ベンチマーク:性能評価の要

AIの初心者
先生、「ベンチマーク」ってよく聞くんですけど、AIの分野ではどういう意味で使われているんですか?

AI専門家
そうですね、AI、特にLLMの分野では「ベンチマーク」はAIモデルの性能を測るためのテストのようなものと考えてください。色々な問題を用意して、AIがどれくらいうまく答えられるかを評価します。例えば、文章を作ってとお願いしたり、質問に答えさせたりします。
AIの初心者
なるほど、テストみたいですね。テストの種類も色々あるんですか?
AI専門家
はい、そうです。テストの種類もたくさんあって、それぞれ得意不得意があるので、AIの性能を測るには色々なテストで試してみる必要があります。例えば、計算問題が得意なAIもいれば、文章を書くのが得意なAIもいるので、色々なテストで総合的に評価することで、AIの得意なことを知ることができるのです。
ベンチマークとは。
人工知能の性能を測るための『基準』について説明します。この基準は、様々な人工知能の性能を比べたり、良し悪しを判断したりする時に使われます。基準には、テストに使うデータや課題など、色々な要素が含まれており、これらに基づいて性能を評価します。コンピューターや色々なソフトの評価にも使われますが、特に文章を理解したり、作ったりする人工知能の分野では、質問に答えたり、文章を書いたりといった様々なテストがあります。このような基準はたくさん作られており、基準の種類によって点数が変わってきます。
ベンチマークとは

ものごとの良し悪しや性能の高低を測るには、何かしら基準となるものが必要です。この基準となるものを、私たちは「ベンチマーク」と呼びます。まるで、長さを測る物差しや重さを測る秤のように、ベンチマークは様々なものの性能を測り、比べるための土台となるものです。どれくらい優れているのか、他のものと比べてどのくらいの差があるのかを、感情に左右されず、誰から見ても同じように判断できるようにしてくれます。
この判断をより確かなものとするために、ベンチマークは特定の作業や課題に対する成果を数値で表すことを重視します。例えば、計算機の処理速度を測る場合、決められた計算問題を解くのにどれくらいの時間がかかるかを数値で記録します。また、文字を書く道具の使いやすさを比較する場合には、一定の文字数を書き写すのにかかる時間や、書いた文字の美しさなどを数値化して評価します。最近では、人間のように文章を書くことができる大規模言語モデルの性能を評価する際にも、ベンチマークが活用されています。文章の自然さや内容の正確さなどを数値化することで、どのモデルがより優れた文章を書けるのかを客観的に判断できるのです。
ベンチマークは、様々な場面で役立ちます。例えば、新しい製品を開発する際、現在の製品と比べてどの部分が改善されたのかを確認するために用いられます。また、数ある製品の中から自分に合ったものを選ぶ際にも、ベンチマークを参考にすれば、それぞれの製品の性能を比較検討し、最適な選択をすることができます。このように、ベンチマークはものごとの性能を測るだけでなく、製品開発の改善や、私たちがより良い選択をするためにも役立っているのです。
| ベンチマークの役割 | 具体的な例 |
|---|---|
| ものごとの良し悪しや性能の高低を測る基準 | 物差し、秤 |
| 性能の測定と比較の土台 | 計算機の処理速度、文字を書く道具の使いやすさ、大規模言語モデルの性能 |
| 客観的な判断を可能にする | 計算時間、文字の美しさ、文章の自然さや正確さの数値化 |
| 製品開発における改善の確認 | 新製品と現行製品の比較 |
| 最適な製品選択の支援 | 製品性能の比較検討 |
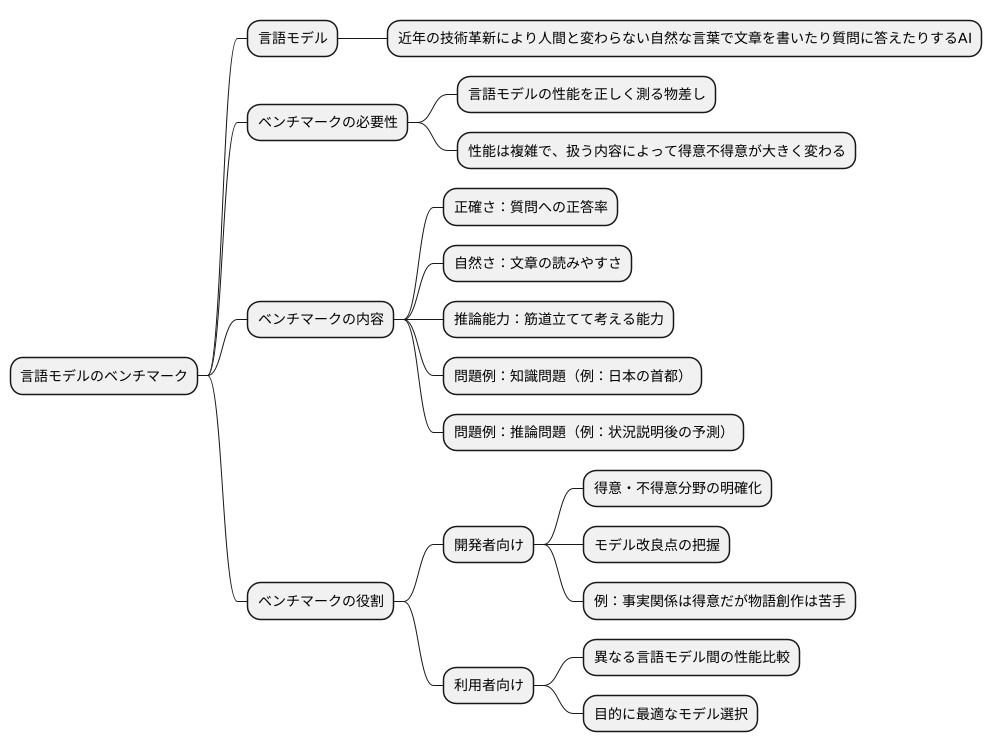
大規模言語モデルにおけるベンチマーク

