アルゴリズム
アルゴリズム RNN:未来予測の立役者
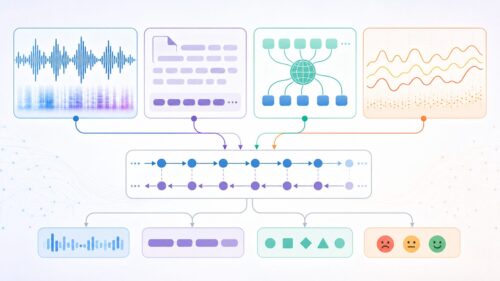
人間の記憶と同じように、過去の出来事を覚えておきながら学ぶ特別な仕組み、それが「再帰型ニューラルネットワーク」です。これは、人間の脳の神経細胞のつながりをまねて作られた計算の仕組みです。従来のものは、与えられた情報をそれぞれバラバラに捉えていましたが、この新しい仕組みは違います。情報を輪のように巡らせることで、過去の情報を覚えておき、今の情報と合わせて考えられるのです。
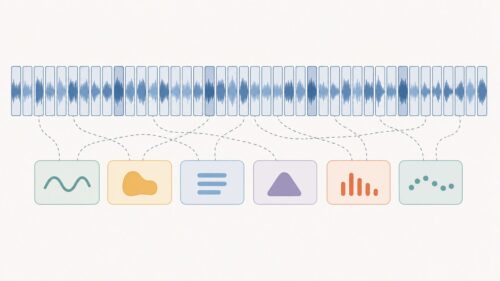
この記憶の仕組みのおかげで、時間とともに変化するデータ、例えば気温の変化や株価の動きなどを理解するのが得意です。文章を例に考えてみましょう。文章は、単語が一つずつ並んでいるだけではなく、それぞれの単語が前後とつながり、意味を作り出しています。「今日は良い天気です。」の後に続く言葉は、「明日はどうでしょうか?」のように、自然と予想できますよね。このように、再帰型ニューラルネットワークは、言葉と言葉のつながりを学び、次に来る言葉を予想したり、文章全体を作ったりすることができるのです。
まるで人間の脳のように、過去の経験を元にして、次に起こることを推測する、それがこの仕組みのすごいところです。例えば、ある言葉を聞くと、次に来る言葉を予測できます。これは、過去の膨大な量の文章データから言葉のつながりを学習しているからです。この学習は、まるで子供が言葉を覚える過程に似ています。子供はたくさんの言葉を聞き、話し、その中で言葉のつながりを理解していきます。再帰型ニューラルネットワークも同じように、大量のデータから学習し、言葉だけでなく、音楽や株価など、様々なデータのパターンを捉え、未来を予測することができるのです。