LSHとは?高次元データの近似最近傍検索を高速化する仕組み

AIの初心者
先生、「LSH」って何ですか?検索を速くするハッシュだと聞きました。

AI専門家
LSHは Locality-Sensitive Hashing の略で、日本語では局所性鋭敏型ハッシュと呼ばれます。近いデータ同士は同じバケットに入りやすく、遠いデータ同士は同じバケットに入りにくいように設計されたハッシュです。
AIの初心者
普通のハッシュとは違うんですか?
AI専門家
普通のハッシュは、似ている入力でもまったく違う値になることがあります。LSHは、似ている入力が同じ場所に集まりやすい性質を使って、高次元ベクトルの近似検索を速くします。
LSHとは
LSHとは、Locality-Sensitive Hashingの略で、近いデータ同士が同じハッシュバケットに入りやすくなるように設計されたハッシュ手法です。画像、文書、時系列、ゲノムなどの高次元ベクトルに対して、厳密な最近傍ではなく近似最近傍を高速に探すために使われます。高次元ではk-d treeやR-treeのような空間分割インデックスが効きにくくなるため、LSHはハッシュベースの有力な代替手段になります。
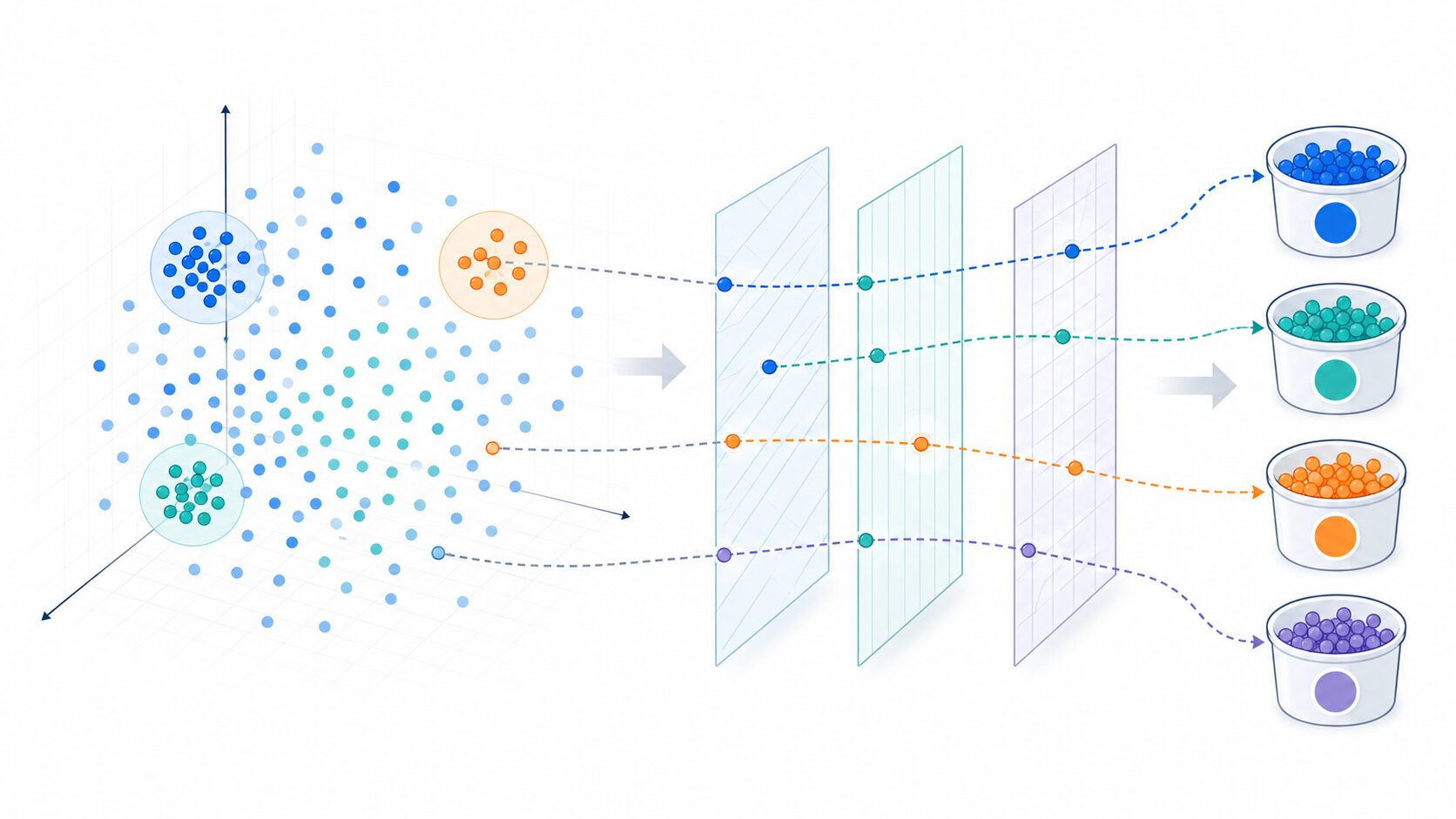
LSHとは
LSHとは、近い点ほど同じバケットに入りやすいハッシュ関数を使う検索手法です。正式には Locality-Sensitive Hashing といい、日本語では局所性鋭敏型ハッシュと訳されます。
通常のハッシュ関数は、入力をできるだけ均等に散らすことを目的にします。そのため、似ている入力でも、まったく別のハッシュ値になることがあります。これは辞書やデータベースのキー検索では便利ですが、類似検索には向きません。
LSHでは、距離が近いデータ同士は同じハッシュ値になりやすく、距離が遠いデータ同士は同じハッシュ値になりにくいようなハッシュ関数族を使います。検索時には、クエリと同じバケットに入ったデータだけを候補として調べるため、全件比較を避けられます。
| 用語 | 意味 |
|---|---|
| LSH | 近いデータを同じバケットに入れやすくするハッシュ手法。 |
| バケット | 同じハッシュ値を持つデータを格納する場所。 |
| 近似最近傍検索 | 厳密な最近傍ではなく、十分近い点を高速に探す検索。 |
