ベクトルデータベースとは?生成AI時代の検索基盤をわかりやすく解説

AIの初心者
先生、ベクトルデータベースって「意味で検索するためのデータベース」という理解で合っていますか?生成AIやRAGの話でよく聞くのですが、普通のデータベースと何が違うのかが曖昧です。

AI専門家
良い視点です。ベクトル検索は「意味が近い情報を探す技術」ですが、ベクトルデータベースはその検索を実運用で支える保管場所です。ベクトルだけでなく、元の文章、文書ID、権限、更新日時、カテゴリなどのメタデータも一緒に管理します。
AIの初心者
つまり、生成AIに社内資料を参照させるときは、資料をただ保存するだけではなく、検索しやすい形で整理しておく必要があるということですね。
AI専門家
その通りです。専用のベクトルDB、PostgreSQLにpgvectorを入れる構成、Aurora、Azure Database for PostgreSQL、Google AlloyDBのようなクラウドDBなど、選択肢がかなり広がっています。いまは「どれが新しいか」より、用途と運用に合うものを選ぶことが大切です。
ベクトルデータベースとは。
ベクトルデータベースとは、文章・画像・音声などを数値の並びで表した「埋め込みベクトル」を保存し、意味が近いデータを高速に取り出すためのデータベースです。生成AIでは、社内文書や商品情報を検索して回答に渡すRAGの基盤として使われます。
ベクトル検索との違い:この記事で扱う範囲
ベクトル検索は、キーワードが完全一致しなくても意味が近い情報を探す検索方法です。一方、ベクトルデータベースは、その検索を本番環境で安定して動かすための保存・索引・絞り込み・運用の仕組みです。
ベクトル検索そのものの考え方は、関連記事「ベクトル検索とは?意味でつながる新しい検索体験」で詳しく扱っています。本記事では、コサイン類似度などの理論を深掘りするのではなく、AIアプリケーションを作るときに必要になるデータベース層に絞って解説します。
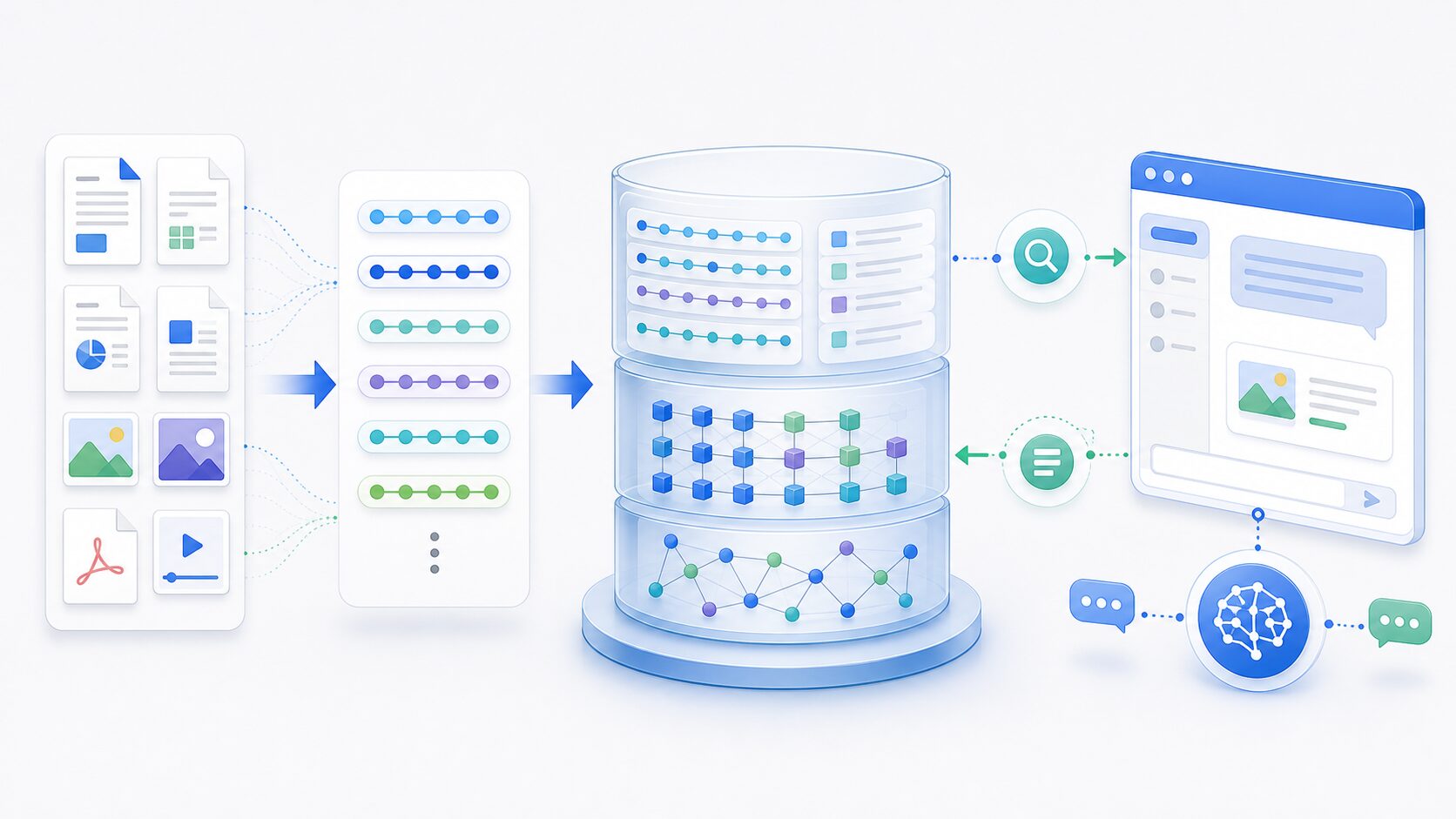
ベクトルデータベースが保存するもの
ベクトルデータベースに入るのは、数字の列だけではありません。実際のRAGや意味検索では、ベクトル、元データ、メタデータ、検索用インデックスをセットで管理することが重要です。
| 保存するもの | 役割 | 例 |
|---|---|---|
| 埋め込みベクトル | 意味の近さを計算するための数値表現 | FAQ、マニュアル、商品説明を変換したベクトル |
| 元テキストまたは参照ID | 検索後に回答へ渡す根拠情報 | チャンク本文、文書ID、URL、ページ番号 |
| メタデータ | 検索対象を絞り込む条件 | 部署、公開範囲、言語、作成日、カテゴリ |
| インデックス | 大量データから近いベクトルを高速に探す仕組み | HNSW、IVFFlat、クラウドDB独自の検索技術 |
特に業務システムでは、単に「似ている文書」を返すだけでは不十分です。ユーザーの権限で見られる文書だけを対象にする、特定の商品カテゴリだけを検索する、古い規程より新しい規程を優先する、といった制御が必要になります。ここでメタデータ設計が効いてきます。
