Rainbowとは?DQNを拡張した深層強化学習手法

AIの初心者
「Rainbow」って、DQNにいろいろな改良を足した強化学習の手法だと聞きました。どんな技術を組み合わせているんですか?

AI専門家
Rainbowは、DQNを土台に、Double DQN、Dueling Network、マルチステップ学習、Noisy Network、Categorical DQN、優先度付き経験再生などを統合した手法だよ。
AIの初心者
たくさんありますね。それぞれは別々の役割を持っているんですか?
AI専門家
そうだね。価値の見積もりを安定させる工夫、探索を促す工夫、重要な経験を優先して学ぶ工夫などがあり、それらを合わせることでDQNより強い学習がしやすくなるんだ。
Rainbowとは。
Rainbowは、深層強化学習の代表的な手法であるDQNを土台に、複数の改良技術を組み合わせたアルゴリズムです。2017年に提案され、Atari 2600のゲームベンチマークで高い性能を示したことで知られています。名前の通り、複数の色が重なって虹になるように、DQN系の有効な工夫を一つの学習手法として統合している点が特徴です。
Rainbowとは?DQNを拡張した深層強化学習手法
Rainbowは、強化学習エージェントが試行錯誤からより効率よく行動を学ぶために、DQNの弱点を複数の方向から補った手法です。DQNは、ニューラルネットワークを使って「ある状態で、ある行動を取るとどれくらい価値があるか」を推定します。ゲーム画面やセンサー情報のような複雑な入力から行動価値を学べるため、深層強化学習の重要な出発点になりました。
ただし、基本的なDQNには課題もあります。価値を高く見積もりすぎることがある、探索と活用の調整が難しい、すべての経験を同じように扱うと学習が非効率になる、将来の報酬を十分に活かしにくい、といった点です。Rainbowは、こうした課題に対して有効だった改良をまとめて取り入れ、単独のDQNより安定して高い性能を狙えるようにしています。
初心者が理解するときは、Rainbowを「DQNとはまったく別物の技術」と考えるよりも、DQNを中心にした改良版の集合体として捉えると整理しやすくなります。各要素がどの問題を解決するためのものかを見ると、Rainbowの全体像がつかみやすくなります。
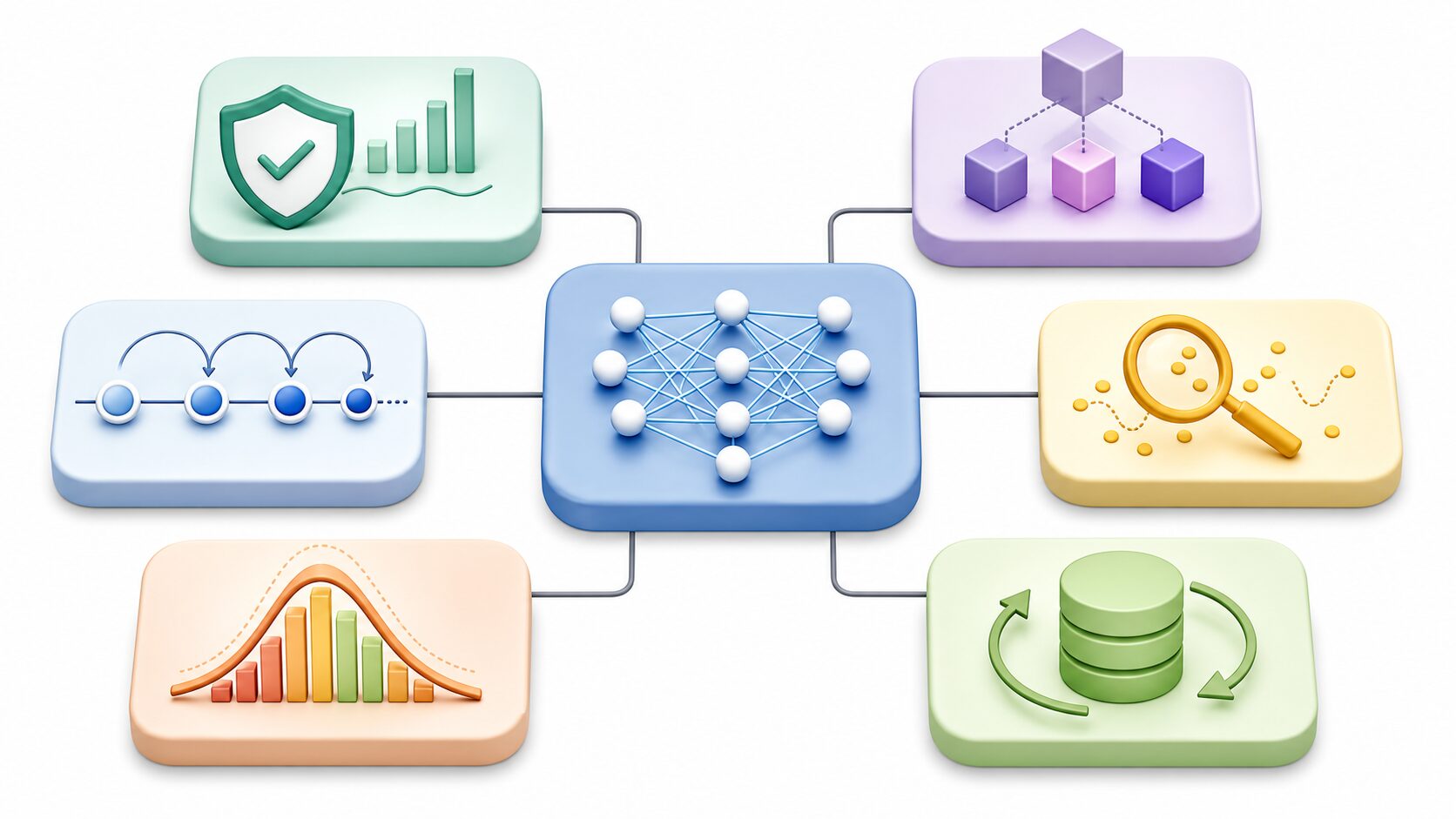
Rainbowを構成する7つの要素

Rainbowの説明では、DQNを土台に複数の改良を統合した手法として紹介されます。元記事では「7つの要素」として、DQN、Double DQN、Dueling Network、マルチステップ学習、Noisy Network、Categorical DQN、優先度付き経験再生が挙げられています。役割を分けて見ると、何が性能向上に効いているのかが分かりやすくなります。