| 高次元データ | 画像特徴量、文書ベクトル、時系列特徴量のように多くの次元を持つデータ。 |
なぜLSHが必要なのか
画像、文書、時系列、ゲノムなどのデータは、多くの場合、高次元ベクトルとして表現されます。たとえば画像なら色ヒストグラムやテクスチャ特徴量、文書なら単語や埋め込みベクトル、ゲノムなら配列特徴量として扱えます。
このようなデータから「クエリに似ているもの」を探すには、最近傍検索が必要です。しかし、データ数や次元数が大きくなると、すべての点との距離を計算する全件探索は重くなります。
従来は、k-d treeやR-treeのような空間分割インデックスが使われてきました。低次元では有効ですが、次元が高くなると空間分割の効率が落ち、結局ほぼ全件探索に近くなることがあります。この問題は次元の呪いとして知られています。
LSHは、この問題に対して、厳密な最近傍ではなく近似最近傍でよい場面に注目します。少しだけ誤差を許容する代わりに、検索時間を大きく短縮することを目指します。
| 方法 | 特徴 | 高次元での課題 |
|---|---|---|
| 全件探索 | すべての点と距離を計算する。 | データ数が増えると遅い。 |
| k-d tree | 空間を軸に沿って分割する。 | 高次元では分割の効果が落ちやすい。 |
| R-tree系 | 領域を階層的に管理する。 | 高次元では候補領域が増えやすい。 |
| LSH | 近い点が同じバケットに入りやすいハッシュを使う。 | 近似解になるため精度との調整が必要。 |
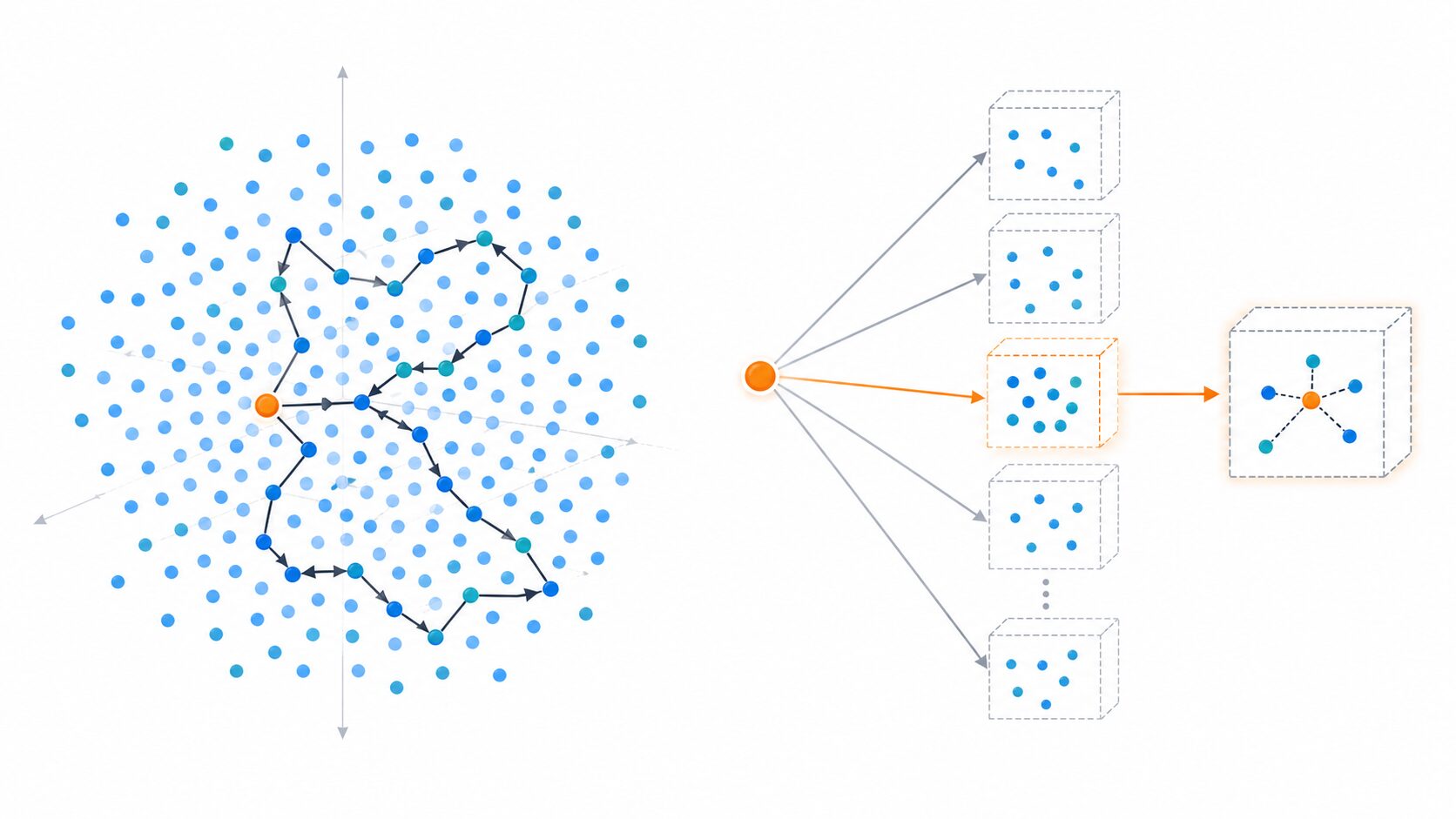
主要アイデア
LSHの中心的な考え方は、シンプルです。近い点同士は同じバケットに入りやすく、遠い点同士は同じバケットに入りにくいハッシュ関数を使います。
普通のハッシュでは、入力が少し違うだけでハッシュ値が大きく変わることがあります。これは衝突を避けたい用途では望ましい性質です。しかし、類似検索では、似ているものが別々の場所に散ってしまうと探しにくくなります。
LSHでは、距離構造をある程度保ったままデータをハッシュ化します。検索時には、クエリ点を同じハッシュ関数でハッシュし、同じバケットに入った点だけを候補として取り出します。その候補集合に対してだけ距離を計算すればよいため、検索を高速化できます。
