活性化関数ReLUとは?仕組み・利点・注意点をわかりやすく解説

AIの初心者
「ReLU関数」って、どんなものですか?機械学習の本でよく見るのですが、数式を見ると少し難しく感じます。

AI専門家
ReLU関数は、ニューラルネットワークでよく使われる活性化関数だよ。入力が0より小さければ0を返し、0以上なら入力値をそのまま返す、とてもシンプルな関数なんだ。
AIの初心者
ただ0にするか、そのまま通すだけなんですね。なぜそれがAIの学習で役立つのでしょうか?
AI専門家
計算が軽く、深いニューラルネットワークでも学習信号が弱まりにくいからだよ。ただし、弱点もあるので、仕組みと注意点をセットで理解しておくことが大切なんだ。
ReLU関数とは
ReLU関数は、深層学習でよく使われる活性化関数の一つです。正式にはRectified Linear Unit、日本語では修正線形ユニットと呼ばれます。
定義はとても単純で、入力値が負なら0、0以上なら入力値をそのまま出力します。
\(
\mathrm{ReLU}(x) = \max(0, x)
\)
たとえば、入力が -3 のときは0、2のときは2、5のときは5を返します。グラフにすると、0より左側は平らで、0より右側は右上がりの直線になるため、ランプ関数とも呼ばれます。
この記事では、ReLUの定義、活性化関数としての役割、勾配消失問題との関係、微分の扱い、利点と弱点、発展形までを初心者向けに整理します。
活性化関数とは

ReLUを理解するには、まず活性化関数の役割を押さえる必要があります。活性化関数とは、ニューラルネットワークの各層で計算された値を変換し、次の層へ渡すための関数です。
ニューラルネットワークでは、入力値に重みを掛け、バイアスを足して次の層へ信号を送ります。しかし、この処理だけを何層も重ねても、全体としては線形変換のままです。線形変換だけでは、画像、音声、文章のような複雑なパターンを十分に表現できません。
そこで活性化関数を入れることで、モデルに非線形な関係を表現する力を与えます。たとえば、ある特徴が一定以上強く出たときだけ次の層へ信号を強く渡す、といった振る舞いが可能になります。
つまり、活性化関数は「ニューラルネットワークを深くする意味」を作る重要な部品です。ReLUは、その中でも計算が軽く扱いやすいため、深層学習で広く使われています。
| 項目 | 説明 | 重要性 |
|---|---|---|
| 活性化関数 | 各層の計算結果を変換して次の層へ渡す関数 | ニューラルネットワークに表現力を与える |
| 非線形変換 | 入力に比例しない形で出力を変える処理 | 複雑なデータの関係を学習しやすくする |
| ReLU | 負の入力を0、0以上の入力をそのまま返す関数 | 計算が軽く、深いモデルで使いやすい |
ReLU関数の定義とランプ関数としての形

