HNSWとは?Hierarchical Navigable Small Worldの仕組みとベクトル検索で使われる理由

AIの初心者
ベクトル検索を調べていたらHNSWという言葉が出てきました。検索を速くする仕組みらしいのですが、何をしているのか想像しにくいです。

AI専門家
HNSWは、似ているデータ同士をグラフでつなぎ、全部を比べなくても近いデータへたどり着けるようにするインデックスです。生成AIのRAGや画像検索、推薦などでよく使われます。
AIの初心者
普通に全部のベクトルと比べるのではだめなのでしょうか?
AI専門家
データが少なければ全件比較でも十分です。しかし数十万件、数百万件になると、応答時間と計算コストが問題になります。HNSWは、その問題を精度と速度のバランスを取りながら解く代表的な方法です。
HNSWとは。
HNSW(Hierarchical Navigable Small World)とは、ベクトル検索で近いデータを高速に探すための近似最近傍探索インデックスです。データを点、近い点同士の関係を辺として表すグラフを作り、さらにそのグラフを階層化することで、目的の近傍へ短い経路で近づけるようにします。

生成AIを使った検索では、文章、画像、音声、ユーザー行動などを数値の並びであるベクトルに変換し、その距離や類似度を使って「意味が近いもの」を探します。たとえば「退職手続きに必要な書類は?」という質問から、同じ単語を含むページだけでなく、意味の近い社内規程やFAQを探す場合があります。このとき重要になるのが、ベクトル同士の距離を効率よく調べる仕組みです。
HNSWは、その効率化に使われる代表的な手法です。名前に含まれるHierarchicalは「階層的」、Navigableは「たどって進める」、Small Worldは「少ないステップで遠くまで行けるネットワーク」を意味します。つまりHNSWは、階層化された小世界グラフをたどって、近いベクトルを高速に見つける方法だと理解できます。
HNSWが解く問題
ベクトル検索で一番素朴な方法は、検索クエリのベクトルと、保存されているすべてのベクトルを比較することです。この方法は全件比較、またはブルートフォース検索と呼ばれます。全件比較は考え方が単純で、比較対象を漏らさないため精度面ではわかりやすい方法です。しかしデータ数が増えるほど、検索のたびに必要な距離計算が増えます。
たとえば1000件の文書なら、1回の検索で1000個のベクトルと比べれば済みます。ところが100万件の文書がある場合、検索のたびに100万回分の比較が必要になります。さらにベクトルの次元数が高いほど、1回あたりの距離計算も重くなります。RAGのようにユーザーの質問へすぐ答えたい用途では、検索だけで数秒かかると体験が悪くなります。
そこで使われるのが、近似最近傍探索です。近似最近傍探索は、必ず完全な最近傍を探すのではなく、かなり近い候補を高速に見つけることを目指します。英語ではApproximate Nearest Neighbor、略してANNと呼ばれます。HNSWはANNの代表的なアルゴリズムであり、特に高い検索精度を保ちながら高速に探しやすい点で広く使われています。
