ローカルLLMとは?自分のPCや社内環境でLLMを動かす方法

AIの初心者
「ローカルLLM」という言葉を見かけました。ChatGPTのようなAIと何が違うのでしょうか?

AI専門家
ローカルLLMは、インターネット上のAIサービスに毎回問い合わせるのではなく、自分のPCや社内サーバーなど手元の環境で大規模言語モデルを動かす考え方です。
AIの初心者
社内文書を扱うなら便利そうですが、初心者でも使えるものですか?必要なPCスペックも気になります。
AI専門家
最近は小型モデルや量子化モデル、ローカル実行ツールが増え、試しやすくなっています。ただし「ローカルなら安全」「無料で高性能」と単純には言えません。この記事で定義、仕組み、使いどころ、注意点を順番に整理しましょう。
ローカルLLMとは。
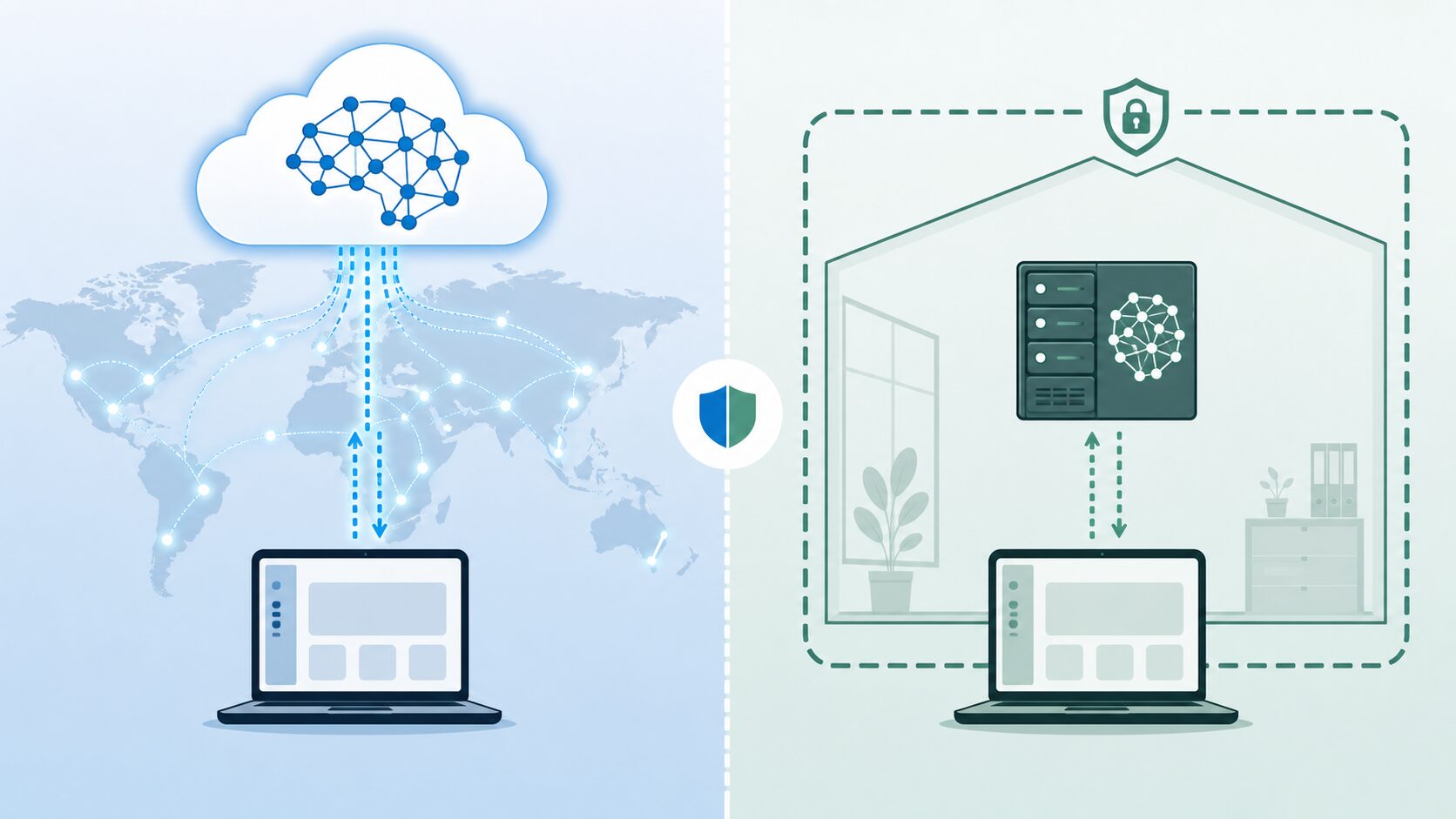
ローカルLLMとは、LLM(大規模言語モデル)をクラウド上のAPIだけで利用するのではなく、自分のPC、社内サーバー、閉域ネットワーク、専用端末などの管理できる環境に配置して動かす方法です。入力した文章や参照データを外部サービスへ送らずに処理しやすい点が特徴で、情報管理、オフライン利用、社内向けAI活用などで注目されています。

生成AIの活用が広がるにつれ、「便利なクラウドAIを使えば十分なのか」「社内データを扱うなら自社環境で動かすべきなのか」という判断が重要になっています。ローカルLLMは、その判断で必ず出てくる選択肢のひとつです。クラウド型のLLMは、ブラウザやAPIからすぐ使える手軽さがあります。一方でローカルLLMは、準備や運用の手間が増えるかわりに、データの置き場所や実行環境を自分たちで管理しやすくなります。
この記事では、ローカルLLMの意味を初心者向けに説明したうえで、クラウドLLMとの違い、必要なPCスペック、導入の流れ、メリットとデメリット、セキュリティ上の注意点、関連用語との違いまでまとめます。単語の定義だけでなく、実際に使う前に何を確認すべきかまで理解できるように整理します。
ローカルLLMの基本的な意味
ローカルLLMを理解するには、まず「LLM」と「ローカル」を分けて考えると分かりやすくなります。LLMは、大量のテキストから言語のパターンを学習し、質問への回答、文章の要約、翻訳、分類、コード生成などを行うAIモデルです。ローカルは、ここでは自分の管理下にあるPCやサーバー、社内ネットワークを指します。つまりローカルLLMは、言語モデルの推論処理を自分たちの環境で実行する仕組みです。
クラウド型の生成AIでは、利用者が入力したプロンプトはインターネット経由でサービス提供者のシステムに送られ、そこでAIが回答を作ります。ローカルLLMでは、モデルファイルと実行ソフトウェアを手元の環境に置き、入力文をその環境内で処理します。たとえば、個人のPCに小型の日本語対応モデルを入れて文章要約に使う場合も、社内サーバーにモデルを載せて従業員向けのチャットAIとして使う場合も、広い意味ではローカルLLMの活用に含まれます。
ただし、ローカルLLMは「完全にインターネットを使わないAI」という意味だけではありません。モデルのダウンロード、アップデート、周辺ツールの導入、社内システムとの連携ではネットワークを使うことがあります。重要なのは、実際の入力データや推論処理をどこで扱うかです。機密文書や顧客情報を外部のAIサービスに送らず、社内の管理ルールに沿って処理したい場合、ローカルLLMは有力な選択肢になります。
ローカルLLMの基本構成
ローカルLLMは、単に「AIモデルをダウンロードする」だけでは動きません。基本的には、モデル、実行環境、利用インターフェース、データ、運用ルールの組み合わせで成り立ちます。モデルは回答を生成する中核です。実行環境は、そのモデルをPCやサーバー上で動かすためのソフトウェアです。利用インターフェースは、チャット画面、API、社内ポータル、開発ツールなど、利用者がAIにアクセスする入口です。