近年の技術革新により、人間と変わらない自然な言葉で文章を書いたり、質問に答えたりする人工知能、大規模言語モデル(言語モデル)が注目を集めています。この言語モデルは、膨大な量の文章情報を学習することで、様々な言葉の作業をこなせるようになりました。しかし、その性能は複雑で、扱う内容によって得意不得意が大きく変わることがあります。そこで、言語モデルの性能を正しく測るための物差し、すなわち評価基準が必要となります。これが「ベンチマーク」と呼ばれるものです。
ベンチマークは、言語モデルがどれほど正確に質問に答えられるか、どれほど自然で読みやすい文章を書けるか、どれほど筋道立てて考えられるか、といった様々な側面を評価するために作られます。具体的には、様々な問題を解かせ、その正答率や回答の質を数値化することで性能を測ります。例えば、「日本の首都はどこですか?」といった知識を問う問題や、「ある状況を説明した上で、次に何が起こるかを予測しなさい」といった推論能力を測る問題など、多様な問題が出題されます。
これらのベンチマークは、言語モデルの開発にとって非常に重要な役割を担っています。まず、ある言語モデルの得意な分野と苦手な分野を明らかにすることで、開発者はそのモデルの改良点を把握することができます。例えば、あるモデルが事実に関する質問には正確に答えられるのに、物語の創作が苦手だと分かれば、物語生成能力の向上に開発の重点を置くことができます。また、異なる言語モデル間で性能を比較することも可能です。これにより、利用者は自分の目的に最適な言語モデルを選ぶことができます。まるで商品を選ぶように、それぞれのモデルの性能を比較検討し、最も適したものを選ぶことができるのです。このように、ベンチマークは言語モデルの開発と利用の両面で、なくてはならないものとなっています。
多様なベンチマークの種類