ここで大切なのは、HNSWが「AIそのもの」ではなく、AIで作ったベクトルを検索しやすくするデータ構造だということです。埋め込みモデルが文章や画像をベクトルに変換し、HNSWのようなインデックスがそのベクトルを高速に検索します。両者は役割が違います。ベクトルの品質が悪ければ、HNSWを使っても検索結果は良くなりません。一方でベクトルの品質が良くても、検索基盤が遅ければ実用的な応答速度を出しにくくなります。
ベクトル検索でHNSWが使われる理由
HNSWがよく使われる理由は、速度、精度、実装しやすさのバランスが良いからです。ベクトル検索では、検索結果の品質だけでなく、応答時間、メモリ使用量、更新のしやすさ、フィルタ条件との相性なども考える必要があります。HNSWは万能ではありませんが、多くの用途で扱いやすい選択肢になります。
具体的には、RAGで質問に関係する文書チャンクを探す場面、ECサイトで似た商品画像を探す場面、ニュースや動画の推薦候補を絞る場面、FAQの意味検索を行う場面などでHNSWが使われます。これらの用途では、1件だけを完全に正確に探すというより、上位数件から数十件の候補を十分な品質で素早く出すことが重要です。
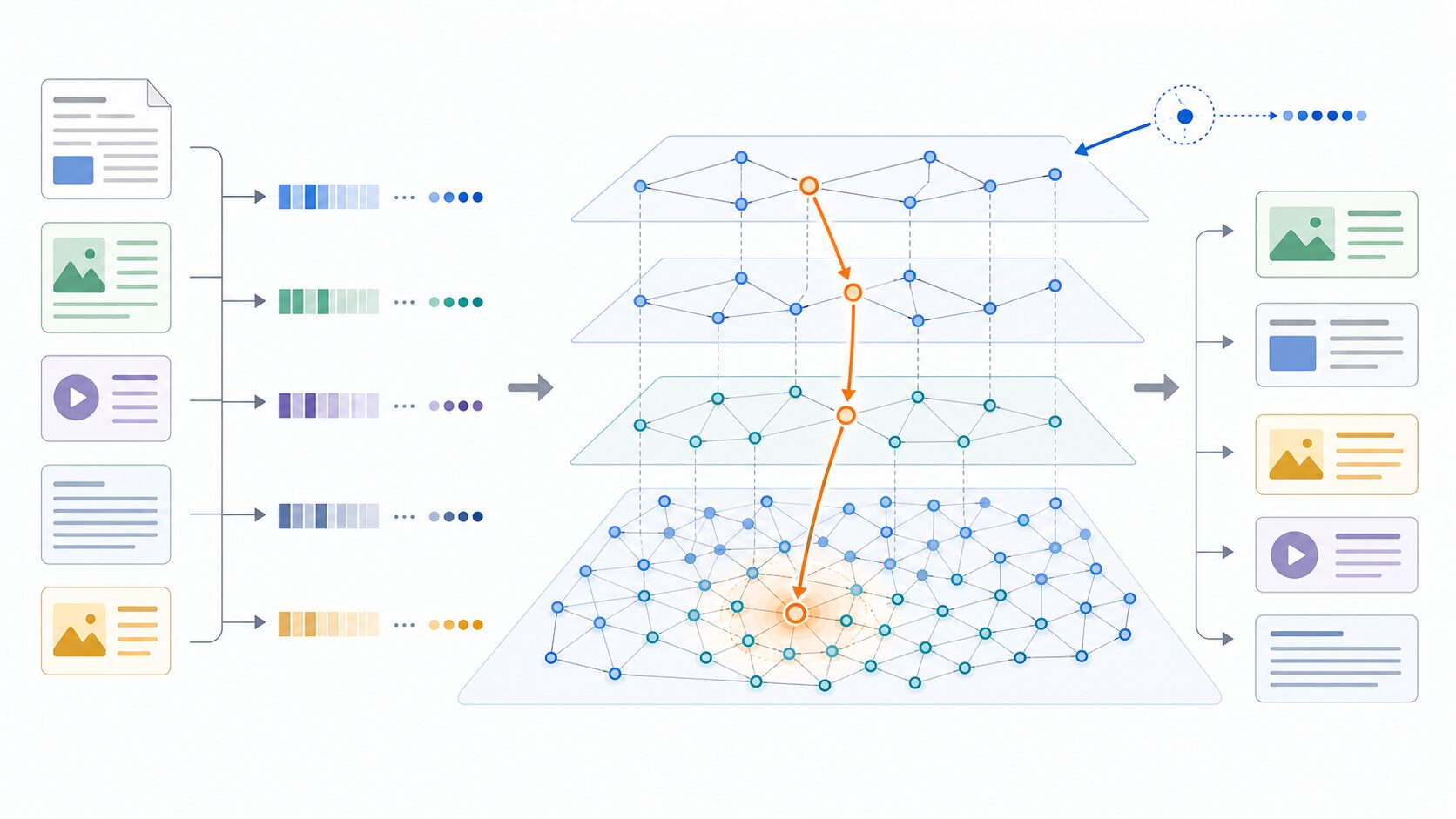
検索基盤では、まず文書や画像を埋め込みモデルでベクトル化します。そのベクトルをデータベースに保存し、検索しやすいようにインデックスを作ります。ユーザーが質問を入力すると、その質問もベクトルに変換され、保存済みベクトルの中から近いものを探します。この「近いものを探す」部分でHNSWが活躍します。
HNSWが好まれるもう一つの理由は、検索時に調整できる余地があることです。たとえば「少し遅くなっても精度を上げたい」「多少精度を落としても応答を速くしたい」といった要件に合わせて、検索時の候補探索幅を変えられます。プロトタイプでは速さを優先し、本番運用では回答品質の評価に合わせて調整する、といった使い方ができます。
ただし、HNSWを使えば何でも速く正確になるわけではありません。データの件数、ベクトルの次元数、距離尺度、メモリ制約、更新頻度、絞り込み条件の多さによって適切な設計は変わります。HNSWは強力な選択肢ですが、検索体験全体を良くするには、チャンク分割、メタデータ設計、再ランキング、評価データの整備も合わせて考える必要があります。
Small Worldグラフの考え方
HNSWを理解するには、まずSmall Worldグラフの発想を押さえるとわかりやすくなります。Small Worldとは、ネットワークの中で一見遠くにある点同士でも、少ないステップで到達できる性質を指します。人間関係で「知り合いをたどると意外と短い経路で別の人につながる」と説明されることがあります。
ベクトル検索では、各データを点として考えます。意味が近い文書、見た目が近い画像、行動傾向が近いユーザーは、ベクトル空間上でも近い場所に配置されやすくなります。HNSWでは、近い点同士を辺で結んだグラフを作ります。検索時には、ある入口の点から始めて、現在地よりクエリに近い隣接点へ移動しながら、目的に近い領域へ進みます。
