サンプリングバイアスとは?意味・具体例・AIでの注意点を解説

AIの初心者
「サンプリングバイアス」って、どんな偏りのことですか?

AI専門家
簡単に言うと、調べたい全体を代表しないデータを集めてしまうことだよ。若者が多い場所で街頭インタビューをして、それを国民全体の意見として扱うような場合だね。
AIの初心者
全体を表していないデータで判断すると、結果もずれてしまうということですね。AI開発ではどう関係しますか?
AI専門家
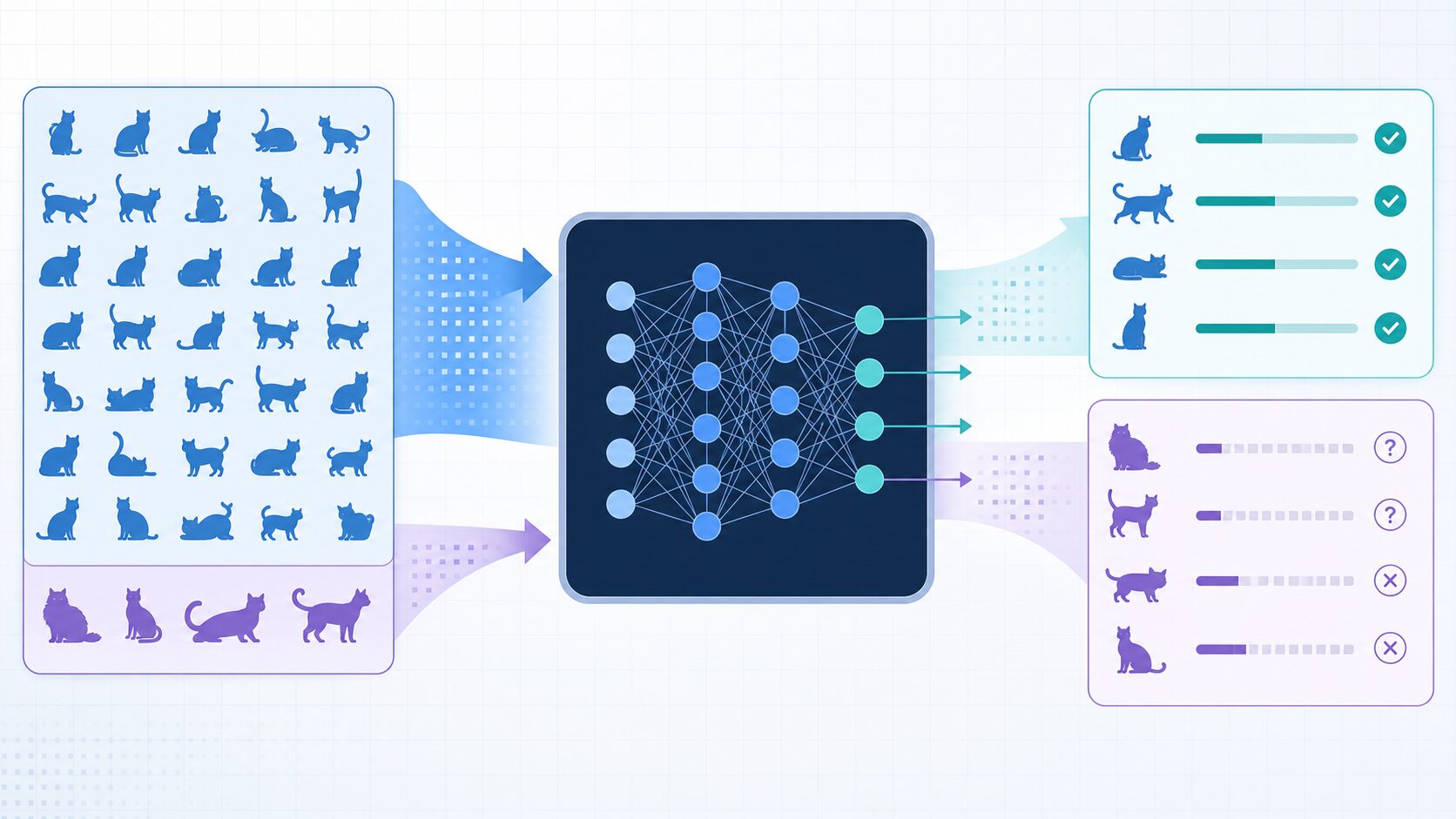
例えば猫を見分けるAIに白い猫の画像ばかり学習させると、黒い猫や模様のある猫をうまく認識できない可能性がある。データの偏りが、AIの性能や公平性に影響するんだ。
サンプリング・バイアスとは。
サンプリングバイアスとは、調査や機械学習で使う標本の選び方に偏りがあり、本来知りたい母集団の特徴を正しく反映できなくなることです。サンプルバイアスとも呼ばれ、アンケート、統計分析、AIの学習データなど、データを一部だけ集めて判断する場面で問題になります。
サンプリングバイアスとは?母集団を代表できない偏り
サンプリングバイアスは、調べたい全体である母集団から一部の標本を選ぶときに、特定の属性や条件を持つデータだけが入りやすくなる偏りです。標本調査では全員を調べるのが難しいため一部を選びますが、その一部が全体を代表していなければ、結果は実態からずれてしまいます。
重要なのは、サンプリングバイアスが単なる誤差ではなく、データを集める入口で生じる構造的な偏りだという点です。たまたま数値が少しずれるのではなく、最初から特定の人、地域、年齢層、行動パターンが入りやすい設計になっているため、分析後にきれいなグラフを作っても結論そのものが偏ることがあります。
例えば、ある商品の満足度を調べるために駅前でアンケートを取るとします。その駅をよく使う人、調査時間に外出している人、声をかけられても答えやすい人の意見は集まりやすくなります。一方で、在宅勤務の人、夜勤の人、遠方に住む利用者は抜けやすくなります。結果として「利用者全体の満足度」と言いながら、実際には駅前で回答しやすい人の傾向を見ているだけかもしれません。
| 観点 | 偏りがない場合 | サンプリングバイアスがある場合 |
|---|---|---|
| 標本の選び方 | 母集団の構成をできるだけ反映する | 特定の属性や行動を持つ人が入りやすい |
| 結果の解釈 | 全体の傾向として扱いやすい | 全体の傾向と誤解すると判断を誤る |
| 対策 | 抽出方法や対象範囲を事前に設計する | 抜けている層を後から確認する必要がある |
サンプリングバイアスが起こる具体例

