白色化とは?標準化との違いとデータ前処理での使い方

AIの初心者
『白色化』って標準化と何が違うんですか?どちらもデータを整える処理のようで、区別がつきません。

AI専門家
標準化は、それぞれの特徴量の平均を0、ばらつきを1にそろえる処理だよ。白色化はそこから一歩進んで、特徴量同士の相関も取り除くんだ。
AIの初心者
特徴量同士の相関を取り除く、というのはどういう意味ですか?
AI専門家
例えば身長と体重のように、一方が大きいともう一方も大きくなりやすい関係があるよね。白色化は、そのような重なった情報をほどいて、各特徴量をより独立した見方で扱いやすくする前処理なんだ。
白色化とは。
白色化は、データの平均やばらつきを整えるだけでなく、特徴量同士の相関も取り除く前処理です。標準化との違いを押さえると、機械学習やデータ分析で白色化を使う目的が理解しやすくなります。
白色化とは何か
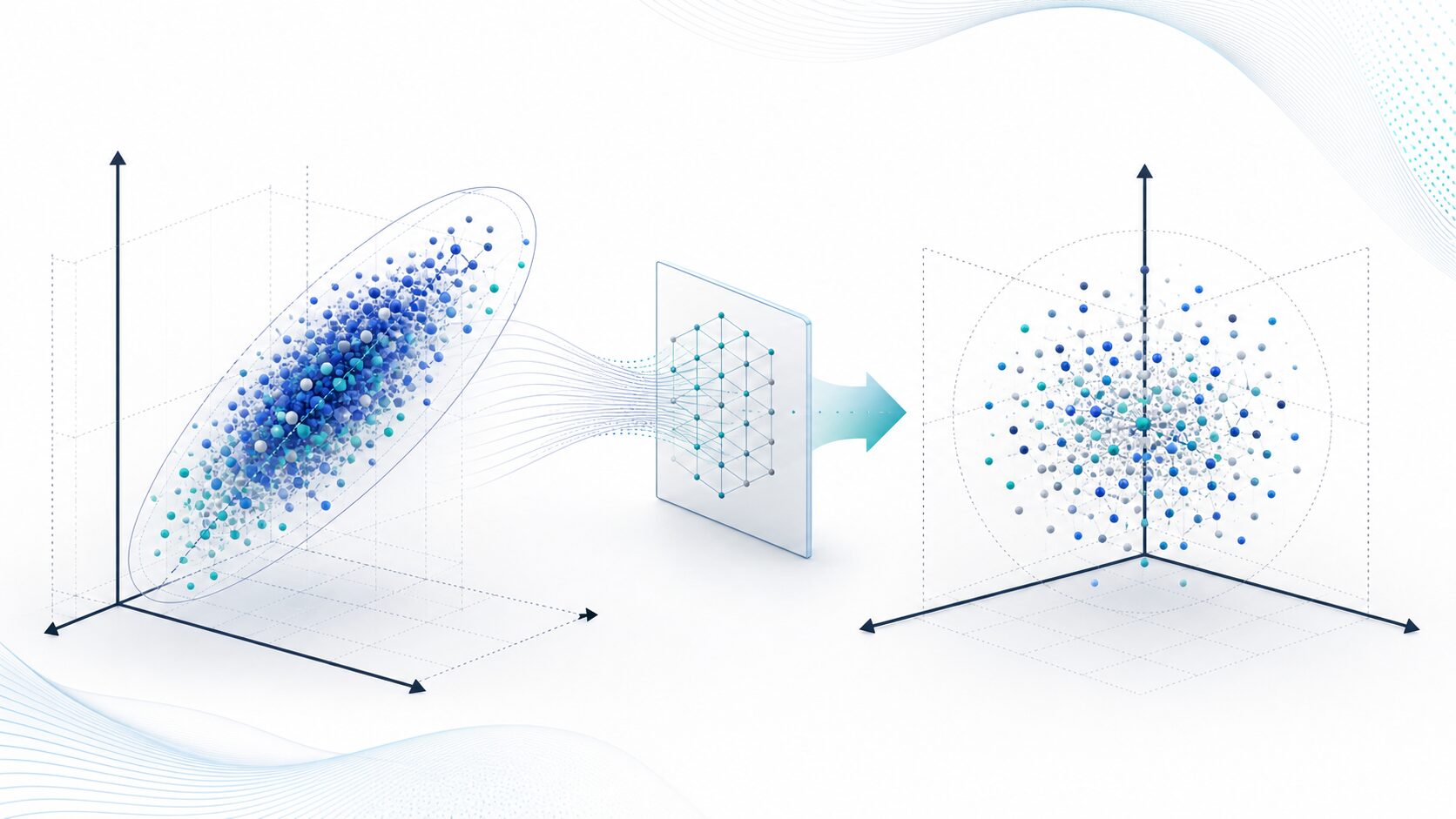
白色化とは、データの特徴量間の相関を取り除き、各成分の分散を1にそろえる前処理です。多くの場合、平均を0にする中心化も含めて扱います。機械学習では、入力データのスケールや相関が学習のしやすさに影響するため、白色化はデータをモデルに渡す前の準備として使われます。
たとえば、身長と体重、住宅の広さと価格、気温とアイスクリームの売上のように、現実の特徴量には互いに関係して動くものがあります。この関係が強いままだと、複数の特徴量が似た情報を重複して持ち、モデルや分析者が本当に見たい特徴を捉えにくくなることがあります。
白色化では、まず特徴量の平均をそろえ、次に共分散行列を使って相関の向きを見つけます。そのうえで、データの座標軸を回転し、各方向のばらつきをそろえます。変換後のデータは、各成分の分散が1に近く、成分同士の共分散が0に近い状態になります。
ただし、白色化で「無相関」になることと、統計的に完全に「独立」になることは同じではありません。無相関は線形の関係が取り除かれた状態を指しますが、非線形な関係まで必ず消えるとは限りません。初学者は、白色化を「特徴量同士の線形な重なりをほどく処理」と理解すると混乱しにくくなります。