ReLU関数は、次のように入力値の符号で出力が変わります。
| 入力値 | ReLUの出力 | 意味 |
|---|---|---|
| -3 | 0 | 負の値なので0にする |
| 0 | 0 | 0はそのまま0 |
| 2 | 2 | 正の値なのでそのまま返す |
| 5 | 5 | 正の値なのでそのまま返す |
グラフで見ると、入力が0未満の範囲では出力がずっと0になります。一方、入力が0を超えると、出力は入力と同じ値になり、傾き1の直線として伸びていきます。この形が坂道のように見えるため、ReLUはランプ関数の一種として説明されることがあります。
この単純さは、ReLUの大きな強みです。シグモイド関数やtanh関数のように指数関数を使う必要がないため、計算量が少なく、大規模なニューラルネットワークでも高速に処理しやすくなります。
また、負の入力を0にすることで、すべてのニューロンが常に反応するのではなく、一部のニューロンだけが有効に働く状態を作れます。この性質はスパース性と呼ばれ、モデルの計算効率や過学習の抑制に関係します。
ReLUが勾配消失問題を抑えやすい理由
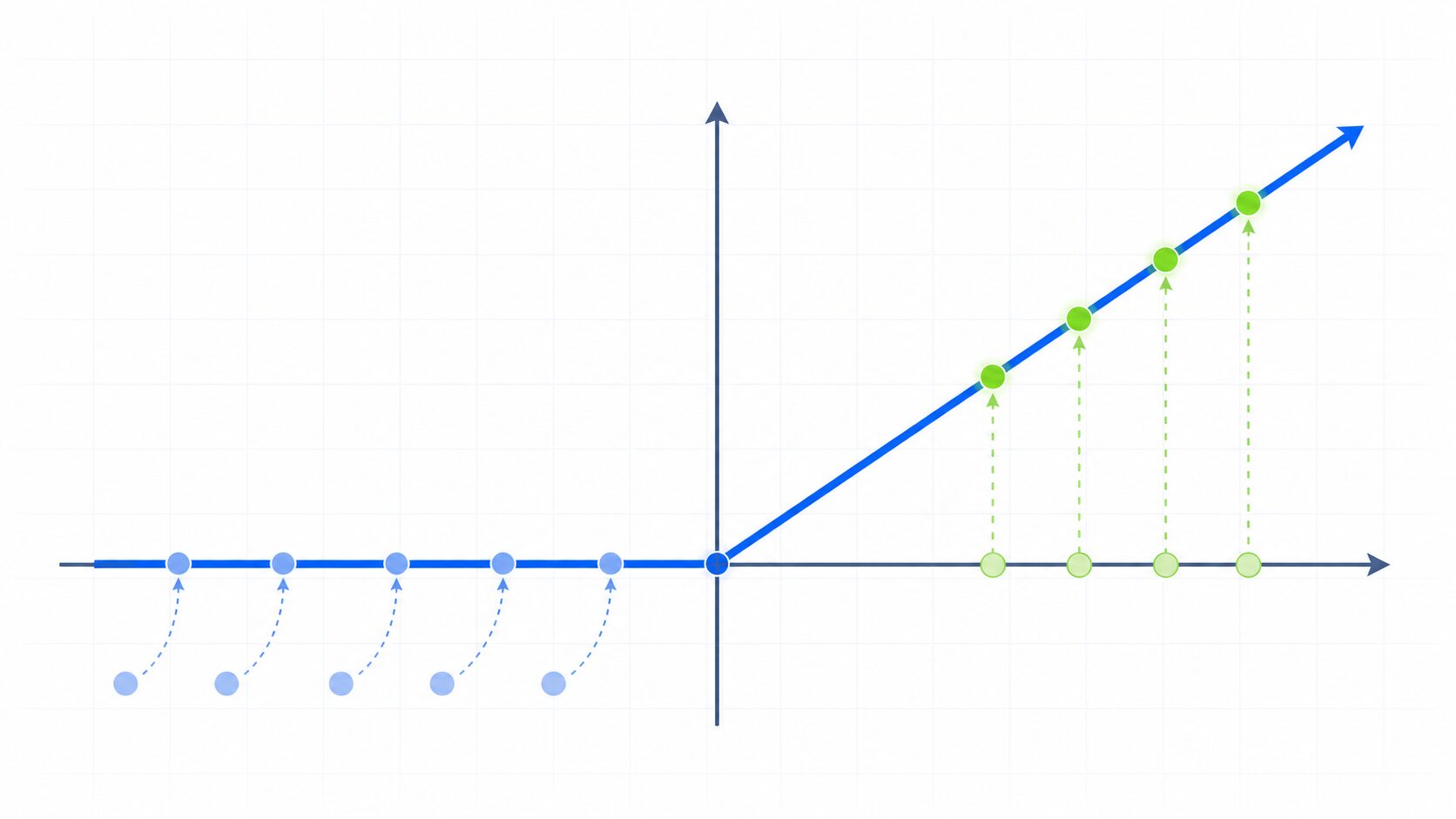
深いニューラルネットワークでは、学習時に勾配消失問題が起きることがあります。勾配消失問題とは、誤差を出力側から入力側へ伝える過程で勾配がどんどん小さくなり、前の層ほど学習が進みにくくなる現象です。
従来よく使われていたシグモイド関数は、入力が大きすぎる場合や小さすぎる場合に出力の変化が非常に緩やかになります。この範囲では勾配が小さくなるため、層を何段も通るうちに学習信号が弱まりやすくなります。
一方、ReLUは入力が正の範囲では勾配が1です。つまり、正の入力に対しては勾配が極端に小さくなりにくく、深い層にも学習信号を伝えやすいという特徴があります。
もちろん、ReLUだけですべての学習問題が解決するわけではありません。それでも、計算の軽さと勾配の伝わりやすさを両立できるため、画像認識や自然言語処理など、多くの深層学習モデルの隠れ層で標準的に使われてきました。
| 比較項目 | シグモイド関数 | ReLU関数 |
|---|---|---|
| 出力範囲 | 0から1の範囲 | 0以上で上限なし |
| 計算 | 指数関数を使うため比較的重い | 最大値を取るだけなので軽い |
| 勾配 | 入力が大きい範囲で小さくなりやすい | 正の範囲では1 |
| 主な用途 | 確率のような出力を表したい場面など | 隠れ層の活性化関数として広く使われる |
ReLU関数の微分と0での扱い
ニューラルネットワークの学習では、誤差逆伝播法によって各パラメータを更新します。このとき必要になるのが、活性化関数の微分、つまり勾配です。