サンプリングバイアスは、特別な研究だけでなく日常的な調査でも起こります。代表例は街頭アンケートです。若者が多い繁華街で政治や健康食品について意見を聞くと、そこに来ない高齢者や地方在住者の意見は反映されにくくなります。調査人数が多くても、調査場所が偏っていれば、母集団全体を代表するとは限りません。
インターネットアンケートでも同じ問題があります。オンラインで回答できる人に対象が限られるため、インターネットを使わない人、調査サイトに登録していない人、スマートフォン操作が苦手な人の意見は抜けやすくなります。また、商品レビューのように自由参加型のデータでは、強い不満や強い満足を持つ人ほど投稿しやすく、平均的な利用者の声が埋もれることがあります。
企業分析でも注意が必要です。成功した会社だけを集めて共通点を探すと、そこに見える特徴が成功要因のように見えます。しかし、同じ特徴を持っていたものの失敗した会社が分析対象から抜けていれば、結論は大きく歪みます。これは生存バイアスとも関係する例で、見えているデータだけで全体を判断する危険性を示しています。
| 場面 | 偏りの起こり方 | 起こりうる誤解 |
|---|---|---|
| 街頭アンケート | その場所と時間にいる人だけが対象になる | 特定地域や年齢層の意見を全体の意見と見なす |
| ネット調査 | オンラインで回答できる人に限られる | ネットを使わない層の意見を見落とす |
| 商品レビュー | 強い感情を持つ人が投稿しやすい | 実際より満足や不満が極端に見える |
| 成功事例分析 | 失敗した事例が残りにくい | 成功者に見える特徴を過大評価する |
AI・機械学習でサンプリングバイアスが問題になる理由

AIや機械学習では、モデルが学習データに含まれる傾向をもとに予測します。そのため、学習データが偏っていると、モデルは偏った世界を「普通」として覚えてしまいます。これは画像認識、音声認識、需要予測、審査モデルなど、幅広い用途で問題になります。
例えば、猫を認識するAIに白い猫の画像ばかりを学習させた場合、白い猫には高い精度を出せても、黒い猫、長毛種、暗い室内で撮られた猫には弱くなる可能性があります。医療画像でも、特定の年齢層や施設で撮影されたデータだけで学習すると、別の年齢層や別の機器で撮られた画像に対して性能が落ちることがあります。
AI開発で特に注意したいのは、サンプリングバイアスが精度だけでなく公平性にも関わる点です。ある属性のデータが少ないと、その属性に対する予測の誤りが増えやすくなります。全体の平均精度が高く見えても、特定のグループでは大きく外れている場合があります。したがって、モデル評価では全体の指標だけでなく、年齢、地域、利用状況、撮影条件などの切り口で結果を確認することが大切です。
サンプリングバイアスは「データ量を増やせば自然に消える」とは限りません。偏った収集方法のまま大量に集めれば、偏りも大量に集まります。AIで使うデータでは、どのようなデータが集まりやすく、どのようなデータが抜けているかを設計段階から確認する必要があります。