たとえば個人で試す場合は、ノートPCにローカルLLM実行ツールを入れ、公開されている小型モデルを読み込み、チャット画面から質問する構成になります。企業で使う場合は、GPUを搭載した社内サーバーにモデルを置き、社員が社内Webアプリから利用し、ログやアクセス権限を管理する構成が考えられます。さらに社内文書検索と組み合わせるなら、文書をベクトル化して検索し、見つかった情報をLLMに渡すRAGの仕組みも加わります。
ここで大切なのは、ローカルLLMの品質はモデルだけで決まらないという点です。どのモデルを選ぶか、どのサイズを動かすか、量子化でどれくらい軽くするか、参照する文書をどう整備するか、回答をどう評価するかによって、実用性は大きく変わります。特に業務利用では、AIの回答そのものよりも、入力データの管理、利用者権限、誤回答時の確認フロー、ログの扱いが重要になることがあります。
クラウドLLMとの違い
ローカルLLMと比較される代表的なものがクラウドLLMです。クラウドLLMは、外部のAIサービスが提供するモデルをブラウザやAPI経由で使う方式です。利用者は大規模なGPUサーバーを用意しなくても、高性能なモデルをすぐに利用できます。導入の速さ、モデル性能、運用負担の少なさではクラウドLLMが有利な場面が多くあります。
一方、ローカルLLMはモデルを自分の環境で動かすため、入力データを外部サービスへ送らない設計にしやすくなります。通信制限がある現場、閉域網で動かしたい業務、社外秘の文章を扱う作業、利用量が多くAPI料金を予測しにくい用途では、ローカルLLMのほうが検討しやすい場合があります。ただし、サーバー調達、モデル選定、アップデート、セキュリティ対策、障害対応は利用者側の責任になります。
| 観点 | クラウドLLM | ローカルLLM |
|---|---|---|
| 導入のしやすさ | アカウントやAPIキーで始めやすい | モデル、実行環境、ハードウェアの準備が必要 |
| データ管理 | 外部サービスの規約や設定確認が必要 | 社内環境に閉じた設計にしやすい |
| 性能 | 最新の大規模モデルを使いやすい | 手元のハードウェアとモデルサイズに左右される |
| 費用 | 利用量に応じたAPI料金が中心 | 初期費用、電力、保守、運用人件費が発生する |
| 運用責任 | 基盤運用はサービス提供者に依存できる | 更新、監視、障害対応を自分たちで考える必要がある |
初心者が誤解しやすいのは、ローカルLLMが常にクラウドLLMより優れているわけではない点です。最新の高性能モデルを安定して使いたい、法務や情報管理の整理ができている、まず短期間で効果検証をしたいという場合は、クラウドLLMのほうが合理的なこともあります。逆に、機密性、閉域運用、カスタマイズ、長期的な費用管理が重要な場合は、ローカルLLMを検討する価値が高くなります。
ローカルLLMが注目される背景
ローカルLLMが注目される背景には、生成AIの普及と同時に、データ管理への関心が高まったことがあります。企業では、顧客情報、契約書、議事録、設計資料、ソースコード、研究データなど、外部サービスへ送る前に慎重な判断が必要な情報が多くあります。生成AIを使いたい一方で、入力データの扱いが不安で利用が進まないという状況は珍しくありません。
また、オープンなLLMや小型モデルの性能が向上し、個人のPCや社内サーバーでも実用的なタスクをこなせるようになってきました。以前は大規模なGPU環境がなければ難しかった処理も、モデルの軽量化や量子化によって、比較的身近なハードウェアで試せるケースが増えています。もちろん、クラウドの最先端モデルと同等の性能を簡単に出せるわけではありませんが、用途を絞れば十分に役立つ場面があります。
