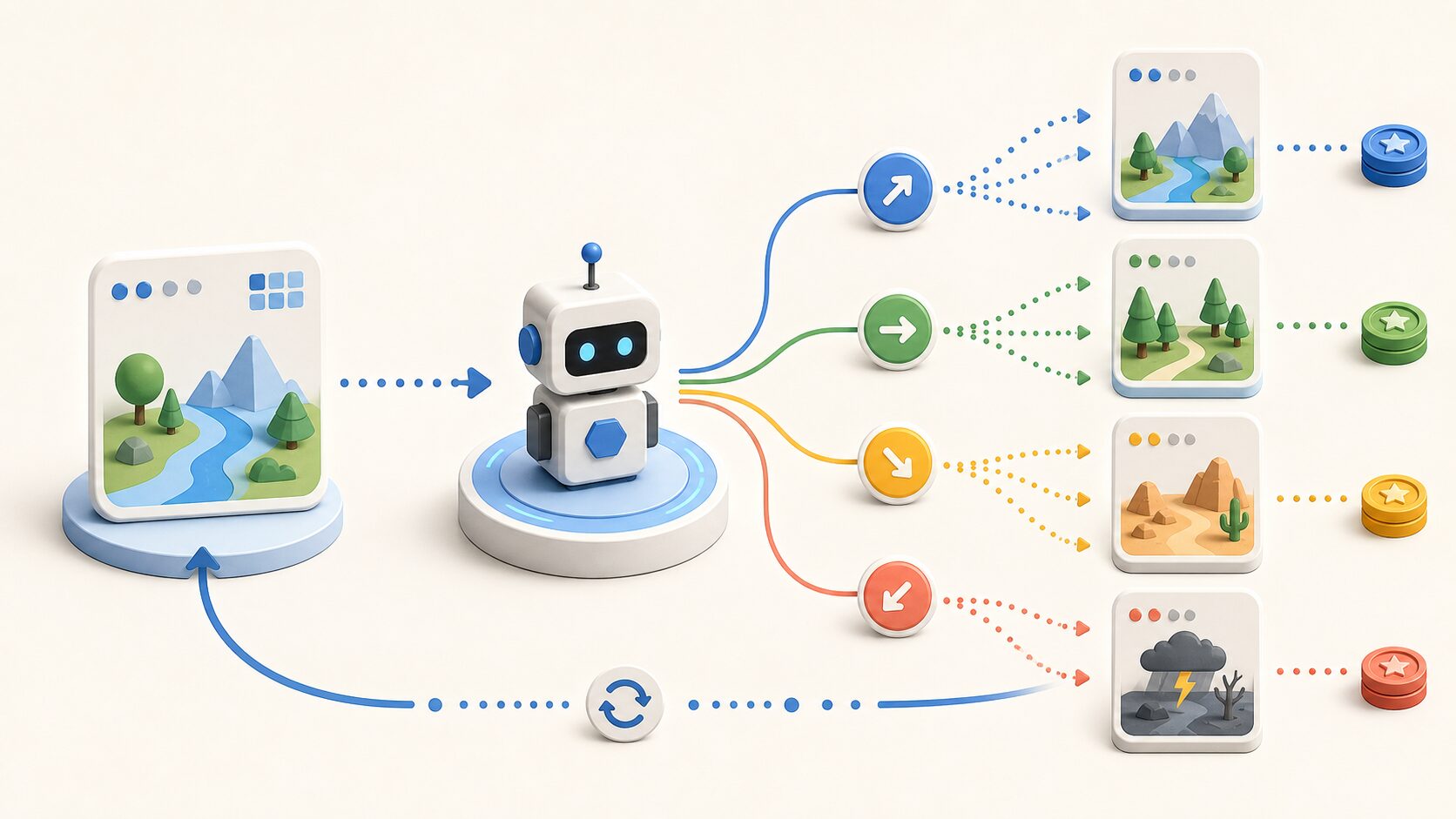
マルコフ決定過程モデルとは、不確実な状況で「どの行動を選べば、長期的に最も良い結果を得られるか」を考えるための数理モデルです。英語では Markov Decision Process と呼ばれ、略して MDP と書かれることもあります。
ポイントは、未来が完全には決まっていないことです。同じ行動を選んでも、次に起こる状態は確率によって変わる場合があります。たとえば、ロボットが右へ進む命令を出しても、床が滑りやすければ少しずれるかもしれません。金融取引でも、同じ投資判断をしても市場の動きによって結果は変わります。
MDPでは、このような不確実性を無視せず、状態、行動、遷移確率、報酬を組み合わせて問題を表します。そして、目先の利益だけでなく、将来にわたって得られる報酬の合計が大きくなるような行動の選び方を探します。
| 用語 | 意味 | 例 |
|---|---|---|
| 状態 | 現在の状況を表す情報 | ロボットの位置、天気、在庫数 |
| 行動 | その状態で選べる選択肢 | 進む、止まる、発注する |
| 報酬 | 行動の結果として得られる評価値 | 得点、利益、コスト削減量 |
| 遷移確率 | 次の状態へ移る確率 | 晴れから雨になる確率、移動が成功する確率 |
マルコフ過程との違い
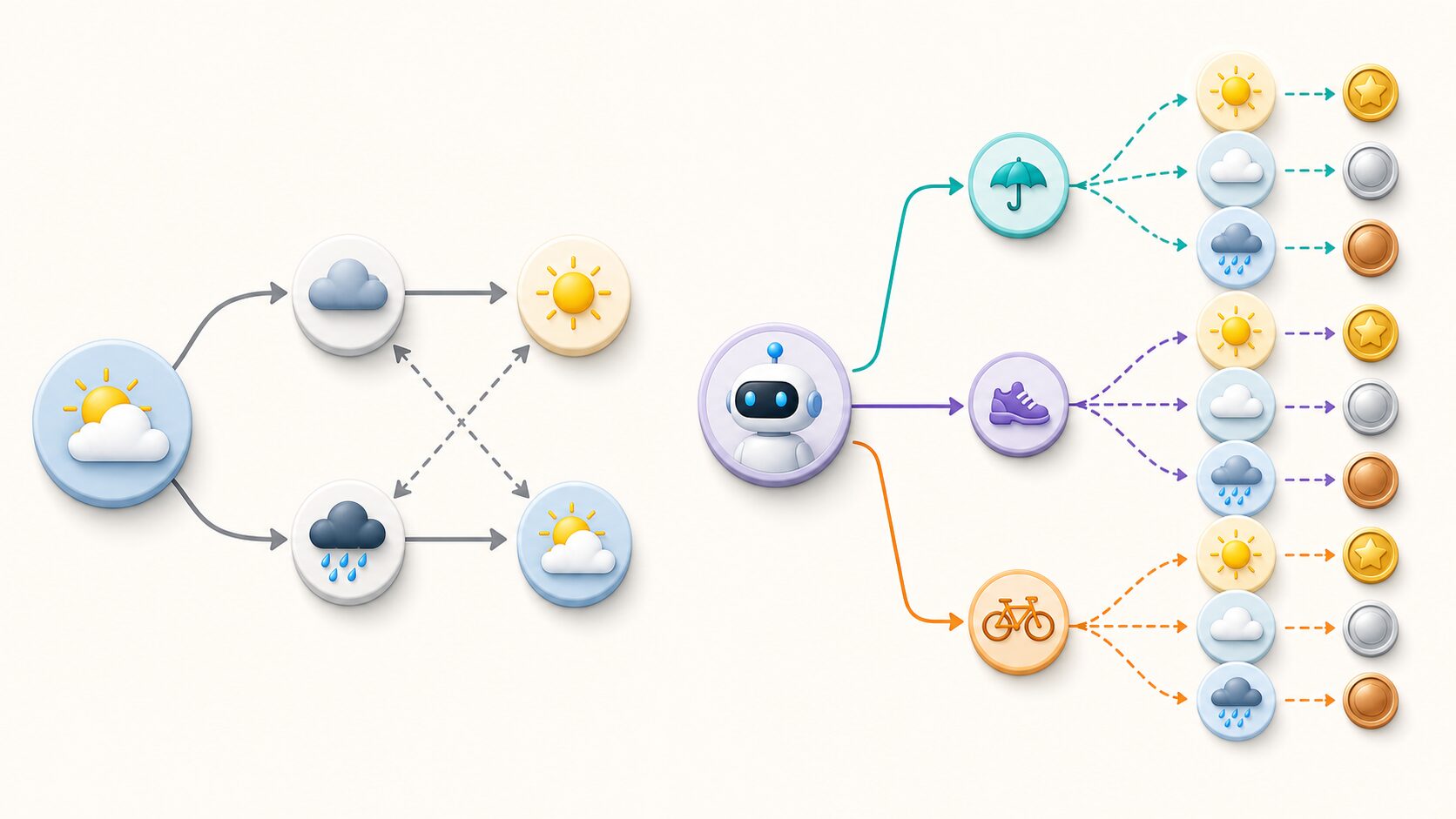
マルコフ決定過程を理解するには、まずマルコフ過程との違いを押さえると分かりやすくなります。マルコフ過程は、未来の状態が現在の状態によって決まると考える確率モデルです。過去のすべての出来事をたどるのではなく、予測に必要な情報が現在の状態にまとまっているとみなします。