RAGでの使われ方
RAGでは、ユーザーの質問をベクトル化し、ベクトルデータベースから関連する文書片を取り出し、その文書片を生成AIのプロンプトに渡します。生成AIはデータベースそのものを学習するわけではなく、検索で取り出した根拠情報をその場で参照して回答するのが基本です。

一般的な流れは、まず文書を小さな単位に分割し、埋め込みモデルでベクトル化して保存します。質問が来たら質問文もベクトル化し、メタデータ条件を加えながら近い文書を検索します。最後に、検索結果を回答生成用のコンテキストとしてLLMに渡します。
このとき重要なのは、検索順位だけではありません。チャンクの大きさ、重複の持たせ方、検索件数、再ランキング、古い文書の扱い、アクセス権限、ログ監査まで含めて設計しないと、回答品質と運用品質の両方が不安定になります。
現在の選択肢:専用ベクトルDB、PostgreSQL、クラウドDB
ベクトルデータベースの実務選定では、専用ベクトルDBと既存DB拡張の両方を見ます。Pinecone、Qdrant、Milvus / Zilliz Cloudのような専用系は、ベクトル検索を中心に設計されており、大規模検索、リアルタイム更新、メタデータフィルタ、ハイブリッド検索、マルチテナント運用などを前提に機能が強化されています。
Pineconeはサーバーレス構成やBYOCのような運用形態を広げ、Qdrantはオープンソースを軸にCloud、Hybrid Cloud、Private Cloud、Edgeまで展開しています。Zilliz CloudはMilvusをフルマネージドで使えるサービスで、Milvus 2.6系では大規模検索、メタデータフィルタ、全文検索とベクトル検索の組み合わせなどが強化されています。専用ベクトルDBは「検索基盤そのものを外部サービスまたは専用エンジンとして育てたい」場合に候補になります。
一方、PostgreSQL + pgvectorは2026年に突然出てきた新技術ではありません。以前から使われてきた構成ですが、生成AIやRAGの普及により、既存の業務データ、権限、SQL、バックアップ、監査とベクトル検索を同じ運用基盤で扱いたい場面で改めて重要になっています。pgvectorはPostgreSQL上でベクトル類似検索を扱えるオープンソース拡張で、完全一致検索だけでなく近似最近傍検索にも対応します。
pgvectorでは、vectorに加えてhalfvec、bit、sparsevecのような型が使われ、距離計算もL2距離、内積、コサイン距離、L1距離、Hamming距離、Jaccard距離などを扱えます。インデックスではHNSWとIVFFlatがよく使われます。HNSWは検索性能と再現率のバランスが良い一方で、構築時間とメモリ使用量が大きくなりやすい傾向があります。IVFFlatは比較的軽く構築できますが、データ量やチューニングの影響を受けやすい方式です。