さらに、AIを単発の便利ツールではなく、社内業務に組み込む段階になると、権限管理、監査ログ、費用予測、システム連携、業務フローとの整合性が重要になります。ローカルLLMは、こうした要件を自社のIT環境に合わせて設計しやすい点で注目されています。特に、金融、医療、製造、法律、研究開発、自治体など、扱う情報の制約が大きい領域では検討対象になりやすい技術です。
ローカルLLMでできること
ローカルLLMでできることは、基本的にはLLMが得意とする自然言語処理です。文章の要約、分類、言い換え、翻訳、質問応答、メールの下書き、議事録の整理、コードの説明、FAQの草案作成などが代表例です。クラウドLLMと比べてモデル性能が控えめな場合でも、定型的な文章処理や社内文書の一次整理であれば十分に役立つことがあります。
企業で分かりやすい例は、社内規程やマニュアルの検索補助です。従業員が「出張精算の締切はいつか」「この申請にはどの書類が必要か」と質問し、ローカルLLMが社内文書を参照しながら回答案を出す仕組みを作れます。この場合、LLM単体にすべてを記憶させるのではなく、RAGと呼ばれる検索拡張生成の仕組みを組み合わせると、社内文書に基づいた回答を作りやすくなります。
開発現場では、ソースコードの説明、テストケースの草案、エラーメッセージの整理、ドキュメント作成補助などに使えます。自社コードを外部サービスに送ることが難しい場合でも、ローカル環境内でAI補助を試せる点は大きな利点です。ただし、コード生成や設計判断をAIに任せきるのは危険です。出力は必ずレビューし、セキュリティやライセンスに関わる箇所は人間が確認する必要があります。
個人利用では、オフラインでの文章作成補助、学習メモの整理、プログラミング学習、長文の下読みなどが考えられます。インターネット接続が不安定な場所でも使える可能性があるため、出張先、研究室、工場、展示会、教育現場などでも応用できます。ローカルLLMは万能なAIではありませんが、扱うデータを自分の手元に置いたまま自然言語処理を行いたい場面で価値を発揮します。
必要なPCスペックとモデルサイズ
ローカルLLMを試すときに多くの人が気にするのがPCスペックです。必要な性能は、使うモデルのサイズ、量子化の有無、同時利用人数、回答速度、扱う文章量によって変わります。小型モデルを個人で試すだけなら一般的なPCでも動く場合がありますが、大きなモデルを快適に動かしたり、複数人で利用したりするにはGPUや十分なメモリが重要になります。

LLMのサイズは、よく「パラメータ数」で表されます。パラメータ数が大きいほど表現力が高くなる傾向がありますが、必要なメモリや計算資源も増えます。たとえば、数十億パラメータ規模の小型モデルであれば個人PCでも試しやすい一方、数百億パラメータ以上のモデルを快適に動かすには高性能なGPUやサーバー環境が必要になることがあります。初心者は、最初から大きなモデルを目指すより、用途に合う小型モデルで動作感をつかむほうが現実的です。
GPUを使うと、LLMの推論速度が大きく改善することがあります。特にVRAMと呼ばれるGPU上のメモリ容量は重要です。モデルをVRAMに載せられない場合、CPUやメインメモリを併用するため速度が落ちることがあります。メインメモリも、モデルファイル、文脈長、周辺処理を含めて余裕を見ておく必要があります。ストレージは、モデルファイルが数GBから数十GBになることがあるため、空き容量と読み込み速度を確認します。
ここで出てくる重要な技術がAI量子化です。量子化とは、モデルの重みをより少ないビット数で表現し、メモリ使用量や計算負荷を減らす方法です。量子化モデルを使うと、比較的軽いPCでも大きめのモデルを動かしやすくなります。ただし、量子化の度合いを強めると精度や回答の安定性が変わることがあります。速さと品質のバランスを確認しながら選ぶことが大切です。