ReLUの微分は、入力が正なら1、入力が負なら0です。
\(
f'(x) =
\begin{cases}
1 & (x > 0) \\
0 & (x < 0) \\
\text{未定義} & (x = 0)
\end{cases}
\)
注意点は、入力がちょうど0のときです。ReLUのグラフは0の点で折れ曲がっているため、数学的には微分が定義できません。左側から見ると傾き0、右側から見ると傾き1になり、両者が一致しないからです。
ただし、実務上はこの点が大きな問題になることは多くありません。多くの実装では、0での勾配を便宜的に0、0.5、1などとして扱います。連続値を扱う学習では、入力が厳密に0になるケースばかりではないため、経験的には問題なく機能することが知られています。
| 入力の範囲 | 出力 | 勾配 |
|---|---|---|
| x < 0 | 0 | 0 |
| x = 0 | 0 | 数学的には未定義 |
| x > 0 | x | 1 |
ReLU関数の利点
ReLUが深層学習でよく使われる理由は、主に計算が軽いこと、勾配消失を抑えやすいこと、スパース性を作りやすいことの3つです。
第一に、ReLUは計算が非常に単純です。入力と0を比較し、大きい方を返すだけなので、指数関数や複雑な変換を必要としません。モデルが大きくなるほど、この計算の軽さは学習時間や推論速度に影響します。
第二に、正の入力では勾配が1であるため、深い層でも学習信号が小さくなりにくいという利点があります。これは、シグモイド関数などで問題になりやすい勾配消失への実用的な対策になります。
第三に、負の入力を0にするため、ニューロンの出力に0が増えます。これはスパースな表現を作り、不要な反応を抑える方向に働きます。結果として、計算の効率化や過学習の抑制につながる場合があります。
| 利点 | 内容 | 実務上の意味 |
|---|---|---|
| 計算が軽い | 0と入力値の大きい方を返すだけ | 大規模モデルでも処理しやすい |
| 勾配消失を抑えやすい | 正の範囲では勾配が1 | 深いネットワークを学習しやすい |
| スパース性を促す | 負の入力は0になる | 不要な反応を抑え、効率的な表現になりやすい |
ReLUの注意点と発展形
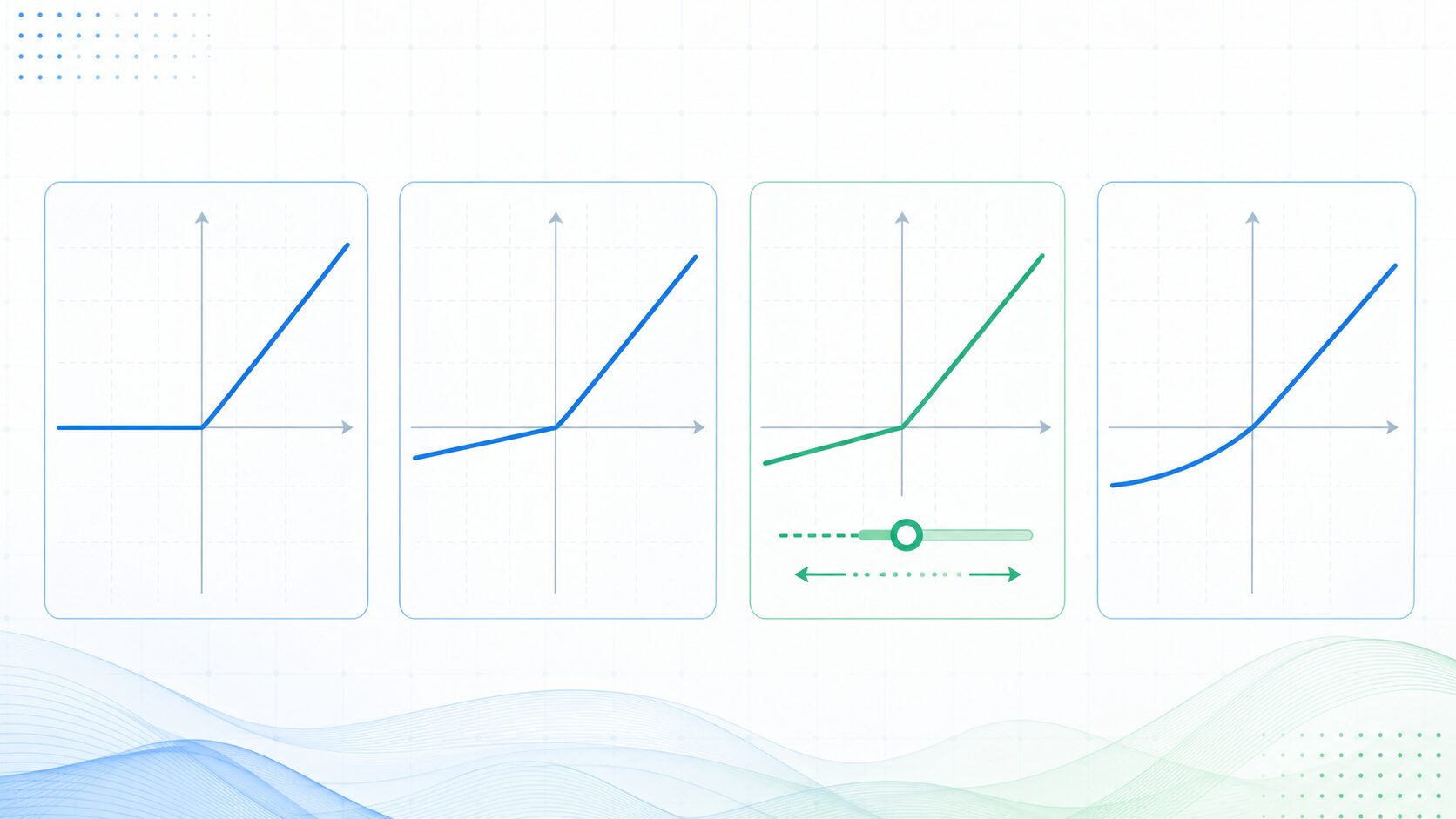
ReLUには多くの利点がありますが、弱点もあります。代表的なのが死んだReLU問題です。
死んだReLU問題とは、あるニューロンへの入力が学習中に負の値ばかりになり、出力が常に0になってしまう現象です。負の範囲では勾配も0になるため、そのニューロンの重みが更新されにくくなり、実質的に学習に参加しなくなることがあります。