様々な用途に合わせた多くの評価基準(ベンチマーク)があり、それぞれ異なる評価のやり方や評価に使うデータを使っています。
例えば、ある評価基準では質問に正しく答えられるかを重視しますが、別の評価基準では文章をどれくらいうまく作れるかを評価するかもしれません。また、特定の分野に絞った評価基準もあります。医療の分野の評価基準であれば、医療に関する質問に適切に答えられるかを測ることに重点を置いています。
他にも、常識的な考え方ができるかを試す評価基準や、論理的に考える力を測る評価基準もあります。また、新しい文章を作る能力を評価するものや、与えられた文章を要約する能力を見るものもあります。さらに、複数の言語を理解し、それらを翻訳する能力を測る評価基準も存在します。
このように、様々な評価基準があることで、色々な角度から、高度な言語モデルの性能を詳しく調べることができます。どの評価基準を使うかによって、同じ高度な言語モデルでも評価結果が変わることがあるので、目的に合った評価基準をきちんと選ぶことが重要です。たくさんの評価基準を組み合わせることで、より正確に性能を把握することができます。
| 評価基準の分類 | 評価内容 | 具体例 |
|---|---|---|
| 正答能力 | 質問への正答率 | 質問に正しく答えられるか |
| 文章生成能力 | 文章の質、流暢さ | 文章をどれくらいうまく作れるか |
| 専門知識 | 特定分野の知識 | 医療に関する質問に適切に答えられるか |
| 常識推論能力 | 常識的な考え方 | 常識的な考え方ができるか |
| 論理的思考力 | 論理的思考能力 | 論理的に考える力 |
| 文章生成能力 | 新規文章作成能力 | 新しい文章を作る能力 |
| 要約能力 | 文章要約能力 | 与えられた文章を要約する能力 |
| 多言語能力 | 多言語理解・翻訳能力 | 複数の言語を理解し、それらを翻訳する能力 |
ベンチマークの構成要素

評価の基準となるベンチマークは、いくつかの重要な要素から成り立っています。まず欠かせないのが、評価の対象となるデータの集まりです。これは、まるで試験問題のように、様々な課題や質問、そして模範解答となる正しい答えが用意されている必要があります。データの内容は、ベンチマークが何を目指しているのかによって、それぞれに合ったものが選ばれます。例えば、ある文章の内容を理解する能力を測りたいのか、それとも新しい文章を作る能力を測りたいのかによって、データの内容は大きく変わるでしょう。
次に、評価の尺度となる評価指標が必要です。これは、様々な角度からモデルの能力を数値で表すためのものです。例えば、解答の正しさの割合を測る「正確さ」や、答えを出すまでの時間を測る「速度」、様々な答えを出せるかどうかを測る「多様性」など、目的に合わせて様々な指標が使われます。これらの指標は、まるで定規のように、モデルの性能を測るための具体的な数値を提供してくれます。
最後に、評価の手順を定めた評価方法が必要です。これは、前述の評価指標を用いて、モデルの解答をどのように採点するのかを具体的に定めたものです。手順が明確でなければ、同じモデルでも評価する人によって結果が変わってしまう可能性があります。評価方法は、採点基準を明確にすることで、評価の公平性と客観性を保証する重要な役割を担っています。
これらの要素、つまり評価対象となるデータ、評価の尺度となる指標、そして評価の手順が揃うことで、初めて信頼できる客観的な性能評価が可能になります。まるで健康診断のように、これらの要素が揃って初めて、モデルの健康状態、つまり性能を正確に診断できるのです。
| 要素 | 説明 | 例 |
|---|---|---|
| 評価対象となるデータ | 試験問題のように、様々な課題や質問、そして模範解答となる正しい答えが用意されているもの。ベンチマークの目的に合わせてデータの内容が変わる。 | 文章理解能力を測るための文章データ、文章生成能力を測るための文章データ |
| 評価の尺度となる評価指標 | 様々な角度からモデルの能力を数値で表すためのもの。 | 正確さ、速度、多様性 |
| 評価の手順を定めた評価方法 | 評価指標を用いて、モデルの解答をどのように採点するのかを具体的に定めたもの。評価の公平性と客観性を保証する。 | 採点基準 |
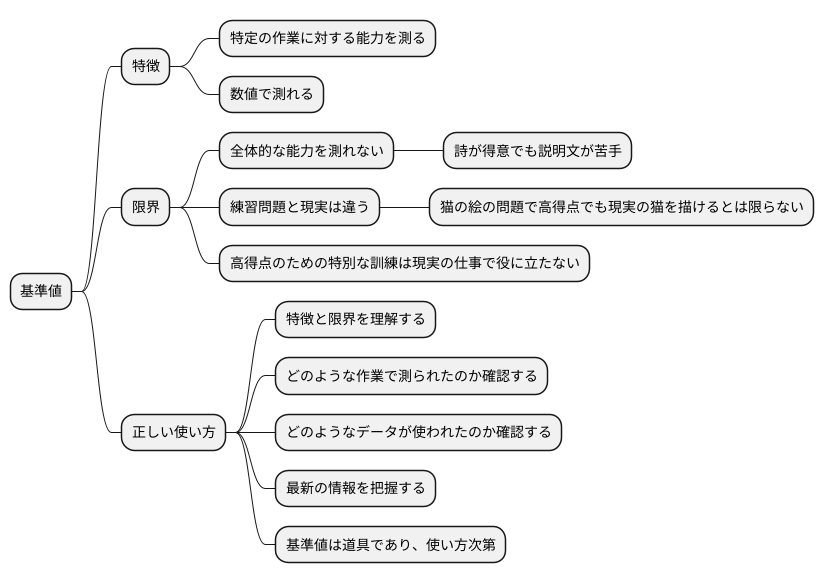
ベンチマークの活用と限界