もしグラフが近い点同士だけで密につながっていると、局所的な移動は得意ですが、遠くの領域へ移動するのに多くのステップが必要になることがあります。逆に遠くの点への接続が適度にあると、広い空間を素早く移動できます。HNSWは、こうした近距離の接続と長距離の接続を組み合わせ、検索の開始点から目的の近傍へ効率よく近づけるようにします。
初心者がつまずきやすい点は、HNSWのグラフが地図のように最初から正解の道を知っているわけではないことです。検索は、現在見えている近傍候補をもとに進みます。そのため、構築時にどの点をどれだけ接続するか、検索時にどれだけ候補を広げるかが結果の品質に影響します。HNSWのパラメータが重要になるのはこのためです。
階層構造で高速化する仕組み
HNSWの特徴は、単なるグラフではなく、階層化されたグラフを使う点です。下位の層には多くの点があり、上位の層に行くほど点の数は少なくなります。検索では、まず上位層の粗いグラフから始め、クエリに近そうな方向へ大きく移動します。その後、下の層へ降りて、より細かく近傍を探します。
これは、地図アプリで目的地を探すときの感覚に少し似ています。最初から細い路地を一つずつ見るのではなく、まず都市全体や主要道路のレベルで方向を決め、その後に地域、通り、建物へと細かく見ていきます。HNSWでも、上位層が大まかな移動、下位層が細かな探索を担当します。
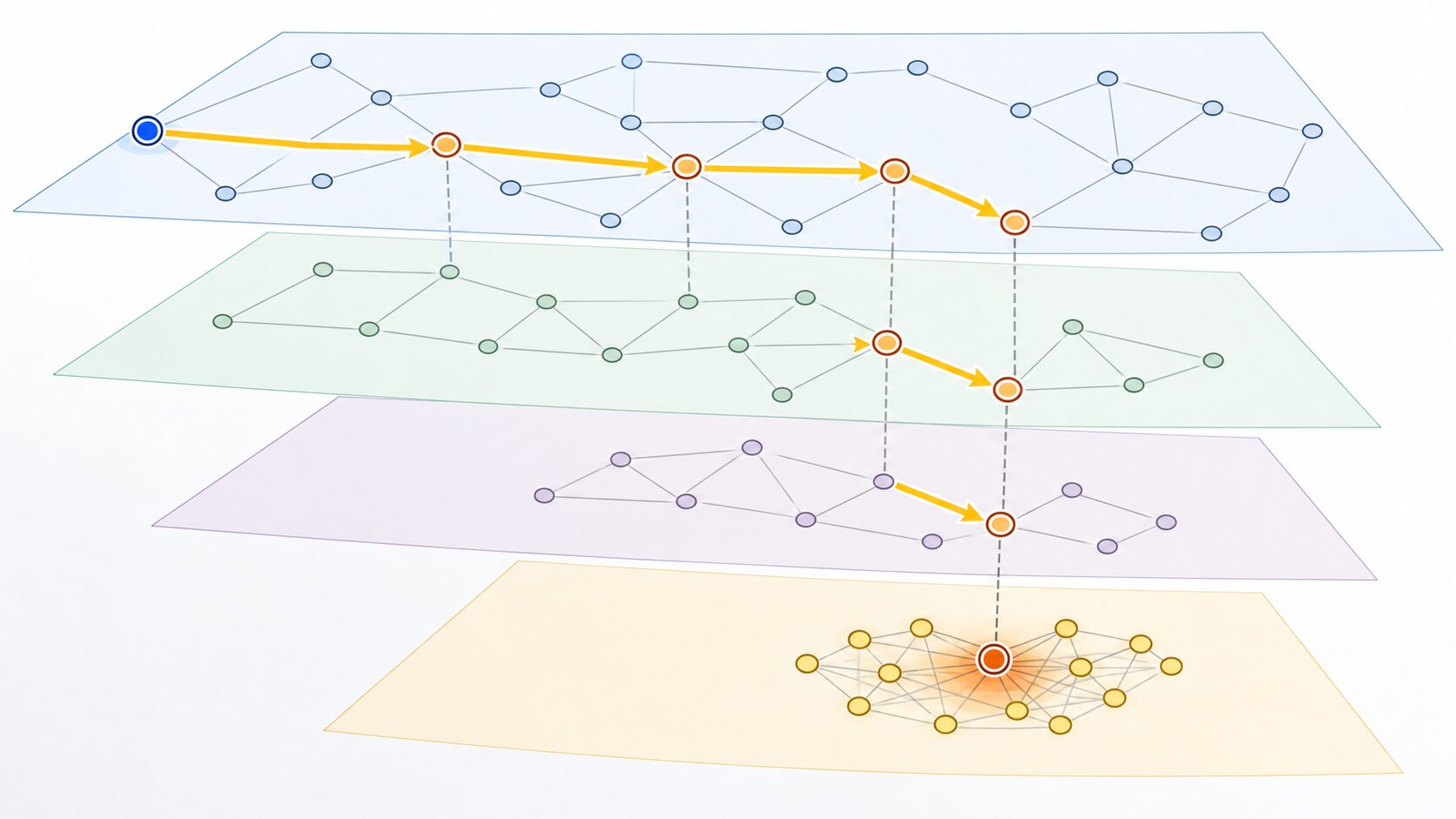
検索の基本は、貪欲探索です。ある点から始めて、その点の近くにある候補のうち、クエリにより近い点へ進みます。より近い点が見つからなくなるまで移動し、次の層へ降ります。最下層では候補集合を少し広げながら、より良い近傍を探します。この流れにより、全件を調べなくても、クエリに近い点の周辺へ到達しやすくなります。
階層構造の利点は、探索の初期段階で大まかな方向を決められることです。点の数が多い最下層だけで探索を始めると、入口によっては目的の領域まで時間がかかる可能性があります。上位層を使うことで、広い空間を粗く移動し、最下層では近い領域だけを重点的に調べられます。
ただし、階層化は魔法ではありません。インデックスを作るときには、各点をどの層に置くか、どの点と接続するかを決める必要があります。接続が少なすぎると目的の近傍へたどり着きにくくなり、接続が多すぎるとメモリを使い、構築や検索も重くなります。HNSWの設計は、グラフを豊かにしすぎず、貧弱にしすぎない調整が重要です。
インデックス構築の流れ
HNSWでは、データを登録するときにインデックスを構築します。新しいベクトルが追加されると、まずそのベクトルがどの層まで参加するかが決まります。多くの点は下位層だけに存在し、一部の点だけが上位層にも現れます。上位層に存在する点が少ないため、上位層は粗いナビゲーション用の地図として機能します。
次に、新しい点の近傍を既存のグラフから探し、近い点と接続します。単純に距離が近い点だけを大量につなぐのではなく、探索に役立つ接続になるように候補を選びます。この接続の作り方が、検索時の到達しやすさに影響します。近い点との接続が十分にあり、かつ別の領域へ移動しやすい接続もあるほど、検索は安定しやすくなります。