標準化との違い
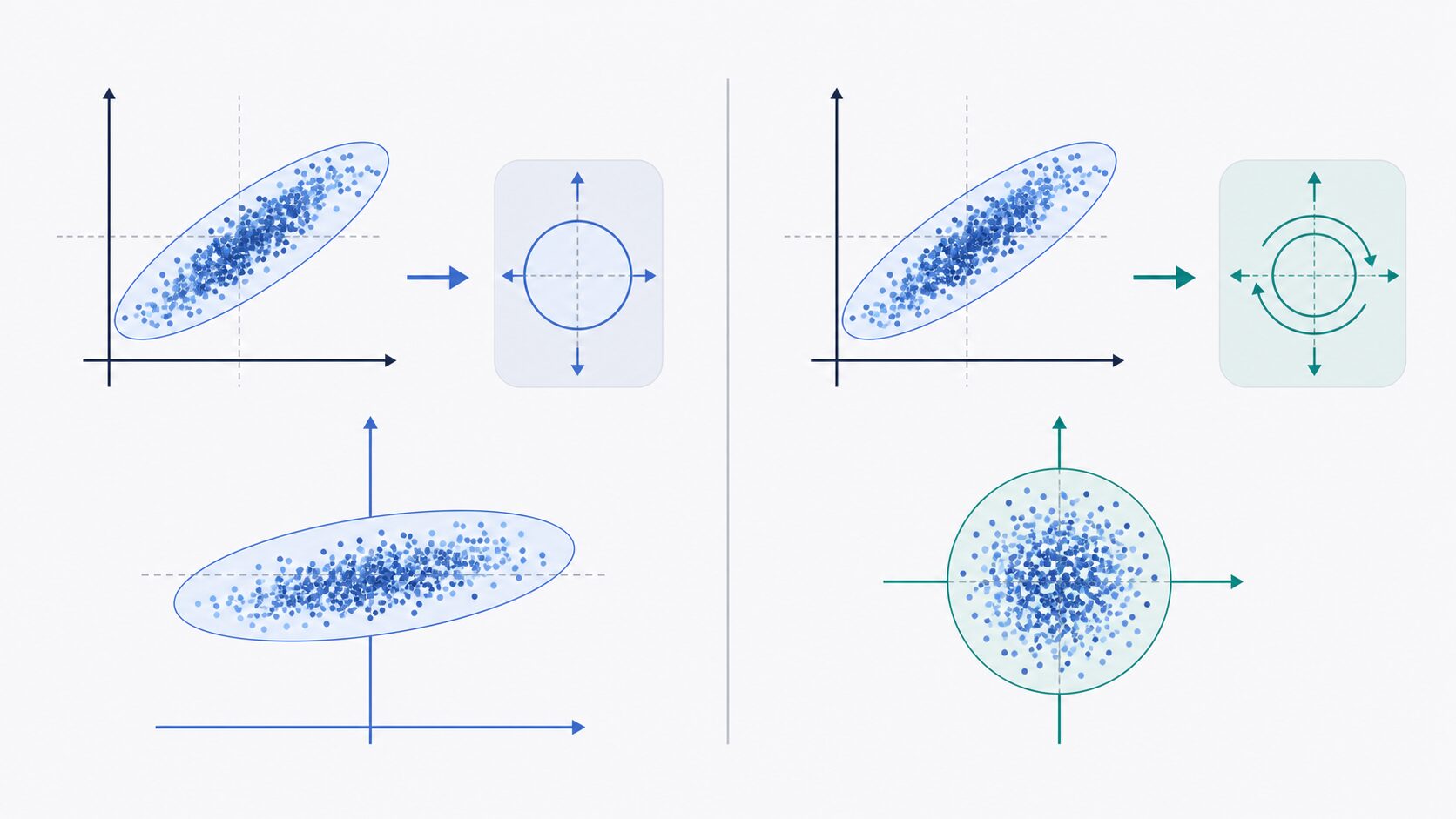
標準化と白色化はどちらもデータ前処理ですが、調整する対象が異なります。標準化は各特徴量の平均と分散を整える処理であり、白色化はそれに加えて特徴量同士の相関も取り除く処理です。
標準化では、テストの点数、売上金額、温度のように単位や桁が異なる特徴量を比較しやすくします。たとえば、片方の特徴量が0から1000、もう片方が0から1の範囲を持つ場合、標準化によって平均0、分散1にそろえると、スケールの違いによる影響を抑えられます。
一方で、標準化だけでは特徴量同士の関係は残ります。国語の点数が高い人は英語の点数も高い傾向がある、身長が高い人は体重も重い傾向がある、といった相関はそのままです。白色化は、このような相関を取り除くことで、重複した情報を減らし、各成分をより扱いやすい形に変換します。
| 項目 | 標準化 | 白色化 |
|---|---|---|
| 主な目的 | 平均を0、分散を1にそろえる | 平均と分散を整え、相関も取り除く |
| 特徴量間の相関 | 基本的に残る | 線形相関を0に近づける |
| 使いどころ | スケールが異なる特徴量を扱うとき | 相関の強い特徴量を整理したいとき |
| 注意点 | 外れ値の影響を受けることがある | ノイズや分布の変化に注意が必要 |
なお、正規化という言葉は文脈によって意味が変わります。0から1の範囲に収める処理を指す場合もあれば、広くデータを整える処理全般を指す場合もあります。白色化を学ぶときは、標準化、正規化、無相関化を同じものとして扱わず、何をそろえ、何を取り除くのかを確認することが大切です。
白色化の計算手順
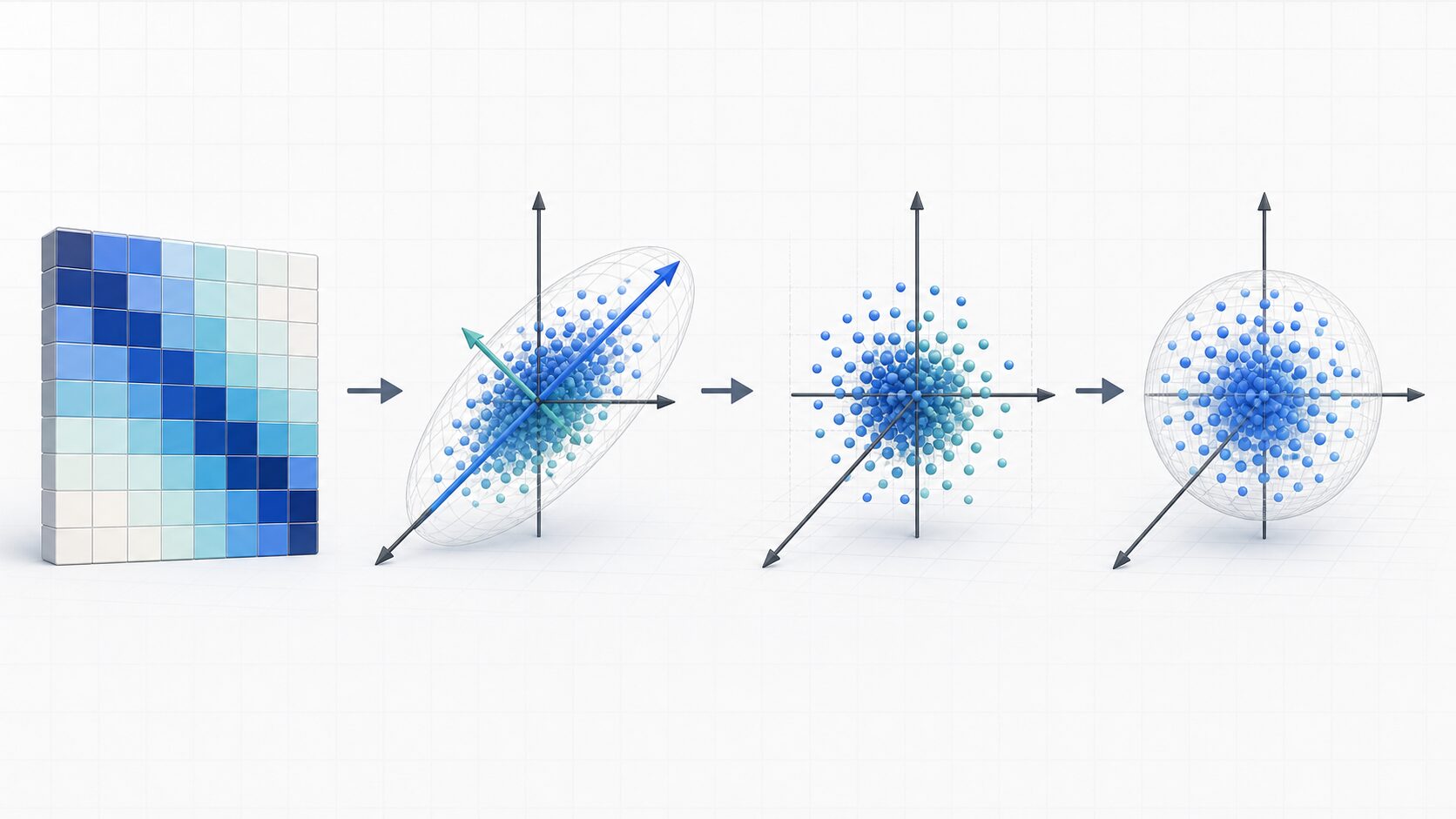
白色化の計算は、見た目ほど複雑な発想ではありません。大まかには、データの中心をそろえ、相関の向きを見つけ、座標軸を回転し、ばらつきの大きさをそろえる処理です。