たとえば天気で考えると、今日が晴れなら明日も晴れる確率、曇る確率、雨になる確率を設定できます。このとき「一昨日が雨だったかどうか」まで直接使わず、今日の天気をもとに次の天気を考えるのがマルコフ過程の発想です。
一方、マルコフ決定過程では、そこに行動を選ぶ主体が加わります。単に天気が変わるのを予測するだけでなく、外に干す、部屋干しする、乾燥機を使うといった行動を選び、その結果を評価します。つまり、マルコフ過程が「状態はどう移り変わるか」を扱うのに対し、マルコフ決定過程は「どの行動を選ぶべきか」まで扱います。
| モデル | 扱うもの | 主な目的 |
|---|---|---|
| マルコフ過程 | 状態と状態遷移 | 次の状態を確率的に表す |
| マルコフ決定過程 | 状態、行動、遷移、報酬 | 長期的に良い行動を選ぶ |
MDPを構成する5つの要素
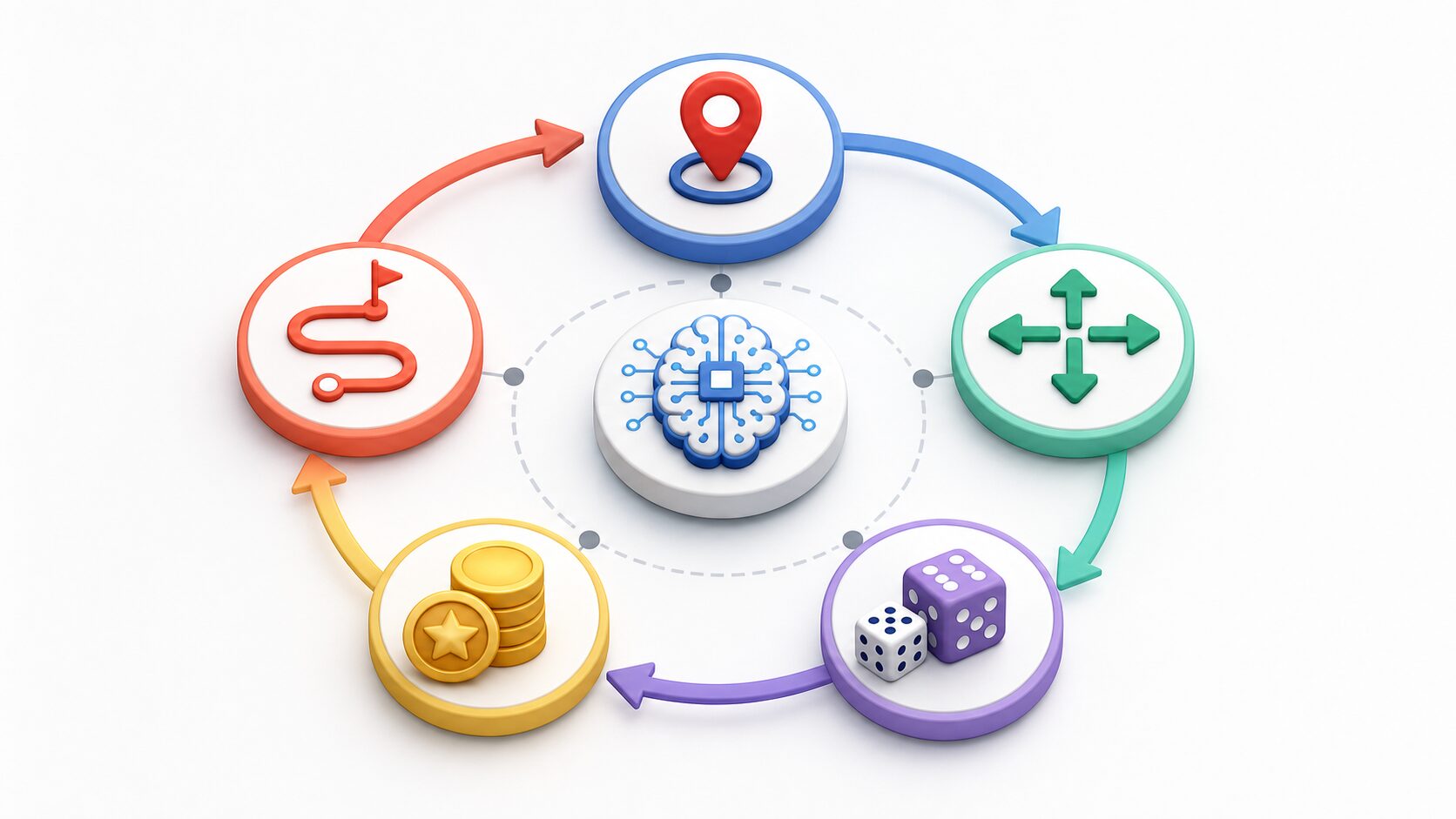
MDPは、一般に状態、行動、遷移確率、報酬、方策の組み合わせとして説明されます。厳密な数式では、次のように表されることがあります。
\(MDP = (S, A, P, R, \gamma)\)ここで \(S\) は状態の集合、\(A\) は行動の集合、\(P\) は状態遷移の確率、\(R\) は報酬、\(\gamma\) は将来の報酬をどれくらい重視するかを表す割引率です。初心者の段階では、記号を暗記するよりも、それぞれが何を表しているかを具体例に置き換えて理解することが大切です。
方策は、ある状態でどの行動を選ぶかを決めるルールです。迷路なら「このマスでは右へ進む」「このマスでは上へ進む」といった行動の決め方が方策にあたります。MDPで最終的に求めたいものは、多くの場合、この方策です。