構築時には、検索時よりも広い候補を見ながら近傍を選ぶことがあります。なぜなら、構築時に雑な接続を作ってしまうと、その後の検索品質が下がるからです。構築は一度だけ、または更新時だけ行われることが多いため、検索時より多少時間をかけても、良いグラフを作る価値があります。
実務では、インデックス構築はデータ投入時のコストとして現れます。大量の文書を一括で登録する場合、埋め込み生成の時間に加えて、HNSWインデックスの構築時間も見積もる必要があります。データが頻繁に追加されるサービスでは、追加のたびにグラフを更新するコストも考えます。HNSWはオンライン追加に対応しやすい一方、削除や大量更新の扱いは実装によって注意が必要です。
検索時の流れ
検索時には、クエリのベクトルを使って、HNSWグラフの中をたどります。まず最上位層の入口点から始めます。その層で、現在の点よりクエリに近い隣接点があれば移動します。近い点が見つからなくなると、その点を入口として一つ下の層へ降ります。この操作を繰り返し、最下層まで進みます。
最下層では、単に一つの点へ進むだけではなく、候補を複数持ちながら探索します。クエリに近そうな候補を優先し、周辺の隣接点も確認しながら、上位k件の近傍を返します。ここでどれだけ広く候補を見るかが、検索精度と速度に大きく影響します。候補を多く見れば、より良い結果を見つけやすくなりますが、検索時間は長くなります。
この検索の特徴は、全件を均等に調べるのではなく、近そうな場所へ進みながら必要な範囲を重点的に調べることです。全件比較は網羅的ですが重くなります。HNSWは、グラフの構造を使って有望な方向へ進むことで、検索対象を大幅に減らします。
ただし、近似探索である以上、必ず真の最近傍を見つけるとは限りません。入口や接続構造、探索幅によって、より良い候補を見逃す可能性があります。そこで実務では、HNSWで候補を広めに取り、その後に正確な距離計算や再ランキングで順位を整えることがあります。RAGでは、HNSWで関連文書候補を取得し、必要に応じてクロスエンコーダやLLMによる再評価を組み合わせる設計もあります。
主要パラメータ:M、efConstruction、efSearch
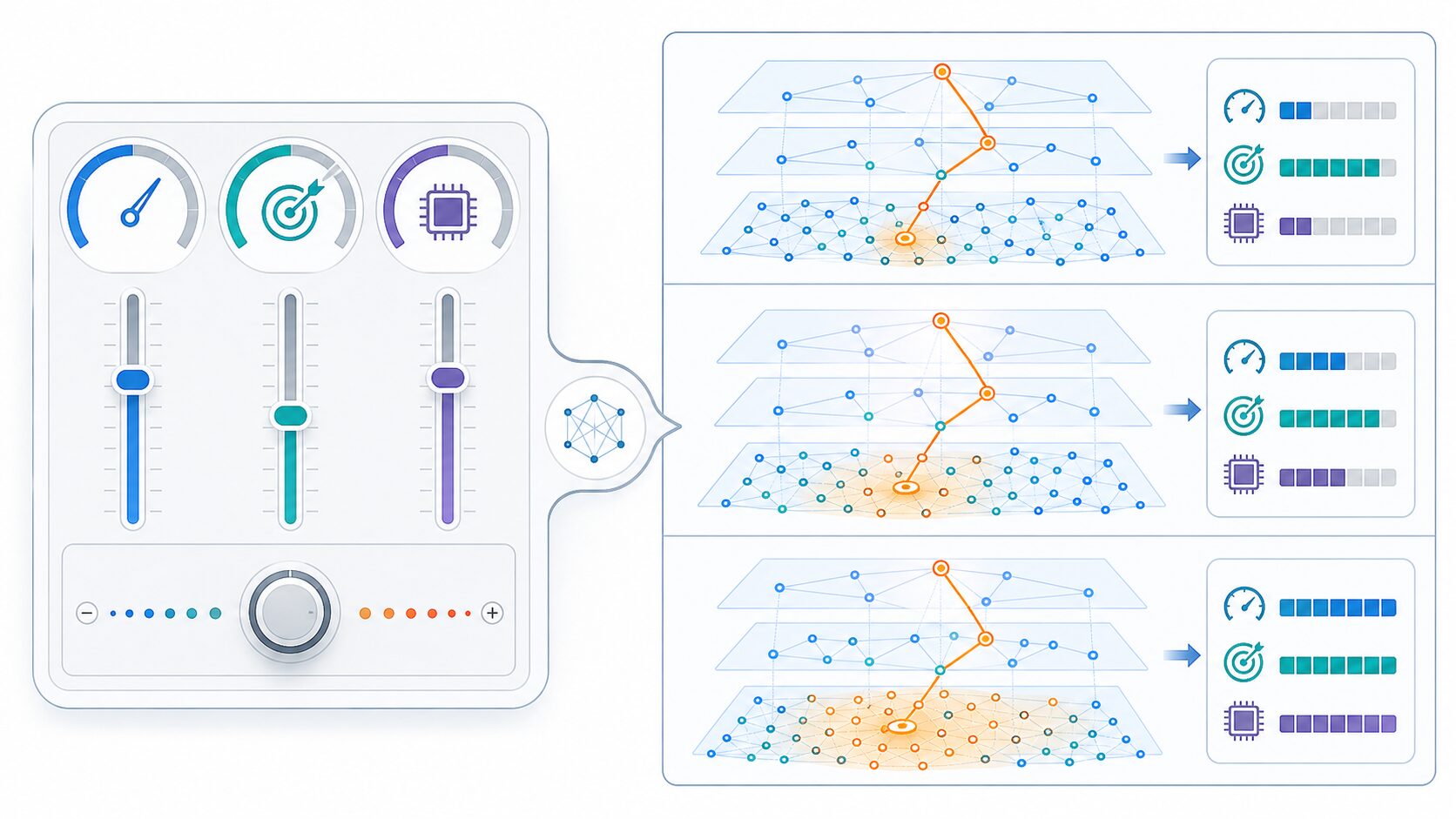
HNSWを使うときに頻繁に出てくるパラメータが、M、efConstruction、efSearchです。製品やライブラリによって名前や初期値は異なる場合がありますが、考え方は共通しています。初心者は、これらを「グラフのつながりの多さ」「構築時にどれだけ丁寧に探すか」「検索時にどれだけ候補を広げるか」と捉えると理解しやすくなります。
Mは、各点が持つ接続数の目安です。Mを大きくすると、点同士のつながりが増え、検索時に良い経路を見つけやすくなる傾向があります。一方で、接続が増えるためメモリ使用量も増えます。構築時間や検索時間にも影響します。Mを大きくすれば常に良いわけではなく、データ量、次元数、メモリ制約に合わせた調整が必要です。