代表的な手順は次の通りです。まず、各特徴量から平均を引いて中心化します。次に、中心化したデータから共分散行列を計算します。共分散行列は、特徴量同士がどの方向にどれくらい一緒に動くかをまとめた表です。
その後、共分散行列を固有値分解します。固有ベクトルはデータが大きく広がる方向を表し、固有値はその方向のばらつきの大きさを表します。固有ベクトルに沿って座標軸を回転し、固有値の平方根で割ることで、各方向の分散を1にそろえます。
\(X_{\text{white}} = X_c E \Lambda^{-1/2}\)ここで、X_c は平均を引いたデータ、E は固有ベクトルを並べた行列、\Lambda は固有値を並べた対角行列です。この式は、データを相関の方向に合わせて回転し、ばらつきが大きい方向も小さい方向も同じ尺度で見られるようにする操作だと考えると理解しやすくなります。
実務では、固有値が極端に小さいと割り算によってノイズが大きくなることがあります。そのため、固有値に小さな値を足して安定化する、PCAで重要な成分だけを残してから白色化する、といった工夫がよく使われます。
白色化が使われる場面

白色化は、特徴量同士の相関が分析や学習の妨げになりやすい場面で使われます。代表例のひとつが画像認識です。画像では、隣り合う画素の色や明るさが似ていることが多く、画素間に強い相関があります。白色化によってこの相関を弱めると、モデルが局所的な明るさの偏りだけに引っ張られにくくなります。
表形式データでも、似た意味を持つ特徴量が多い場合に白色化が役立つことがあります。たとえば、商品の長さ、幅、重さ、体積のような特徴量は、互いに強く関係している場合があります。白色化は、そうした重複情報を整理し、各成分が持つ情報を見やすくします。
PCAと組み合わせて使われることもあります。PCAはデータのばらつきが大きい方向を見つけ、重要な成分に圧縮する手法です。PCA白色化では、主成分方向に変換したうえで各成分の分散を1にそろえます。これにより、次元削減とスケール調整を同時に行いやすくなります。