様々な作業の出来方を測るための便利な道具として、指標となる基準値があります。この基準値を使うことで、例えば文章を作る人工知能の良し悪しを数値で測ることができます。しかし、この基準値は万能ではなく、使い方を間違えると、誤った判断をしてしまう可能性があります。基準値は特定の作業に対する能力しか測れないからです。例えば、詩を作るのが得意な人工知能が、商品の説明文を書くのが苦手ということもあり得ます。基準値は、人工知能の全体的な能力を測るものではないことを理解する必要があります。
また、基準値を測るために使う練習問題は、現実の問題とは違う場合があります。例えば、人工知能に猫の絵を描かせる練習問題で高得点を取ったとしても、現実の様々な猫の絵を上手に描けるとは限りません。練習問題で使われた猫の絵は、限られた種類で、現実の猫の多様性を反映していないかもしれません。さらに、基準値で高得点を取らせるために、人工知能に特別な訓練をさせることもあります。このような人工知能は、基準値では良い成績を残せますが、現実の仕事ではうまくいかない可能性があります。
基準値を正しく使うためには、その特徴と限界を理解することが大切です。基準値の数値だけを見るのではなく、どのような作業で測られたのか、どのようなデータが使われたのかを注意深く確認する必要があります。また、基準値は常に新しく開発されているので、最新の情報を常に把握しておくことも重要です。新しい基準値は、より現実的な問題を反映している可能性があり、人工知能の能力をより正確に評価できるかもしれません。基準値はあくまでも道具の一つであり、使い方次第で役に立つものです。その限界を理解し、他の情報と合わせて総合的に判断することで、人工知能の真価を見極めることができます。
今後の展望

近頃の大規模言語モデルの進歩は目を見張るものがあり、同時にその性能を測るための評価基準も発展を続けています。これまでのような単純な指標だけでなく、様々な課題を評価できる、より複雑な評価基準が開発されています。例えば、文章の読解力だけでなく、論理的思考力や推論能力などを測る評価基準が登場しています。また、人間の感覚を取り入れた評価基準も研究されており、文章の自然さや創造性といった、数値化が難しい要素も評価できるようになることが期待されます。
これらの新しい評価基準によって、大規模言語モデルの性能評価はより精密になり、開発の速度向上に繋がると考えられます。これまで以上に詳細な分析が可能になることで、モデルの弱点や改善点を的確に捉え、より効率的な開発が可能になるでしょう。また、これらの評価基準が進化することで、大規模言語モデルは単なる言葉の処理だけでなく、より人間に近い知能を実現できる可能性を秘めています。
さらに、評価基準の共通化も重要な課題となっています。異なる評価基準の間で結果を比較しやすくすることで、研究開発の効率が向上し、技術の進歩が加速すると期待されています。共通の尺度を用いることで、異なるモデルの性能を公平に比較することが可能になり、開発者はどのモデルが特定の課題に適しているかを容易に判断できるようになります。これは、大規模言語モデルの開発を促進するだけでなく、様々な分野への応用を加速させる力となります。
このように、評価基準は、大規模言語モデルの発展に欠かせない要素です。今後、評価基準がさらに進化することで、より人間に近い知能の実現に近づくことができると期待されます。そして、様々な分野で活用されることで、私たちの生活をより豊かに、便利にしてくれることでしょう。
| 大規模言語モデル評価基準の進化 | 内容 | 期待される効果 |
|---|---|---|
| 複雑な評価基準 | 読解力だけでなく、論理的思考力、推論能力、自然さ、創造性なども評価 | 精密な性能評価、開発速度向上、詳細な分析による効率的な開発 |
| 人間の感覚を取り入れた評価基準 | 数値化が難しい要素も評価可能に | より人間に近い知能の実現 |
| 評価基準の共通化 | 異なる評価基準間での結果比較を容易に | 研究開発の効率向上、技術進歩の加速、異なるモデルの公平な比較、特定の課題に適したモデルの選定を容易に |