efConstructionは、インデックスを構築するときにどれだけ広く候補を探索するかを表します。大きくすると、より質の高い接続を作りやすくなり、検索精度が上がることがあります。しかし構築時間は長くなります。データを一度構築して長く使うなら、構築に少し時間をかけても検索品質を高める価値があります。頻繁に再構築する運用では、構築時間とのバランスが重要です。
efSearchは、検索時にどれだけ広く候補を持つかを表します。大きくすると精度は上がりやすくなりますが、検索は遅くなります。小さくすると速くなりますが、良い候補を見逃しやすくなります。ユーザー向けのリアルタイム検索では、応答時間の制約を守りながら、評価データで十分な再現率が出る値を探すことになります。
| パラメータ | 意味 | 大きくしたときの傾向 | 注意点 |
|---|---|---|---|
| M | 各点が持つ接続数の目安 | 検索経路が豊かになり精度が上がりやすい | メモリ使用量と構築コストが増えやすい |
| efConstruction | 構築時に見る候補の広さ | 良いグラフを作りやすい | インデックス構築が遅くなりやすい |
| efSearch | 検索時に見る候補の広さ | 近傍を見つける精度が上がりやすい | 検索レイテンシが増えやすい |
調整の基本は、まず評価指標を決めることです。たとえば「真の上位10件のうち何件をHNSWが返せたか」を見る再現率、検索にかかったミリ秒、メモリ使用量、インデックス構築時間などを測ります。値を変えながら、要件を満たす組み合わせを探します。勘だけでパラメータを決めると、過剰なメモリ消費や品質不足に気づきにくくなります。
HNSWとIVF・PQの違い
ベクトル検索を調べると、HNSWのほかにIVFやPQという言葉もよく出てきます。これらは同じ目的、つまりベクトル検索を効率化するために使われますが、発想が異なります。HNSWはグラフをたどって近い点へ進む方法です。IVFはベクトル空間をいくつかの領域に分け、検索時に関連しそうな領域だけを見る方法です。PQはベクトルを圧縮し、メモリ使用量や距離計算のコストを抑える方法です。
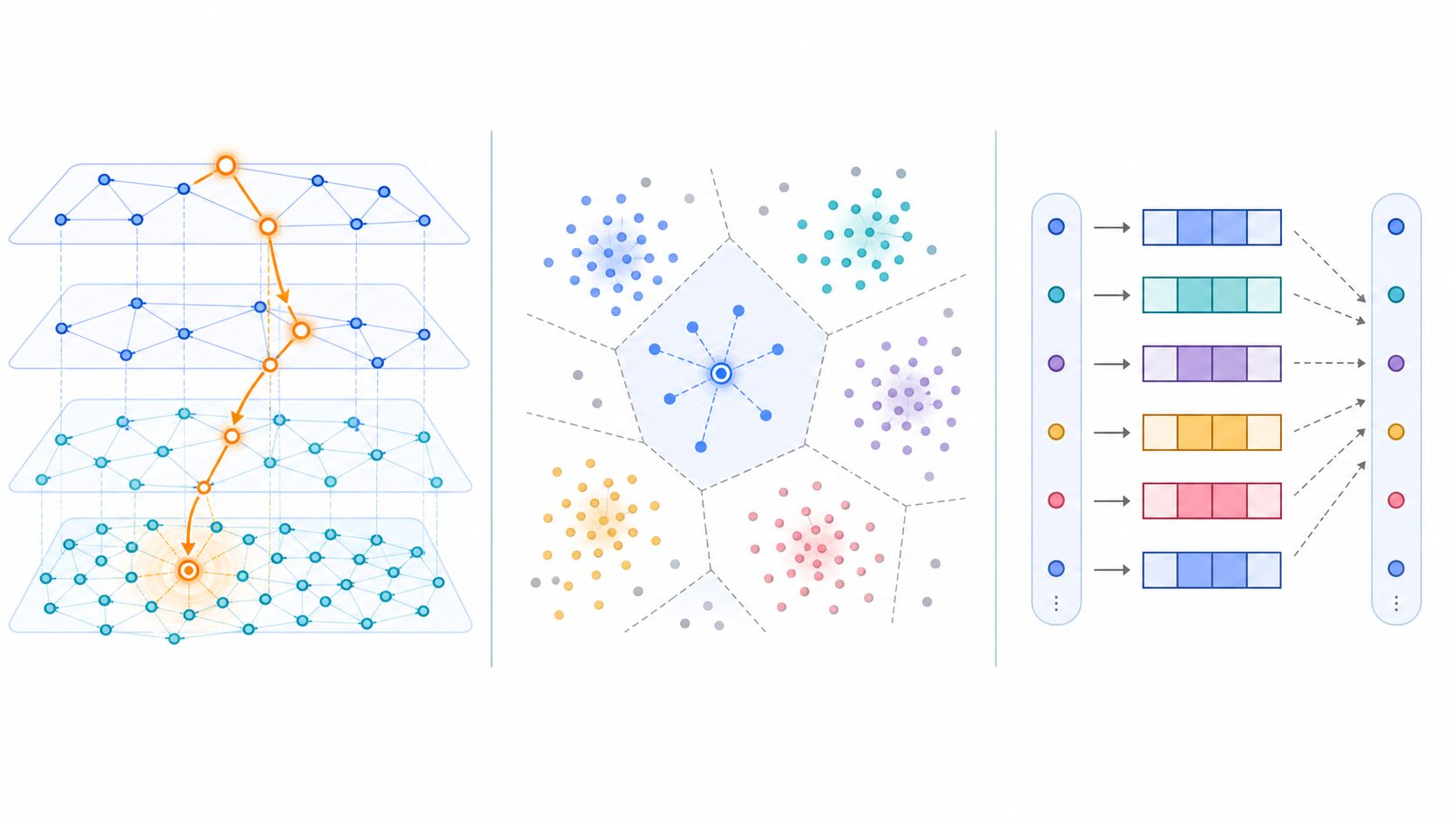
IVFはInverted File Indexの略で、ベクトル空間をクラスタに分け、各データを近いクラスタへ割り当てます。検索時には、クエリに近いクラスタをいくつか選び、その中のデータを詳しく調べます。すべてのデータを見るより速くなりますが、関連するクラスタを見落とすと良い結果を逃すことがあります。クラスタ数や検索するクラスタ数の調整が重要です。
PQはProduct Quantization、直積量子化と呼ばれる圧縮手法です。高次元ベクトルをいくつかの部分に分け、それぞれを代表値で近似することで、元のベクトルより少ないメモリで扱えるようにします。大規模データではメモリ削減が大きな利点になります。一方で、圧縮によって距離計算が近似になるため、精度への影響を評価する必要があります。
HNSW、IVF、PQは排他的なものではありません。システムによっては、IVFとPQを組み合わせたり、HNSWを量子化と組み合わせたりします。選び方は、データ規模、メモリ、更新頻度、求める精度、検索レイテンシによって変わります。初心者はまず「HNSWはグラフ探索」「IVFは空間の粗い分割」「PQはベクトルの圧縮」と整理すると混乱しにくくなります。