この問題を緩和するために、ReLUを改良した活性化関数が提案されています。たとえば、Leaky ReLUは負の入力でもごく小さな傾きを残します。PReLUはその傾きを学習可能なパラメータにします。ELUは負の範囲を滑らかな曲線で表現し、学習を安定させることを狙います。
ただし、改良型を使えば常に良くなるわけではありません。ReLUは単純で高速という強みがあり、まず試す標準的な選択肢として今でも有効です。学習が不安定な場合や死んだReLUが疑われる場合に、Leaky ReLUなどを比較検討するとよいでしょう。
| 活性化関数 | 特徴 | 向いている場面 | 注意点 |
|---|---|---|---|
| ReLU | 負の入力は0、正の入力はそのまま返す | まず試す標準的な隠れ層の活性化関数 | 死んだReLU問題が起きることがある |
| Leaky ReLU | 負の入力にも小さな傾きを残す | ReLUで学習が止まりやすい場合 | 負側の傾きは固定値として決める必要がある |
| PReLU | 負側の傾きを学習で調整する | データに合わせて柔軟に表現したい場合 | 学習するパラメータが増える |
| ELU | 負の範囲を滑らかな曲線で表す | 学習の安定性を重視する場合 | ReLUより計算が重くなることがある |
ReLUはどこで使うのか
ReLUは、主にニューラルネットワークの隠れ層で使われます。画像分類モデル、物体検出モデル、音声認識、自然言語処理など、さまざまな深層学習モデルで利用されてきました。
一方で、出力層では目的に応じて別の関数を使うことが多くあります。二値分類で確率を出したいならシグモイド関数、多クラス分類ならソフトマックス関数を使う、といった選び方です。
したがって、ReLUは「どこでも使う万能関数」ではなく、「隠れ層で特徴を変換するために使いやすい活性化関数」と理解すると実務に近い理解になります。
まとめ
ReLU関数は、入力が負なら0、0以上ならそのまま返す活性化関数です。式は `ReLU(x) = max(0, x)` と非常に単純ですが、計算が軽く、正の範囲では勾配が1になるため、深いニューラルネットワークの学習で扱いやすいという大きな利点があります。
一方で、負の入力が続くとニューロンが学習しにくくなる死んだReLU問題や、0で微分できないという理論上の注意点もあります。必要に応じてLeaky ReLU、PReLU、ELUなどの発展形と比較しながら使い分けることが大切です。
初心者はまず、ReLUを「負の値を0にし、正の値をそのまま通すことで、軽く効率よく非線形性を加える関数」と覚えると理解しやすいでしょう。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年4月29日 | ReLU関数の定義、活性化関数としての役割、勾配消失との関係、微分の扱い、注意点と発展形を初心者向けに再構成 |