次元の呪いを解き放つ
たくさんの情報があれば、より的確な予想ができる。これは、誰もが当然のことのように思うでしょう。機械学習の世界でも、データに含まれる情報が多ければ多いほど、精度の高い予測ができると考えがちです。しかし、実際はそう単純ではありません。
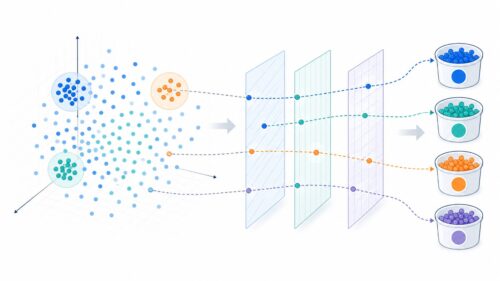
データが持つ情報の量を表す指標の一つに、次元があります。次元とは、データの特徴を表す変数の数のことです。たとえば、りんごの大きさ、色、甘さ、酸味などを変数として考えると、これらの変数の数が次元に当たります。次元が増えると、データの情報量は増えるように思えますが、実際には落とし穴があります。これが「次元の呪い」と呼ばれる現象です。
一見すると、多くの情報を持つ高次元データは、宝の山のように見えます。しかし、次元が増えると、データ空間、つまりデータが存在する範囲は、驚くほどの速さで広がっていきます。たとえるなら、次元が一つ増えるごとに、データ空間の体積は、ある一定の比率で急激に大きくなるようなものです。このため、たとえ大量のデータを集めたとしても、広がりきったデータ空間を埋め尽くすには全く足りません。まるで、広大な砂漠に、まばらに砂粒が散らばっているような状態です。
このようなまばらなデータでは、機械学習のモデルは全体像を把握することができません。学習データに限りなく近いデータであれば、ある程度の予測はできますが、少し異なるデータになると、予測精度が著しく低下してしまいます。例えるなら、りんごの大きさ、色、甘さだけを学習したモデルは、酸味が異なるりんごについては、正しい予測ができなくなるかもしれません。つまり、データが多ければ良いという常識とは逆に、高次元データは機械学習モデルの性能を低下させることがあるのです。この現象こそが、次元の呪いと呼ばれるものであり、機械学習において克服すべき重要な課題の一つです。
 アルゴリズム
アルゴリズム  学習
学習