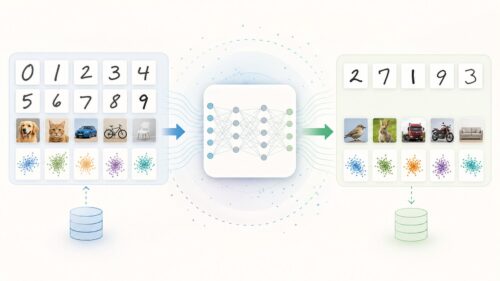
LLM
LLM AIのハルシネーションとは?原因・具体例・対策をわかりやすく解説
近ごろ、人工頭脳の著しい進歩に伴い、様々な場所で活用が進んでいます。ものの、人工頭脳はなんでもできるわけではなく、時として人が驚くような間違いを起こすことがあります。特に注目されているのが「幻覚」と呼ばれる現象です。まるで幻覚を見ているかのように、人工頭脳が事実に基づかない情報を作り出してしまうこの現象は、人工頭脳開発における大きな課題となっています。人工頭脳が社会に深く入り込んでいく中で、幻覚の理解はますます大切になっています。
この幻覚は、人工頭脳が学習したデータに偏りがあったり、学習データが不足していたりする場合に発生しやすくなります。例えば、特定の人物や物事に関する情報ばかりを学習した場合、それ以外の情報について問われると、学習データに基づかない不正確な情報を生成してしまう可能性があります。また、大量のデータを学習したとしても、そのデータの中に誤った情報が含まれていた場合、人工頭脳はそれを正しい情報として認識し、幻覚を引き起こす原因となることがあります。
この幻覚は、様々な問題を引き起こす可能性があります。例えば、ニュース記事を生成する人工頭脳が幻覚を起こした場合、事実に基づかない誤った情報が拡散される危険性があります。また、医療診断を支援する人工頭脳が幻覚を起こした場合、誤診につながり、患者の健康を脅かす可能性も考えられます。このように、人工頭脳の幻覚は、社会に大きな影響を与える可能性があるため、早急な対策が必要です。
幻覚への対策としては、学習データの質と量を向上させることが重要です。偏りのない、多様なデータを用いて人工頭脳を学習させることで、幻覚の発生率を抑制することができます。また、人工頭脳が生成した情報が正しいかどうかを検証する仕組みを導入することも有効です。人が生成された情報をチェックしたり、他の情報源と照らし合わせたりすることで、幻覚による誤りを防ぐことができます。人工頭脳が社会にとってより良いものとなるよう、幻覚への理解を深め、対策を進めていく必要があります。