| 項目 | 確認ポイント | 初心者向けの考え方 |
|---|---|---|
| CPU | GPUなしでも動くが速度に影響する | まず試すだけならCPU実行でもよいが、快適さは期待しすぎない |
| メモリ | モデルサイズと文脈長に影響する | 小型モデルでも余裕を持った容量を用意する |
| GPU | 推論速度と同時処理に影響する | 本格運用では重要。VRAM容量を重視する |
| ストレージ | モデルファイルや文書データを保存する | 複数モデルを試すなら空き容量を確保する |
| 量子化 | 軽量化と品質のバランスを調整する | 最初は推奨設定の量子化モデルから試す |
ローカルLLMを導入する基本手順
ローカルLLMの導入は、モデルを入れて終わりではありません。特に業務利用では、目的を決め、データ範囲を整理し、モデルを選び、検証し、運用ルールを作る流れが必要です。最初から全社展開を目指すと失敗しやすいため、まずは用途をひとつに絞った小さな検証から始めるのが現実的です。
第一歩は、何を解決したいのかを明確にすることです。「社内でAIを使いたい」だけでは、モデルも構成も評価方法も決まりません。「問い合わせ対応の下書きを作る」「社内規程を探しやすくする」「開発者が社内コードを説明しやすくする」など、具体的な業務に落とし込みます。目的が明確になると、必要な回答精度、扱うデータ、利用人数、許容できる応答速度が見えてきます。
次に、モデルと実行環境を選びます。日本語を多く扱うなら日本語性能を確認し、プログラミング支援ならコードに強いモデルを検討します。ライセンスも重要です。公開モデルの中には、商用利用、再配布、改変、出力利用に条件があるものがあります。業務で使う場合は、モデルライセンス、データライセンス、社内規程を確認してから利用範囲を決める必要があります。
その後、少量の実データまたはダミーデータで検証します。評価では、回答の正しさだけでなく、分からないときに分からないと言えるか、根拠を示せるか、禁止した情報を出さないか、応答速度が業務に耐えるかを確認します。RAGを使う場合は、検索で正しい文書が取れているかも重要です。LLMの問題に見えて、実際には文書分割や検索設定の問題であることもあります。
最後に、利用者、権限、ログ、監視、更新手順を決めます。誰が使えるのか、どの文書を参照できるのか、入力ログを保存するのか、保存するなら誰が見られるのか、モデルを更新したときに回答品質をどう確認するのかを整理します。ローカルLLMは自社で管理しやすい反面、管理しないと問題も自社内に残ります。技術検証と同じくらい、運用設計が大切です。
ローカルLLMのメリット
ローカルLLMの大きなメリットは、入力データや参照データを管理しやすいことです。外部サービスへ送信しにくい文書を扱う場合、社内ネットワーク内で処理できる設計は安心材料になります。もちろん、ローカル環境に置いただけで自動的に安全になるわけではありませんが、データの保存場所、アクセス権、ログ、ネットワーク接続を自社のルールに合わせやすくなります。
もうひとつのメリットは、カスタマイズ性です。利用するモデル、プロンプト、参照文書、社内システム連携、UIを自分たちの用途に合わせて設計できます。たとえば、社内用語を含む文書検索、部署ごとのナレッジベース、開発チーム専用のコード支援、工場内端末でのマニュアル検索など、業務に合わせたAI体験を作りやすくなります。