| 観点 | 通常のハッシュ | LSH |
|---|---|---|
| 目的 | 入力を均等に散らす。 | 近い入力を同じ場所に集めやすくする。 |
| 似た入力 | 別のハッシュ値になることが多い。 | 同じバケットに入りやすい。 |
| 主な用途 | 辞書、キャッシュ、重複排除。 | 類似検索、近似最近傍検索。 |
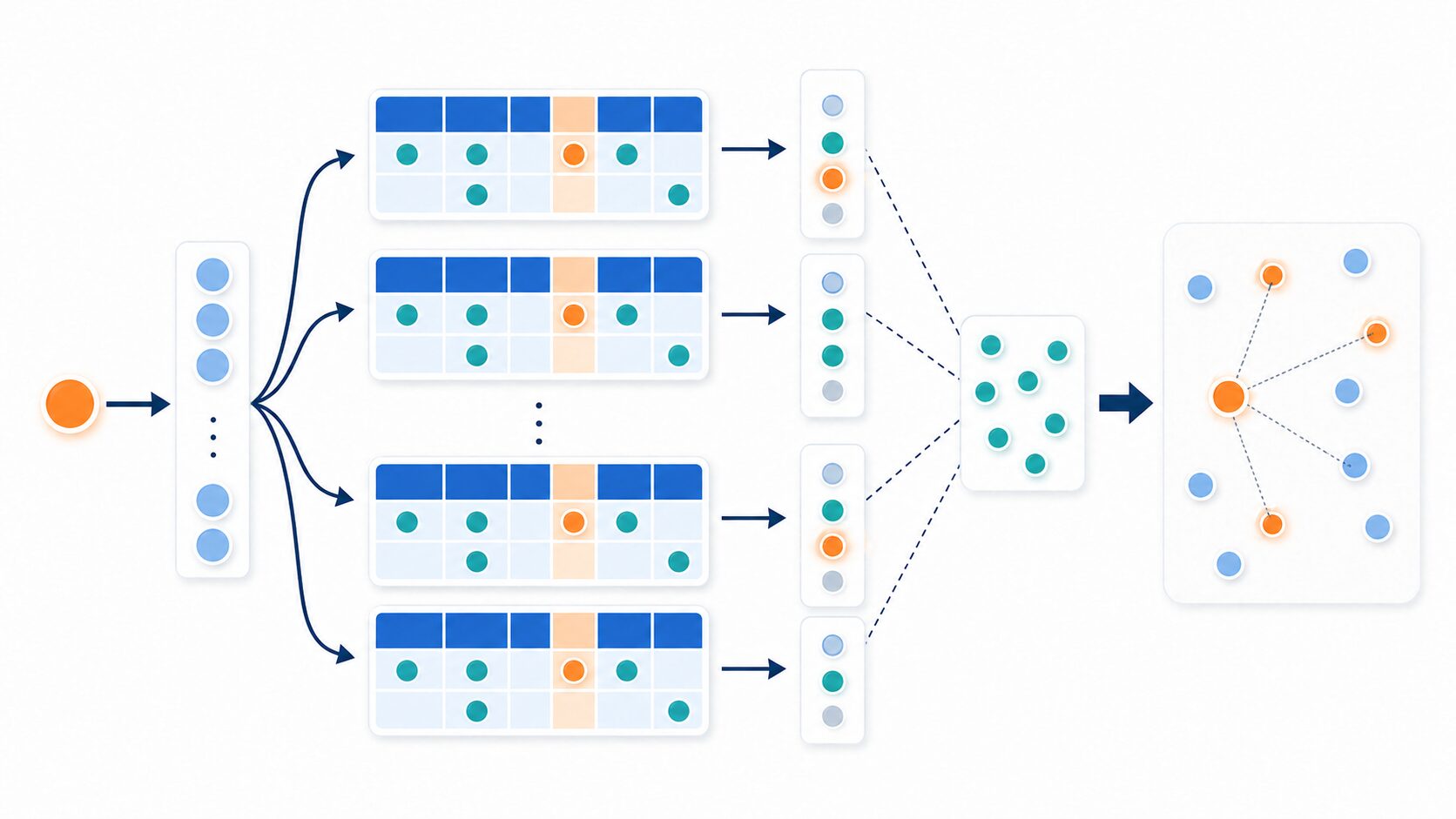
アルゴリズムの流れ
LSHでは、前処理として複数のハッシュテーブルを作ります。1つのハッシュテーブルだけでは、たまたま近い点が別のバケットに入る可能性があります。そこで複数のテーブルを使い、どこかのテーブルで同じバケットに入った点を候補として拾いやすくします。
基本的な流れは、まずランダムに選んだ座標集合やランダムなハッシュ関数を使って各点をハッシュ化し、それぞれを複数のハッシュテーブルの対応バケットに格納するというものです。実装上は、LSHで得られたバケット識別子をさらに通常のハッシュで圧縮して管理することもあります。
検索時には、クエリ点を各ハッシュテーブルで同じようにハッシュ化します。同じバケットに入っている点を候補として集め、その候補集合だけに対して実際の距離を計算します。最後に、距離が近い点を近似最近傍として返します。
| 段階 | 処理 | 目的 |
|---|---|---|
| 前処理1 | ランダムに座標集合やハッシュ関数を選ぶ。 | 距離を反映するハッシュを作る。 |
| 前処理2 | 各データ点を複数のハッシュテーブルへ格納する。 | 近い点を候補として取り出せるようにする。 |
| 検索1 | クエリ点を同じハッシュ関数でハッシュする。 | 見るべきバケットを決める。 |
| 検索2 | 同じバケットの点を候補として集める。 | 全件比較を避ける。 |
| 検索3 | 候補集合の中で距離を計算する。 | 近い点を返す。 |
対象とする距離
LSHは、対象とする距離や類似度に合わせて設計します。代表的な距離の一つが l1 距離です。l1 距離は、各次元の差の絶対値を足し合わせる距離で、マンハッタン距離とも呼ばれます。
また、ハミング距離上のLSHもよく使われます。ハミング距離は、2つのビット列で異なる位置の数を数える距離です。ビット列や集合的な特徴を扱う場面では、ハミング距離で近さを考えると分かりやすくなります。