| 方式 | 中心となる考え方 | 得意なこと | 注意点 |
|---|---|---|---|
| HNSW | 近い点同士を結ぶ階層グラフを探索する | 高い検索精度と高速性のバランスを取りやすい | メモリ使用量が増えやすく、パラメータ調整が必要 |
| IVF | ベクトル空間をクラスタに分けて候補を絞る | 大規模データで検索対象を減らしやすい | クラスタ設計や検索する領域数で精度が変わる |
| PQ | ベクトルを圧縮して近似的に距離を計算する | メモリ使用量を大きく抑えやすい | 圧縮により検索精度が下がる場合がある |
| 全件比較 | すべてのベクトルと正確に比較する | 考え方が単純で、近似による見落としがない | データ量が増えると検索コストが大きくなる |
HNSWが向いている用途
HNSWは、検索精度を比較的高く保ちつつ、応答速度も重視したい用途に向いています。たとえば社内文書検索では、質問に対して関連性の高い文書チャンクを上位に出す必要があります。見落としが多いとLLMが十分な根拠を得られず、回答品質が下がります。一方で、検索が遅いとユーザーは待たされます。HNSWはこのバランスを取りやすい方法です。
画像検索や商品推薦でもHNSWは有効です。商品の画像ベクトルを保存しておき、ユーザーが見ている商品に近いものを探す場合、完全に同じ商品だけでなく、見た目や特徴が近い候補を素早く出す必要があります。HNSWを使うことで、候補を高速に取得し、その後に価格、在庫、カテゴリ、人気度などで並べ替える設計ができます。
研究開発やプロトタイプでも、HNSWは扱いやすい選択肢です。多くのベクトルデータベースや検索ライブラリでHNSWがサポートされており、設定項目も比較的理解しやすいからです。まずHNSWで検索基盤を作り、データ規模やコストが大きくなった段階で、量子化や別のインデックス方式を検討する進め方もあります。
一方で、極端にメモリ制約が厳しい場合、HNSWだけでは不利になることがあります。グラフの接続情報を保持するため、データ本体のベクトルに加えてインデックス用のメモリが必要になるからです。何十億件規模の検索や、非常に低コストな保存が優先される用途では、圧縮や分散構成を含めた設計が必要になります。
運用で気をつけたいポイント
HNSWを運用で使うときは、まず距離尺度を確認します。コサイン類似度、内積、L2距離など、どの尺度で近さを測るかによって検索結果は変わります。埋め込みモデルが想定する類似度と、インデックス側の距離尺度が合っていないと、期待した結果になりません。ベクトルを正規化する必要があるかどうかも確認します。
次に、フィルタ条件との相性を考えます。実際の検索では「部署が人事の文書だけ」「公開中の商品だけ」「特定カテゴリだけ」のように、メタデータで絞り込むことがあります。HNSWで近い候補を取ってからフィルタすると、条件に合う候補が少なくなる場合があります。逆にフィルタしてからHNSW探索する設計では、グラフの探索効率が変わることがあります。ベクトル検索とメタデータ検索をどう組み合わせるかは、製品や実装ごとの差が出やすい部分です。