費用面でもメリットが出ることがあります。クラウドAPIは使った分だけ料金が発生するため、利用量が増えるほど費用が読みにくくなる場合があります。ローカルLLMでは初期投資や運用費は必要ですが、一定量以上の利用がある場合、費用構造を予測しやすくなることがあります。ただし、ハードウェア、電力、保守、担当者の人件費まで含めて考える必要があります。
オフラインや閉域環境で使える可能性も重要です。工場、研究施設、医療現場、自治体の一部業務など、インターネット接続に制限がある場所では、クラウドAIを前提にしにくい場合があります。ローカルLLMであれば、必要なモデルや文書を事前に配置し、限定された環境内でAI機能を提供できます。これはクラウド型にはない実務上の強みです。
ローカルLLMのデメリットと限界
ローカルLLMにはメリットがある一方で、デメリットも明確です。まず、クラウドの最新大規模モデルと比べると、手元で動かせるモデルは性能が限られることがあります。難しい推論、専門的な文章作成、複雑なコード生成、多言語対応、長い文脈処理では、クラウドLLMのほうが高品質な回答を返す場合があります。ローカルLLMを選ぶときは、性能差を理解したうえで用途を絞る必要があります。
次に、導入と運用の負担があります。モデルの選定、実行環境の構築、GPUドライバ、依存ライブラリ、セキュリティパッチ、障害対応、ログ管理、利用者サポートなど、クラウドサービスでは隠れていた作業を自分たちで扱うことになります。個人で試すだけなら気軽でも、企業で継続運用するには担当体制が必要です。
また、ローカルLLMは正しい情報だけを返すわけではありません。クラウドLLMと同じように、もっともらしい誤回答をすることがあります。社内文書を参照させていても、検索結果が不十分だったり、文書の解釈を誤ったりすれば、回答は間違います。重要な判断に使う場合は、回答の根拠、参照文書、確認者、責任範囲を明確にする必要があります。
「ローカルだから無料」という誤解にも注意が必要です。公開モデル自体を無料で入手できる場合でも、商用利用の条件、サーバー費用、電力、保守、セキュリティ対策、人件費が発生します。モデルを更新し続ける必要もあります。費用比較では、API料金だけでなく、総保有コストとして考えることが大切です。
セキュリティと情報管理の注意点
ローカルLLMを導入する理由として、セキュリティや情報管理を挙げる人は多いです。しかし、ローカル環境で動かすことと安全に運用できることは同じではありません。モデル、データ、ログ、利用端末、ネットワーク、権限管理のどこかに弱点があれば、情報漏えいや不正利用のリスクは残ります。
まず確認したいのは、入力データとログの扱いです。利用者がAIに入力した文章を保存するのか、保存するならどこに保存するのか、誰が閲覧できるのか、どれくらいの期間保持するのかを決めます。機密情報を扱う場合、ログに機密情報が残るだけでもリスクになります。開発段階では便利なデバッグログが、本番運用では問題になることがあります。
次に、参照データの権限管理です。社内文書をRAGで検索させる場合、全社員がすべての文書を参照できる構成にしてしまうと、AIが権限外の情報を回答に含める可能性があります。人事、法務、経営、研究開発などの文書は、文書検索の段階でアクセス権を反映する必要があります。LLMの回答画面だけを制御しても、裏側の検索で権限を無視していれば意味がありません。
モデルやツールのサプライチェーンにも注意します。公開モデルや実行ツールを使う場合、配布元、ライセンス、更新状況、既知の脆弱性を確認します。モデルファイルや周辺コードをどこから取得したか分からない状態で社内環境に入れるのは避けるべきです。特に業務利用では、検証済みの取得ルート、バージョン管理、更新手順を残しておくことが重要です。
さらに、プロンプトインジェクションへの対策も必要です。社内文書やWebページを参照するAIでは、文書内に「前の指示を無視せよ」のような悪意ある指示が含まれる可能性があります。ローカルLLMでもこの問題は起こります。システム指示、参照文書、ユーザー入力の扱いを分け、出力前に機密情報や禁止内容をチェックする仕組みを検討します。