実務では、l1距離、l2距離、コサイン類似度、Jaccard類似度など、扱うデータの性質に合わせてハッシュ関数族を選びます。どの距離でも同じLSHを使えばよいわけではありません。
| 距離 | 意味 | 例 |
|---|---|---|
| l1 距離 | 各次元の差の絶対値を足し合わせる距離。 | |x1 – y1| + |x2 – y2| + … |
| ハミング距離 | ビット列の異なる位置の数。 | 1010 と 1110 の距離は1。 |
| コサイン類似度 | ベクトルの向きの近さを見る指標。 | 文書ベクトルや埋め込みベクトルの検索。 |
近似最近傍の定義
LSHが扱うのは、厳密な最近傍検索ではなく近似最近傍検索です。厳密な最近傍検索では、クエリ q に対して、データ集合 P の中で最も距離が小さい点を必ず返す必要があります。
一方、近似最近傍検索では、真の最近傍より少し遠い点でも、許容範囲内なら正解とみなします。厳密な最近傍距離を d(q, P) としたとき、返す点 p が次を満たせばよい、という考え方です。
d(q, p) <= (1 + ε) d(q, P)
ここで ε は許容する誤差の大きさです。ε が小さいほど厳密解に近くなりますが、検索は重くなりやすくなります。ε を大きくすると、多少遠い点も許容する代わりに、高速化しやすくなります。
| 検索の種類 | 返す点 | 特徴 |
|---|---|---|
| 厳密最近傍検索 | 最も近い点を必ず返す。 | 精度は高いが、高次元では重くなりやすい。 |
| 近似最近傍検索 | 真の最近傍から一定範囲内の点を返す。 | 少しの誤差を許容して高速化する。 |
計算量の考え方
LSHでは、近い点と遠い点で衝突確率が変わるようなハッシュ関数族を使います。近い点は高い確率で同じバケットに入り、遠い点は低い確率でしか同じバケットに入りません。
ハッシュ関数の個数やハッシュテーブルの数などのパラメータを適切に選ぶと、高次元データでも全件探索より少ない候補だけを調べられます。このように、データ数 n に対して O(n) より少ない候補を見る検索は、サブリニア時間の検索として説明されることがあります。
ただし、LSHは常に高速になるわけではありません。バケットに候補が多く入りすぎると、結局多くの距離計算が必要になります。反対に、ハッシュを細かくしすぎると、近い点まで別バケットに分かれて見逃しやすくなります。速度と精度のバランスを取ることが重要です。