| 要素 | 主な役割 | 初心者向けの見方 |
|---|---|---|
| DQN | ニューラルネットワークで行動価値を推定する | Rainbowの土台 |
| Double DQN | 価値を過大評価しすぎる問題を抑える | 判断を安定させる工夫 |
| Dueling Network | 状態そのものの価値と行動ごとの差を分けて学ぶ | 「状況の良さ」と「行動の良さ」を分ける |
| マルチステップ学習 | 数ステップ先までの報酬を学習に反映する | 目先だけでなく少し先を見る |
| Noisy Network | ネットワークにノイズを入れて探索を促す | 新しい行動を試しやすくする |
| Categorical DQN | 報酬の期待値だけでなく分布を扱う | 結果のばらつきも考慮する |
| 優先度付き経験再生 | 学習効果の高い経験を優先的に再利用する | 重要な復習問題を先に解く |
これらは同じ方向の改良ではありません。Double DQNやDueling Networkは価値推定の精度や安定性に関わり、Noisy Networkは探索に関わります。優先度付き経験再生は学習データの使い方を変え、Categorical DQNは報酬の捉え方を変えます。Rainbowは、こうした異なる工夫をまとめることで、DQNの弱点を一つずつ補っています。
土台になるDQNの考え方

DQNは「Deep Q-Network」の略で、深層学習を使ってQ値を近似する手法です。Q値とは、ある状態である行動を選んだとき、将来的にどれくらい良い結果が期待できるかを表す値です。例えばゲームなら、現在の画面を状態、ボタン操作を行動、得点やクリアに近づくことを報酬として扱います。
DQNでは、エージェントが環境の中で行動し、得られた報酬と次の状態を経験として蓄積します。その経験を使ってニューラルネットワークを更新し、次に似た状況が来たときにより良い行動を選べるようにします。人間が失敗や成功を通じてゲームのコツを覚えるのに近い考え方です。
一方で、Q値の推定は学習途中で揺れやすく、誤った高評価が積み重なると行動選択も不安定になります。また、経験をランダムに再利用するだけでは、学習に重要な場面が埋もれてしまうこともあります。Rainbowの各改良は、このようなDQNの弱点を補うために組み込まれています。
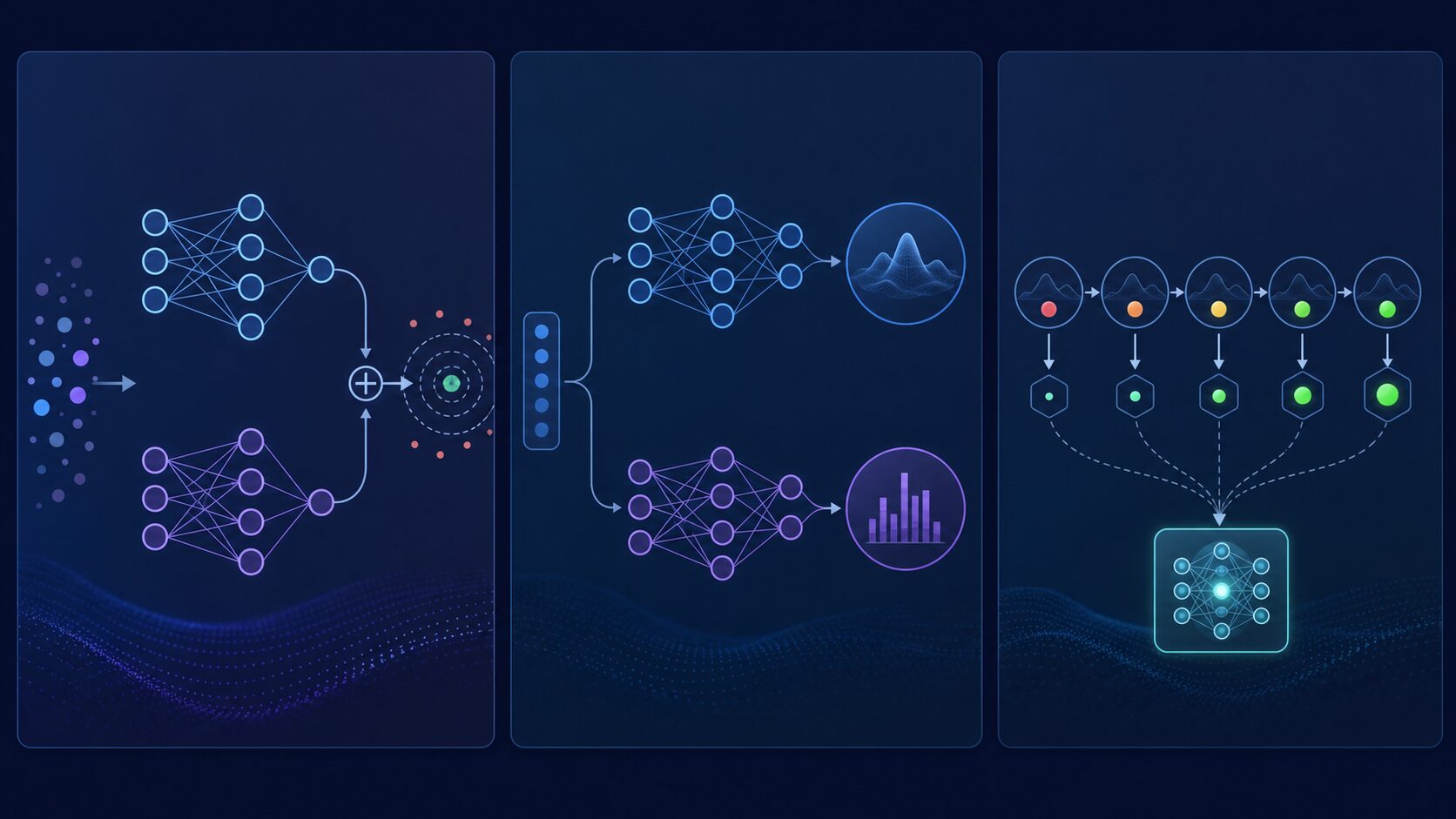
学習を安定させる改良:Double DQN、Dueling、マルチステップ
Double DQNは、DQNが行動価値を過大評価しやすい問題を抑えるための工夫です。基本的なDQNでは、行動を選ぶ処理と、その行動の価値を評価する処理が強く結びつくため、たまたま高く見積もられた行動が選ばれやすくなります。Double DQNではこの役割を分けることで、価値推定の偏りを減らし、学習を安定させます。