関連用語との違い
ローカルLLMは、オンデバイスAI、プライベートAI、RAG、ファインチューニング、AI量子化などの用語と一緒に出てくることがあります。似ている部分はありますが、指している範囲が異なります。混同すると導入判断を誤りやすいため、違いを整理しておきましょう。
| 用語 | 意味 | ローカルLLMとの関係 |
|---|---|---|
| オンデバイスAI | スマートフォンやPCなど端末上でAI処理を行う考え方 | ローカルLLMの一部として位置づけられる場合がある |
| プライベートAI | 組織の管理下で安全性や権限管理を重視して使うAI | ローカルLLMはプライベートAIを実現する手段のひとつ |
| RAG | 検索した外部知識をLLMに渡して回答させる仕組み | ローカルLLMと組み合わせると社内文書QAを作りやすい |
| ファインチューニング | 既存モデルを追加データで調整する方法 | ローカルで動かすこととは別概念。必要な場合だけ検討する |
| AI量子化 | モデルを軽量化して実行しやすくする技術 | ローカルLLMを一般的なPCで動かす助けになる |
オンデバイスAIは、スマートフォンやノートPCなど端末上でAIを動かすことを広く指します。画像認識、音声認識、予測変換なども含むため、必ずしもLLMに限りません。ローカルLLMは、その中でも大規模言語モデルを対象にしたものと考えると理解しやすいです。
プライベートAIは、技術方式というより運用思想に近い言葉です。データ保護、権限管理、監査、組織内利用を重視したAI活用を指します。ローカルLLMはプライベートAIを実現する手段になり得ますが、クラウドサービスでも契約や設定によってプライベート性を高めることはあります。つまり、プライベートAIとローカルLLMは完全な同義語ではありません。
RAGは、LLMに最新情報や社内情報を参照させるための仕組みです。ローカルLLMに社内規程を覚え込ませるために毎回ファインチューニングするのではなく、検索システムで関連文書を取り出し、その内容をプロンプトに含めて回答させる方法がよく使われます。情報が更新される業務では、RAGのほうが管理しやすいことが多いです。
初心者が小さく試すなら何から始めるか
初心者がローカルLLMを学ぶなら、最初から本格的な社内AI基盤を作ろうとしないことが大切です。まずは個人PCで小型モデルを動かし、どのくらいの速度で、どの程度の回答が返ってくるのかを体験します。次に、要約や分類など失敗しても影響が小さいタスクで試します。いきなり顧客対応や法務判断に使うのは避けるべきです。
学習の順番としては、LLMの基本、プロンプトの作り方、ローカル実行ツール、モデルサイズと量子化、RAG、評価方法の順に理解するとつながりやすくなります。モデルを動かすこと自体はツールの進化で簡単になっていますが、実務で価値を出すには、出力をどう評価し、どの業務に組み込むかを考える必要があります。
企業で検証する場合は、公開しても問題ないダミーデータや限定された社内文書から始めます。検証用の利用者を少人数に絞り、期待する回答例と失敗例を集めます。回答品質、速度、利用ログ、問い合わせ内容、現場の使いやすさを確認し、必要に応じてモデル、プロンプト、検索設定、UIを調整します。PoCの段階で運用負荷も測ると、本番化の判断がしやすくなります。
導入判断のチェックポイント
ローカルLLMを導入するかどうかは、技術的な興味だけで決めないほうがよいです。まず、扱うデータの機密性を確認します。外部サービスに送れない情報を扱うのか、契約上の制限があるのか、社内規程でクラウドAI利用が制限されているのかを整理します。次に、求める回答品質と速度を確認します。ローカルで動かせるモデルが要件を満たせないなら、別の構成を検討する必要があります。