クラウドDB側でも、PostgreSQL互換サービスでベクトル検索を扱う選択肢が整っています。Amazon Aurora PostgreSQLはpgvectorを使って埋め込みの保存と類似検索を扱え、Amazon Bedrockのナレッジベース用途でも利用されます。Azure Database for PostgreSQL Flexible Serverもpgvectorをサポートし、PostgreSQL内でベクトル検索を実行できます。Google AlloyDBはpgvector互換性に加え、ScaNNを使ったベクトル検索機能を提供し、SQL、全文検索、ベクトル検索を組み合わせた生成AIアプリケーション構築を打ち出しています。
つまり、現在の選択肢は「専用ベクトルDBか、PostgreSQLか」という単純な二択ではありません。検索規模、更新頻度、レイテンシ、メタデータフィルタ、既存データとの結合、クラウド標準、チームの運用力に応じて、専用DB、PostgreSQL拡張、検索エンジン、クラウドDBを使い分けるのが現実的です。
代表的な選択肢と向いている場面
ベクトルデータベースには、専用サービス、オープンソース製品、PostgreSQL拡張、検索エンジン系、クラウドマネージドDBなど複数の系統があります。選定では、流行している名前よりも、既存システムとの接続性と運用責任の置き場所を先に確認します。
| 選択肢 | 向いている場面 | 確認したい点 |
|---|---|---|
| 専用ベクトルDB | Pinecone、Qdrant、Milvus / Zilliz Cloudなど。大規模な意味検索、低レイテンシ検索、検索品質の細かい調整が重要な場合 | 費用、運用方法、既存データとの同期、メタデータフィルタ性能、ハイブリッド検索、マルチテナント設計 |
| PostgreSQL + pgvector | 既存の業務データがPostgreSQLにあり、SQLやトランザクション管理も一緒に使いたい場合 | データ量、インデックス方式、メモリ、バックアップ、PostgreSQL運用体制 |
| 検索エンジン / マルチモデルDB | 全文検索、フィルタ検索、ベクトル検索を組み合わせたい場合 | 日本語検索、ランキング制御、ハイブリッド検索、運用コスト |
| マネージドクラウドサービス | インフラ管理を抑え、クラウド標準のセキュリティや監視を使いたい場合 | 対応リージョン、拡張機能のバージョン、SLA、閉域接続、料金体系 |

選び方のチェックポイント
最初に見るべきなのは、登録件数だけではありません。検索対象の更新頻度、メタデータ条件の複雑さ、1秒あたりの検索数、許容レイテンシ、既存DBとの距離、セキュリティ要件を合わせて見ます。
小規模な社内RAGや検証用途なら、PostgreSQL + pgvectorで十分なことがあります。既存の顧客DBや商品DBと同じSQLで扱えるため、アプリケーション構成を複雑にしにくいからです。一方で、数千万件以上の高頻度検索、検索ランキングの細かい改善、専用のスケール設計、ハイブリッド検索、低レイテンシの厳格なSLAが必要な場合は、Pinecone、Qdrant、Zilliz Cloud / Milvusなどの専用ベクトルDBや検索エンジン系の選択肢が強くなります。