Dueling Networkは、状態の価値と行動の優位性を分けて学ぶ構造です。たとえば、ゲームで「今の位置はかなり有利だが、右に動いても左に動いても大差ない」という場面があります。このとき、状態そのものの良さと各行動の差を分けて捉えられると、価値の推定が効率的になります。
マルチステップ学習は、1ステップ先の報酬だけでなく、数ステップ先までの報酬をまとめて学習に使う考え方です。目先の報酬だけを見ると、本当は後で大きな成果につながる行動を見逃す場合があります。数ステップ分の情報を使うことで、短期的な反応と長期的な見通しのバランスを取りやすくなります。
探索を改善するNoisy Network
強化学習では、すでに良いと分かっている行動を選ぶ「活用」と、まだ試していない行動を選ぶ「探索」のバランスが重要です。活用に偏りすぎると、局所的には良いが全体では最適でない行動に固まってしまうことがあります。反対に探索ばかりでは、学習がなかなか収束しません。
Rainbowでは、Noisy Networkによって探索を促します。これは、ニューラルネットワークの一部に学習可能なノイズを入れ、行動選択に適度な揺らぎを持たせる方法です。単にランダムに行動するのではなく、学習の中で探索のしかたも調整される点が特徴です。
初心者向けには、Noisy Networkを「新しい選択肢を試すための仕組み」と理解するとよいでしょう。未知の環境では、最初から最適な行動は分かりません。適度な探索があることで、エージェントは失敗も含めて経験を集め、より良い戦略にたどり着きやすくなります。
経験と報酬分布を活かす仕組み
優先度付き経験再生は、過去の経験をすべて同じ重みで扱うのではなく、学習効果が高そうな経験を優先的に使う仕組みです。試験勉強で、すでに解ける問題よりも間違えやすい問題を重点的に復習するほうが効率的な場合があります。強化学習でも、価値推定の誤差が大きい経験は、学習を進めるうえで重要な手がかりになります。
Categorical DQNは、報酬を一つの期待値だけで表すのではなく、分布として扱う考え方です。同じ平均点に見える行動でも、安定して中程度の報酬を得る行動と、成功すれば大きいが失敗も多い行動では性質が異なります。分布を扱うことで、報酬のばらつきや不確実性をより豊かに表現できます。
この2つは、Rainbowの学習効率と表現力を支える要素です。重要な経験を効率よく再利用し、報酬の見方を細かくすることで、単純なDQNよりも環境の特徴を捉えやすくなります。
Rainbowの性能と使いどころ