費用比較では、クラウドAPI料金とローカル環境の総費用を比べます。ローカルLLMは、GPUサーバーを買えば終わりではありません。サーバーの保守、電力、監視、バックアップ、セキュリティ対応、担当者の学習コストがかかります。一方で、利用量が多い場合や長期的に社内基盤として使う場合は、ローカルのほうが費用予測しやすいこともあります。
運用体制も重要です。モデルを誰が更新するのか、回答品質を誰が評価するのか、問題が起きたときに誰が止めるのか、利用者からの問い合わせを誰が受けるのかを決めておきます。AI導入は、技術検証だけでなくサービス運用に近い仕事です。継続して使うなら、担当者と責任範囲を明確にする必要があります。
最終的には、ローカルLLM、クラウドLLM、ハイブリッド構成のどれが目的に合うかを選びます。機密性の高い処理はローカル、一般的な文章作成や高度な推論はクラウド、社内文書検索はRAGで補うというように、用途ごとに分ける構成も現実的です。ひとつの方式にこだわるより、データ、性能、費用、運用のバランスで選ぶことが大切です。
ローカルLLMについてよくある誤解
ローカルLLMについては、いくつかの誤解があります。ひとつは「ローカルなら情報漏えいしない」という考えです。外部サービスへ送信しない設計はできますが、社内端末の管理が甘い、ログが無制限に残る、権限外の文書を参照できる、モデルやツールの取得元が不明といった状態では、十分に安全とは言えません。安全性は配置場所ではなく、運用設計で決まります。
次に「ローカルなら無料で使い放題」という誤解です。モデルやツールが無料で公開されていても、商用利用条件、ハードウェア費用、電力、保守、人件費は別です。特に企業利用では、ライセンス確認やセキュリティレビューにも時間がかかります。費用を比較するときは、月額料金だけでなく、導入から運用までの総コストを見ます。
もうひとつは「ローカルLLMを入れれば社内文書をすべて理解してくれる」という誤解です。モデルを置いただけでは、社内文書の中身を自動的に正確に把握するわけではありません。文書を検索できる形に整備し、RAGで必要な情報を取り出し、回答の根拠を確認できるようにする必要があります。社内文書が古い、重複している、権限が整理されていない場合、AI以前に情報管理の問題が表面化します。
まとめ
ローカルLLMとは、LLMを自分のPCや社内サーバーなど管理できる環境で動かす方法です。クラウドLLMと比べると、データを外部へ送らない設計にしやすく、閉域環境や社内文書活用、カスタマイズ性が求められる場面で役立ちます。一方で、モデル性能、ハードウェア、運用負担、セキュリティ対策、ライセンス確認など、利用者側で考えるべきことも増えます。
初心者は、まず「どのデータを扱うのか」「どの業務で使うのか」「クラウドLLMでは何が困るのか」を整理するところから始めるとよいでしょう。ローカルLLMは、生成AI活用の選択肢を広げる技術ですが、目的が曖昧なまま導入しても効果は出にくいです。小さく試し、回答品質と運用負荷を確認しながら、必要に応じてRAG、量子化、権限管理、社内システム連携を組み合わせることが現実的な進め方です。
ローカルLLMを正しく理解すると、クラウドAIを使うべき場面、自社環境で動かすべき場面、両方を組み合わせるべき場面を判断しやすくなります。AIを安全かつ実務的に活用するためには、技術そのものだけでなく、データ、業務、運用、責任範囲まで含めて設計することが重要です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2026年5月4日 | 初回公開 |