また、ベクトル検索だけで答えを出そうとしないことも大切です。業務では、キーワード検索、日付や部署による絞り込み、人気度や新しさ、権限情報を組み合わせたハイブリッド検索のほうが安定するケースが多くあります。
運用で失敗しやすいポイント
ベクトルデータベースは導入して終わりではありません。生成AIアプリケーションでは、文書が更新され、埋め込みモデルも変わり、検索ログから改善点が見つかります。検索品質を継続的に測り、更新できる運用設計が必要です。

| 運用項目 | 失敗しやすい点 | 対策 |
|---|---|---|
| メタデータ設計 | 検索後に権限やカテゴリを無理に除外し、必要な結果が消える | 保存時点で部署、権限、文書種別、更新日を設計する |
| チャンク分割 | 細かすぎて文脈が失われる、長すぎて不要情報が混ざる | 文書種別ごとに分割単位を変え、回答例で評価する |
| 埋め込み更新 | 古いモデルのベクトルと新しいモデルのベクトルが混在する | モデル名、生成日時、再生成ジョブを管理する |
| インデックス選択 | 速度だけを見て再現率やメモリを見落とす | HNSW、IVFFlat、完全検索を実データで比較する |
| 監視 | レイテンシと費用だけを見て、検索品質を測っていない | 再現率、クリック、採用文書、回答失敗例をログ化する |
| セキュリティ | 個人情報や閲覧権限を検索結果で漏らす | PII確認、アクセス制御、監査ログ、削除手順を用意する |
参考にしたい公式情報
実装時は、利用する環境の公式ドキュメントで対応バージョンを確認してください。専用DBではPinecone公式リリースノート、Qdrant公式サイト、Zilliz Cloud公式ドキュメントが参考になります。PostgreSQL系ではpgvector公式README、Azure Database for PostgreSQLの対応はMicrosoft Learn、AlloyDBのベクトル検索はGoogle Cloud公式ドキュメント、Aurora PostgreSQLのpgvector利用はAWS公式ドキュメントが参考になります。
まとめ
ベクトルデータベースは、生成AIに「記憶」を与える魔法の箱ではありません。文章や画像をベクトル化し、メタデータや元データと一緒に保存し、必要な情報を高速に取り出すための検索基盤です。
実務では、Pinecone、Qdrant、Zilliz Cloud / Milvusのような専用ベクトルDB、PostgreSQL + pgvector、クラウドDB、検索エンジン系を用途で選び分けます。重要なのは、データ量、検索品質、メタデータ、権限、運用負荷、費用を見ながら、用途に合う構成を選ぶことです。RAGを成功させるには、LLMの性能だけでなく、どの情報をどう保存し、どう取り出すかを設計する必要があります。
更新履歴
- 2026年更新:Pinecone、Qdrant、Zilliz Cloud / Milvusなどの専用ベクトルDB、PostgreSQL + pgvector、Aurora PostgreSQL、Azure Database for PostgreSQL、Google AlloyDBなど、ベクトルDB選定の現行論点を反映しました。