従来のインデックスとの違い
LSHは、k-d treeやR-treeのような木構造インデックスとは考え方が違います。木構造インデックスは、空間を分割して探索範囲を絞り込みます。一方、LSHはハッシュによって候補点を集めます。
低次元のデータでは、木構造インデックスが有効なことがあります。しかし、高次元になると、分割した領域同士の距離が区別しにくくなり、探索範囲が広がりやすくなります。その結果、全件探索に近い処理になることがあります。
LSHは、厳密な最近傍を必ず返す代わりに、近似解を高速に返すことを目指します。つまり、精度を少し緩めることで、検索時間を短くする手法です。大規模な類似検索では、このトレードオフが実用上有効になることがあります。
| 方法 | 検索の考え方 | 特徴 |
|---|---|---|
| k-d tree | 軸に沿って空間を分割する。 | 低次元では有効だが、高次元では効きにくいことがある。 |
| R-tree系 | 領域を階層的に管理する。 | 高次元では候補領域が増えやすい。 |
| LSH | 近い点が同じバケットに入りやすいハッシュを使う。 | 近似解を許容して候補点を高速に絞り込む。 |
LSHが向いている場面
LSHは、完全に正確な最近傍が必要な場面よりも、十分似ているデータを高速に見つけたい場面に向いています。画像検索、文書検索、類似ユーザー検索、推薦、重複候補の抽出などでは、厳密な最近傍でなくても実用上問題ないことがあります。
また、データが高次元で、従来の木構造インデックスが効きにくい場合にもLSHは候補になります。全データを比較する前に、LSHで候補を絞り込み、その後に正確な距離計算やランキングを行う構成がよく使われます。
一方で、LSHにはストレージやパラメータ調整のコストがあります。複数のハッシュテーブルを持つため、単純な全件データ保存よりも余分な領域が必要です。また、ハッシュ関数の数やテーブル数をどう選ぶかによって、速度と精度のバランスが変わります。
| 向いている場面 | 理由 |
|---|---|
| 画像・文書の類似検索 | 特徴ベクトルが高次元になりやすく、近似解でも実用的なことが多い。 |
| 大規模データの候補抽出 | 全件比較の前に候補を絞り込める。 |