更新と削除も重要です。新しいデータの追加は比較的扱いやすい場合が多いですが、削除されたデータの扱いや、既存ベクトルの大量更新には注意が必要です。論理削除で対応する実装では、検索結果から除外されてもインデックス内に古い情報が残り、メモリや性能に影響することがあります。定期的な再構築が必要になるケースもあります。
また、評価データを用意せずに本番投入するのは避けたいところです。検索品質は、サンプルの印象だけでは判断しにくいものです。代表的なクエリ、期待する関連文書、上位k件の再現率、ユーザー行動ログなどを使い、パラメータ変更の前後で比較できるようにします。HNSWの調整は、検索品質評価とセットで行うのが基本です。
初心者が誤解しやすい点
一つ目の誤解は、HNSWを使えば検索結果が意味的に良くなるというものです。HNSWは近いベクトルを探す方法であり、ベクトルそのものを賢くするわけではありません。文章の分割が不自然だったり、埋め込みモデルが用途に合っていなかったり、不要な文書が大量に混ざっていたりすると、HNSWを調整しても根本的な改善にはなりません。
二つ目の誤解は、パラメータを大きくすれば常に正解というものです。M、efConstruction、efSearchを大きくすると精度が上がることはありますが、メモリ、構築時間、検索時間も増えやすくなります。本番では、精度だけでなく、ユーザーが許容できる応答時間、サーバー費用、更新頻度も考える必要があります。
三つ目の誤解は、HNSWが常に最適なインデックスだというものです。HNSWは多くの用途で強力ですが、データ規模が非常に大きい場合や、メモリを極端に抑えたい場合、あるいは厳密なフィルタ条件が多い場合には、別の方式や組み合わせの方が適していることがあります。検索システムでは、手法名だけで選ぶのではなく、評価データで比較することが大切です。
四つ目の誤解は、近似最近傍探索だから品質が低いというものです。近似という言葉は不安に聞こえるかもしれませんが、実務では完全な最近傍よりも、十分に良い候補を高速に得ることが重要な場面が多くあります。RAGでは、上位候補を複数取得して再ランキングや回答生成に渡すため、HNSWの候補取得が十分な再現率を持っていれば、全体として高い品質を出せます。
HNSWを学ぶときの順番
HNSWを学ぶときは、いきなり実装の細部から入るより、検索システム全体の中での役割を押さえる方が理解しやすくなります。まず、埋め込みとは何か、ベクトル同士の距離や類似度とは何かを確認します。次に、全件比較がなぜ重くなるのかを理解します。その上で、近似最近傍探索がなぜ必要になるのかを考えると、HNSWの目的が自然に見えてきます。
次に、グラフ探索の感覚をつかみます。点と点が辺で結ばれており、現在地から近い隣接点へ進むというイメージです。ここで、上位層から下位層へ降りる階層構造を加えると、HNSWの中心的な仕組みになります。最後に、M、efConstruction、efSearchを使って、グラフの豊かさと探索幅を調整することを学びます。