一方で、現代の深層学習では、バッチ正規化やレイヤー正規化など別の正規化手法が使われる場面も多くあります。白色化は万能の前処理ではなく、データの相関構造を整理したいときに検討する選択肢のひとつです。
白色化の利点
白色化の大きな利点は、相関の強い特徴量を整理し、学習や分析で扱いやすい形にできることです。特徴量同士が似た情報を持っていると、モデルが特定の方向のばらつきに過度に影響されることがあります。白色化によって各成分の分散をそろえると、モデルは特定の特徴量だけに偏りにくくなります。
また、データの見通しが良くなる点も重要です。相関が強い特徴量をそのまま眺めると、どの特徴量が本質的な情報を持っているのか判断しにくいことがあります。白色化後のデータは、重複した線形情報が減るため、分析の前段階として特徴の整理に役立ちます。
さらに、PCAと組み合わせれば、重要な成分だけを残してデータを軽くできる場合があります。これにより、保存容量や計算時間を抑えられることがあります。ただし、白色化そのものが常に次元を減らすわけではありません。次元削減は、PCAなどで成分を選んだ場合に得られる効果です。
| 利点 | 内容 |
|---|---|
| 相関の整理 | 特徴量同士の重複した線形情報を減らせる |
| 学習の安定化 | 特定の方向のばらつきに引っ張られにくくなる |
| 分析しやすさ | データの構造を別の座標系で確認しやすくなる |
| 次元削減との相性 | PCAと組み合わせると重要成分に絞りやすい |
白色化の注意点

白色化は便利な一方で、使えば必ず性能が上がる前処理ではありません。まず注意したいのは、小さな分散方向に含まれるノイズが強調される可能性です。白色化では各方向の分散を1にそろえるため、もともとばらつきが小さい方向も引き伸ばされます。その方向にノイズが多いと、不要な揺らぎまで目立ってしまいます。
次に、計算コストがあります。共分散行列の計算や固有値分解は、特徴量の数が多いほど重くなります。高次元データをそのまま白色化すると処理時間やメモリ使用量が大きくなるため、PCAで成分を減らす、ミニバッチで近似する、正則化を入れるといった判断が必要です。