| 要素 | 初心者向けの説明 | 迷路の例 |
|---|---|---|
| 状態 | いま何が起きているか | ロボットがいるマス |
| 行動 | 選べる操作 | 上下左右に動く |
| 遷移確率 | 行動後にどこへ移るかの確率 | 80%で予定通り、20%でずれる |
| 報酬 | 結果の良し悪しを数値にしたもの | ゴールで+10、壁に衝突で-1 |
| 方策 | 状態ごとの行動ルール | 各マスで進む方向を決める |
天気と洗濯の例で考える
身近な例として、洗濯物をどう乾かすかを考えてみます。状態は「今日の天気」「湿度」「洗濯物の量」などです。行動は「外に干す」「部屋干しする」「乾燥機を使う」です。報酬は、乾き具合、電気代、手間をまとめた点数として設定できます。
晴れていて風がある状態なら、外に干す行動は高い報酬を得やすいでしょう。しかし、雨が降る可能性が高い状態では、外に干すと濡れてしまい、報酬は下がります。乾燥機を使えば天気の影響は受けにくいものの、電気代がかかるため報酬を少し減らす設計にできます。
この例で重要なのは、行動の結果が一つに決まらない点です。天気の変化には確率があり、同じ行動でも結果が変わります。MDPは、その不確実性を前提にして、平均的に見て良い選択を探すための枠組みです。
最適な行動戦略を見つける考え方
MDPで求めたいのは、長期的に見て報酬が大きくなる行動戦略です。目の前の報酬だけを最大にする行動が、いつも最善とは限りません。迷路で近くの通路に進むとすぐ行き止まりになる一方、少し遠回りに見える道が最終的にはゴールへの近道になることがあります。
この考え方を表すために、将来の報酬も含めた価値を計算します。代表的なイメージは次の式です。