実際に触る場合は、小さなデータセットで全件比較とHNSWの結果を比べると効果的です。クエリをいくつか用意し、全件比較で得た上位結果を基準にして、HNSWがどれだけ同じ候補を返せるかを見ます。efSearchを変えると精度と速度がどう変わるかを測ると、近似探索のトレードオフが具体的に理解できます。
実務での設計例
社内文書RAGを例に考えます。まず文書を適切な長さに分割し、それぞれを埋め込みモデルでベクトル化します。文書ID、部署、公開範囲、更新日などのメタデータも一緒に保存します。次に、ベクトル列に対してHNSWインデックスを作ります。ユーザーが質問すると、質問をベクトル化し、HNSWで近い文書チャンクを取得します。
取得した候補は、そのままLLMへ渡すとは限りません。重複したチャンクをまとめたり、アクセス権限でフィルタしたり、キーワード検索の結果と組み合わせたり、再ランキングで順位を整えたりします。HNSWは候補取得の高速化を担い、最終的な回答品質は、文書整備、検索後処理、プロンプト設計、LLMの能力も含めて決まります。
この設計では、HNSWのパラメータだけでなく、チャンクサイズも重要です。チャンクが短すぎると文脈が足りず、長すぎると関係の薄い情報が混ざります。埋め込みモデルが日本語や業務用語に合っているかも重要です。HNSWは高速な探索経路を提供しますが、検索対象の作り方が悪いと、速く間違った候補を返すだけになってしまいます。
運用が始まったら、ユーザーが検索したクエリ、クリックされた文書、回答に使われた根拠、低評価された回答を確認します。これらをもとに、データの追加、チャンク分割の見直し、メタデータの改善、HNSWのefSearch調整などを行います。検索基盤は一度作って終わりではなく、利用ログと評価を見ながら改善していくものです。
まとめ
HNSW(Hierarchical Navigable Small World)は、ベクトル検索で近いデータを高速に探すための近似最近傍探索インデックスです。近いベクトル同士をグラフで結び、そのグラフを階層化することで、全件比較をしなくても目的の近傍へたどり着きやすくします。生成AIのRAG、意味検索、画像検索、推薦など、ベクトルを使う多くの場面で重要な役割を持ちます。
HNSWの強みは、検索精度と速度のバランスを取りやすいことです。M、efConstruction、efSearchといったパラメータを調整することで、メモリ、構築時間、検索レイテンシ、再現率のバランスを変えられます。一方で、パラメータを大きくすればすべて解決するわけではなく、評価データを使って要件に合う値を探す必要があります。
IVFやPQと比べると、HNSWはグラフをたどる発想が中心です。IVFは空間を分割し、PQはベクトルを圧縮します。どれが最適かはデータ規模、メモリ、更新頻度、フィルタ条件、求める精度によって変わります。まずはHNSWを「階層グラフで近いベクトルへ近づく方法」と理解し、検索システム全体の中でどの問題を解いているのかを意識すると、ベクトルデータベースやRAGの設計を学びやすくなります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2026年5月16日 | 初回公開 |