関連するバイアスとの違い
サンプリングバイアスは、広い意味で「データの偏り」に含まれますが、関連するバイアスと区別しておくと理解しやすくなります。特に混同しやすいのが、自己選択バイアス、生存バイアス、回答バイアスです。
自己選択バイアスは、調査対象者が自分で参加するかどうかを決められるときに起こりやすい偏りです。ネットアンケートや口コミ投稿では、関心が高い人、強い意見を持つ人、時間に余裕がある人が回答しやすくなります。これはサンプリングバイアスの一種として扱える場合があります。
生存バイアスは、残っているデータだけを見て、消えたデータや失敗した事例を見落とす偏りです。成功企業だけを分析する、長く利用されているサービスだけを調べる、といった場面で起こります。回答バイアスは、回答者が本音ではなく社会的に望ましい答えを選んだり、質問の聞き方に影響されたりする偏りです。
| 種類 | 主な原因 | 例 |
|---|---|---|
| サンプリングバイアス | 標本の選び方が母集団を代表していない | 若者が多い場所で全世代向け調査を行う |
| 自己選択バイアス | 参加する人が自分で回答を選ぶ | 強い不満を持つ人ほどレビューを書く |
| 生存バイアス | 残った事例だけを分析する | 成功企業だけを見て経営法則を語る |
| 回答バイアス | 回答者の心理や質問文が答えに影響する | 本音より無難な回答を選ぶ |
サンプリングバイアスを減らす方法

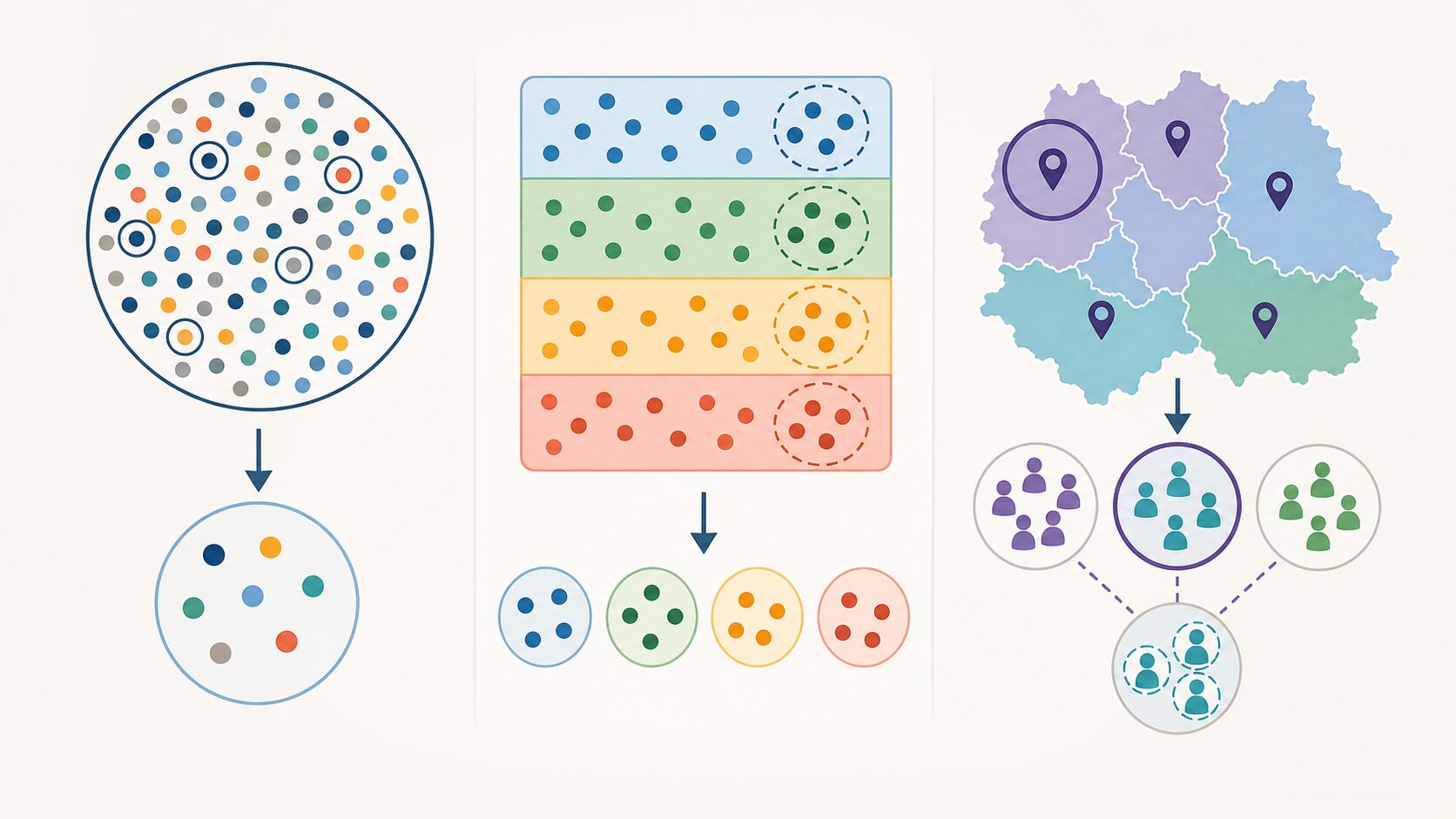
サンプリングバイアスを完全になくすのは難しいですが、調査設計を工夫することで小さくできます。基本となるのは、母集団を明確にし、その母集団を代表するように標本を選ぶことです。「誰について結論を出したいのか」を先に決めないまま集めたデータは、後で解釈が難しくなります。
代表的な方法の一つが無作為抽出です。母集団の各要素が同じ確率で選ばれるようにすることで、特定の人だけが入りやすい状態を避けます。くじ引きのような考え方ですが、実務では対象者リスト、乱数、抽出条件を整える必要があります。
層化抽出は、母集団を年齢層、性別、地域、利用頻度などの層に分け、それぞれの層から標本を選ぶ方法です。母集団の中に重要なグループ差があると分かっている場合に有効です。例えば高齢者向けの商品調査であれば、若年層だけでなく高齢層を十分に含める設計が必要です。
多段抽出は、全国調査のように対象が広い場合に、都道府県、市区町村、個人のように段階を分けて抽出する方法です。調査コストを抑えながら広い範囲を扱える一方で、各段階の選び方に偏りが入らないよう注意が必要です。実務では、これらの方法を単独で使うだけでなく、複数の調査経路を組み合わせて抜けやすい層を補うこともあります。