Rainbowは、Atari 2600のゲームを使った評価で高い成績を示し、DQN系の改良を統合する有効性を示しました。ゲーム環境は、画面から状態を読み取り、連続した行動の結果として報酬を得るため、深層強化学習の性能を比べる題材としてよく使われます。
考え方としては、ゲームだけでなく、ロボット制御、自動運転、シミュレーション環境での意思決定、資源配分などにもつながります。ただし、現実の応用では安全性、計算量、報酬設計、シミュレーションと現実の差などを慎重に扱う必要があります。Rainbowが高性能だからといって、そのまますべての現場問題に適用できるわけではありません。
実務や研究で見ると、Rainbowは「複数の既存改良を組み合わせると、どの程度性能が上がるのか」を示した代表例でもあります。現在の強化学習手法を理解するうえでも、DQNからRainbowへ進む流れを押さえることは役に立ちます。
初心者が理解するときの注意点
Rainbowを学ぶときは、最初からすべての要素を細かく実装レベルで理解しようとすると難しくなります。まずはDQNの基本である「状態、行動、報酬、Q値、経験再生」を押さえ、そのうえで各改良がどの弱点を補うのかを確認すると理解しやすくなります。
また、Rainbowは複数の工夫を入れるため、実装は基本的なDQNより複雑です。パラメータ調整や計算コストも増えます。学習目的なら、DQN、Double DQN、Dueling Network、優先度付き経験再生のように、要素を一つずつ確認してからRainbow全体に進むとよいでしょう。
用語にも注意が必要です。Noisy Networkは単なるランダム行動ではなく、ネットワークの重みにノイズを入れる仕組みです。Categorical DQNは「分類だけをするDQN」ではなく、報酬分布をカテゴリとして近似する分布型強化学習の考え方です。こうした違いを意識すると、Rainbowの説明が表面的な暗記で終わりにくくなります。
まとめ
Rainbowは、DQNを土台に複数の改良を統合した深層強化学習手法です。Double DQNで価値推定の過大評価を抑え、Dueling Networkで状態価値と行動の優位性を分け、マルチステップ学習で将来報酬を活かします。さらに、Noisy Networkで探索を促し、優先度付き経験再生で重要な経験を効率よく使い、Categorical DQNで報酬分布を扱います。
Rainbowの本質は、DQNの弱点を一つの工夫で解決するのではなく、複数の有効な改良を組み合わせて総合的に性能を高める点にあります。初心者はまずDQNの基本を理解し、各要素がどの問題に対応しているのかを順番に見ると、Rainbowの全体像を無理なくつかめます。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月19日 | DQNとの差分、7要素の役割、応用時の注意点を追記 |