\(G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \cdots\)\(G_t\) は時点 \(t\) から見た将来報酬の合計、\(R\) は各時点で得られる報酬、\(\gamma\) は将来の報酬をどれくらい割り引いて考えるかを表します。\(\gamma\) が大きいほど将来を重視し、小さいほど近い報酬を重視します。
強化学習では、環境との試行錯誤を通じて、この価値や方策を学習します。つまり、MDPは強化学習の問題を整理するための基本的な地図のような役割を持ちます。
活用される分野

マルコフ決定過程モデルは、単なる理論ではなく、多くの分野で意思決定の自動化に使われます。代表例はロボット制御です。ロボットは現在位置や周囲の障害物を状態として認識し、移動、停止、旋回といった行動を選びます。移動が必ず予定通りに成功するとは限らないため、確率を含めて最適な行動を考える必要があります。
ゲームAIでもMDPの考え方は重要です。キャラクターやエージェントは、現在の盤面や相手の行動を踏まえ、攻撃、防御、移動などの選択肢から行動を選びます。すぐに得点できる行動より、数手先に有利になる行動を選ぶ方が良い場合もあります。
自動運転では、車線変更、減速、停止、右左折などの行動を、道路状況や周囲の車両との関係に応じて選びます。金融取引や在庫管理では、利益とリスク、保管コスト、需要変動を考えながら行動を決めます。このようにMDPは、不確実な環境で繰り返し意思決定する問題と相性が良いモデルです。
| 分野 | 状態の例 | 行動の例 |
|---|---|---|
| ロボット制御 | 位置、速度、障害物 | 移動、停止、旋回 |
| ゲームAI | 盤面、得点、相手の位置 | 攻撃、防御、移動 |
| 自動運転 | 車線、速度、周囲の車両 | 加速、減速、車線変更 |