また、白色化はデータの分布や解釈性を変えます。元の特徴量が「身長」「体重」「価格」のように意味を持っていたとしても、白色化後の成分は複数の特徴量が混ざった座標になることがあります。そのため、モデルの説明や業務上の解釈を重視する場合は、変換前後で何が変わったのかを確認する必要があります。
機械学習の検証では、データ漏洩にも注意が必要です。白色化に使う平均や共分散行列は、訓練データだけから計算し、検証データやテストデータにはその変換を適用します。全データをまとめて白色化してから分割すると、テストデータの情報が前処理に混ざり、評価が不自然に良く見えることがあります。
| 注意点 | 確認すること |
|---|---|
| ノイズの増幅 | 小さい固有値方向を過度に引き伸ばしていないか |
| 計算負荷 | 特徴量数に対して固有値分解が現実的か |
| 解釈性の低下 | 変換後の成分を業務上どう説明するか |
| データ漏洩 | 平均や共分散を訓練データだけで計算しているか |
まとめ
白色化は、データの平均と分散を整えるだけでなく、特徴量間の相関も取り除く前処理です。標準化が各特徴量のスケール調整を目的とするのに対し、白色化は特徴量同士の重複した線形情報を整理する点に特徴があります。
計算では、中心化、共分散行列の計算、固有値分解、回転とスケーリングを通じて、分散が1で相関が0に近いデータへ変換します。画像認識、相関の強い表形式データ、PCAと組み合わせた前処理などで役立つ場合があります。
ただし、ノイズの増幅、計算コスト、分布の変化、解釈性の低下には注意が必要です。白色化を使うかどうかは、データの相関構造を整理する必要があるか、変換後のデータをどう評価するかを確認したうえで判断するとよいでしょう。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年1月31日 | 初回公開 |
| 2026年5月16日 | 標準化との差分、式の読み方、検証時の注意を補強 |