| 推薦・重複検出 | 完全一致ではなく、似ている候補を高速に探したい。 |
| 高次元ベクトル検索 | k-d treeやR-treeが効きにくい状況で代替手段になる。 |
理解するときの注意点
LSHは、何でも高速にする万能なハッシュではありません。距離の種類に応じて適切なLSHの設計が必要です。l1距離、l2距離、コサイン類似度、Jaccard類似度など、対象とする距離や類似度によって使うハッシュ関数は変わります。
また、LSHは近似検索です。検索結果が真の最近傍と一致しないことがあります。そのため、精度を重視する場面では、候補数を増やす、複数テーブルを使う、最後に厳密な距離計算で再ランキングするなどの工夫が必要です。
さらに、LSHは追加ストレージを使います。複数のハッシュテーブルに同じ点を登録するため、検索時間を短くする代わりにメモリやディスク容量が増えます。実用では、速度、精度、ストレージのトレードオフを見ながら調整します。
| 注意点 | 内容 |
|---|---|
| 近似解である | 必ず真の最近傍を返すとは限らない。 |
| 距離に依存する | 対象距離に合うハッシュ関数族を選ぶ必要がある。 |
| ストレージを使う | 複数テーブルに登録するため追加領域が必要になる。 |
| パラメータ調整が必要 | ハッシュ関数の数やテーブル数で速度と精度が変わる。 |
まとめ
LSHは、高次元データに対する近似最近傍検索を高速化するためのハッシュ手法です。近い点同士は同じバケットに入りやすく、遠い点同士は同じバケットに入りにくいようなハッシュ関数を使います。
k-d treeやR-tree系のインデックスは、高次元で劣化しやすいことがあります。LSHは、そのような場面で、少しの誤差と追加ストレージを許容することで検索時間を改善するための手法です。
一言でいえば、LSHは「高次元ベクトル検索では厳密な最近傍探索が重すぎるため、近いものが同じバケットに入りやすいハッシュを使って、近似的に高速検索する」ための代表的な手法です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2026年4月25日 | LSHの定義、必要とされる背景、主要アイデア、アルゴリズム、対象距離、近似最近傍の定義、計算量の考え方、従来のインデックスとの違い、注意点を整理した新規記事案を作成しました。 |