| 在庫管理 | 在庫数、需要、納期 | 発注、保留、値引き |
初心者がつまずきやすい注意点
まず、「現在の状態だけを見ればよい」という説明を、過去がまったく意味を持たないという意味に受け取らないことが大切です。実際には、過去の情報のうち予測や意思決定に必要なものを、現在の状態に含めておく必要があります。状態の設計が不十分だと、モデルは正しい判断をしにくくなります。
次に、報酬の設計にも注意が必要です。報酬を「すぐ得られる得点」だけにすると、短期的には良く見えても長期的には損をする行動を選ぶことがあります。たとえば在庫管理で保管コストだけを強く罰すると、在庫を減らしすぎて欠品が増えるかもしれません。
また、現実の問題では状態や行動の種類が膨大になることがあります。すべての状態と行動を表にして計算できるとは限りません。そのため実務では、近似手法、シミュレーション、強化学習アルゴリズムなどを組み合わせて扱うことが多くなります。
まとめ
マルコフ決定過程モデルは、現在の状態で行動を選び、その結果として次の状態と報酬が確率的に決まる状況を表すモデルです。マルコフ過程に行動と報酬を加えることで、未来を予測するだけでなく、どの行動を選ぶべきかを考えられるようになります。
基本要素は、状態、行動、遷移確率、報酬、方策です。これらを使うことで、ロボット制御、ゲームAI、自動運転、金融取引、在庫管理など、さまざまな意思決定問題を整理できます。初学者は、数式の細部に入る前に「状態を観測する、行動を選ぶ、確率的に次へ進む、報酬を受け取る」という流れを具体例でつかむと理解しやすくなります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月30日 | MDPの構成要素と強化学習とのつながりを補足 |