| 方法 | 向いている場面 | 注意点 |
|---|---|---|
| 無作為抽出 | 対象者リストがあり、ランダムに選べる場合 | リスト自体に抜けがあると偏りが残る |
| 層化抽出 | 年齢、地域、属性ごとの違いを反映したい場合 | 層の分け方を目的に合わせる必要がある |
| 多段抽出 | 全国規模など対象範囲が広い場合 | 段階ごとの抽出条件が偏らないよう確認する |
| 調査方法の併用 | 単一の経路では抜ける層がある場合 | 回答の重複や集計方法を管理する必要がある |
調査やデータ収集で確認したい注意点
サンプリングバイアスを避けるには、データを集める前と集めた後の両方で確認が必要です。まず、母集団を具体的に定義します。「利用者全体」「日本人全体」「購入経験者」などの言葉は広く見えますが、実際には年齢、地域、期間、利用状況などで範囲を決める必要があります。
次に、誰が入りやすく、誰が抜けやすいかを考えます。オンライン調査ならネットを使わない人が抜けます。店舗での調査なら来店しない人が抜けます。アプリの利用ログなら、アプリを開かなくなった人の不満は見えにくくなります。このように、集まったデータだけでなく、集まらなかったデータに目を向けることが重要です。
分析後は、全体平均だけでなく属性別の結果を見ると偏りに気づきやすくなります。AIモデルなら、全体精度、属性別精度、誤判定が多い条件を分けて確認します。市場調査なら、年齢層、地域、購入頻度などの分布が実際の顧客構成と大きくずれていないかを確認します。
それでも偏りを完全に取り除けない場合は、結果の解釈に制限を明記します。「この調査はオンライン回答者を対象としている」「このモデルは特定の撮影条件のデータで評価している」と示すことで、結論を過度に一般化するリスクを下げられます。
まとめ
サンプリングバイアスとは、標本の選び方が偏り、母集団全体の特徴を正しく表せなくなる問題です。街頭アンケート、インターネット調査、レビュー投稿、成功事例分析など、身近なデータ収集でも起こります。
AI・機械学習では、偏った学習データが予測精度や公平性に影響します。データ量が多くても、集め方が偏っていれば、モデルはその偏りを学習してしまいます。したがって、データ収集の段階から「誰を代表するデータなのか」「誰が抜けているのか」を確認することが欠かせません。
対策としては、無作為抽出、層化抽出、多段抽出、調査方法の併用などがあります。どの方法を選ぶ場合でも、母集団を明確にし、偏りが残る可能性を説明できる状態にしておくことが大切です。サンプリングバイアスを意識することで、調査結果やAIの出力をより慎重に、信頼できる形で活用できます。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年6月3日 | AIでの影響と標本設計の確認観点を追記 |