
AIの初心者
『R2』(あるじにじょう)ってなんですか?人工知能や統計の説明でよく見かけるのですが、何を表しているのかが分かりません。

AI専門家
『R2』は、モデルがデータのばらつきをどれくらい説明できているかを示す指標です。日本語では決定係数と呼ばれ、回帰モデルの当てはまりを確認するときによく使います。
AIの初心者
1に近いほど良いと聞いたことがあります。具体的には、どう解釈すればよいのでしょうか?
AI専門家
例えば、家の広さから住宅価格を予測するモデルを考えます。R2が高ければ、価格の違いの多くを広さなどの説明変数で説明できているという意味です。ただし、R2だけで予測モデルの良し悪しを決めるのは危険なので、注意点も一緒に理解しましょう。
統計学や機械学習で回帰モデルを学ぶと、「R2」「R^2」「決定係数」という言葉がよく出てきます。これは、作ったモデルが実際のデータにどれくらいよく当てはまっているかを確認するための代表的な指標です。
結論から言うと、決定係数R2とは、目的変数のばらつきのうち、モデルで説明できた割合を表す数値です。一般には0から1の範囲で解釈され、1に近いほどモデルの当てはまりが良いと考えます。例えばR2が0.8なら、データの変動の約80%をモデルで説明できている、という見方ができます。
ただし、R2は便利な一方で、誤解されやすい指標でもあります。R2が高いからといって、必ず未来のデータを正確に予測できるとは限りません。また、説明変数と目的変数の因果関係を証明するものでもありません。この記事では、決定係数R2の意味、計算式、使いどころ、注意点、調整済み決定係数との違いまで、初心者向けに順番に整理します。
決定係数R2とは
決定係数R2は、主に回帰分析で使われるモデル評価指標です。回帰分析とは、売上、価格、気温、需要、リスクなどの数値を、別の情報から予測したり説明したりするための方法です。
例えば、住宅価格を予測するモデルを考えてみます。住宅価格は、広さ、駅からの距離、築年数、地域、設備など、さまざまな要因によって変わります。このときR2は、住宅価格のばらつきのうち、モデルがどれくらいを説明できたかを数値で示します。
R2が高い場合、モデルの予測値は実際の値に比較的近く、データ全体の傾向をよく捉えていると考えられます。反対にR2が低い場合、モデルだけでは実際の値の変動を十分に説明できていない可能性があります。
重要なのは、R2を「正解率」と同じ意味で捉えないことです。分類モデルで使う正解率とは異なり、R2は回帰モデルにおける当てはまりの良さを表します。「どれだけ当たったか」よりも、「平均だけで考える場合に比べて、モデルがどれだけ説明力を持ったか」を見る指標だと考えると理解しやすくなります。
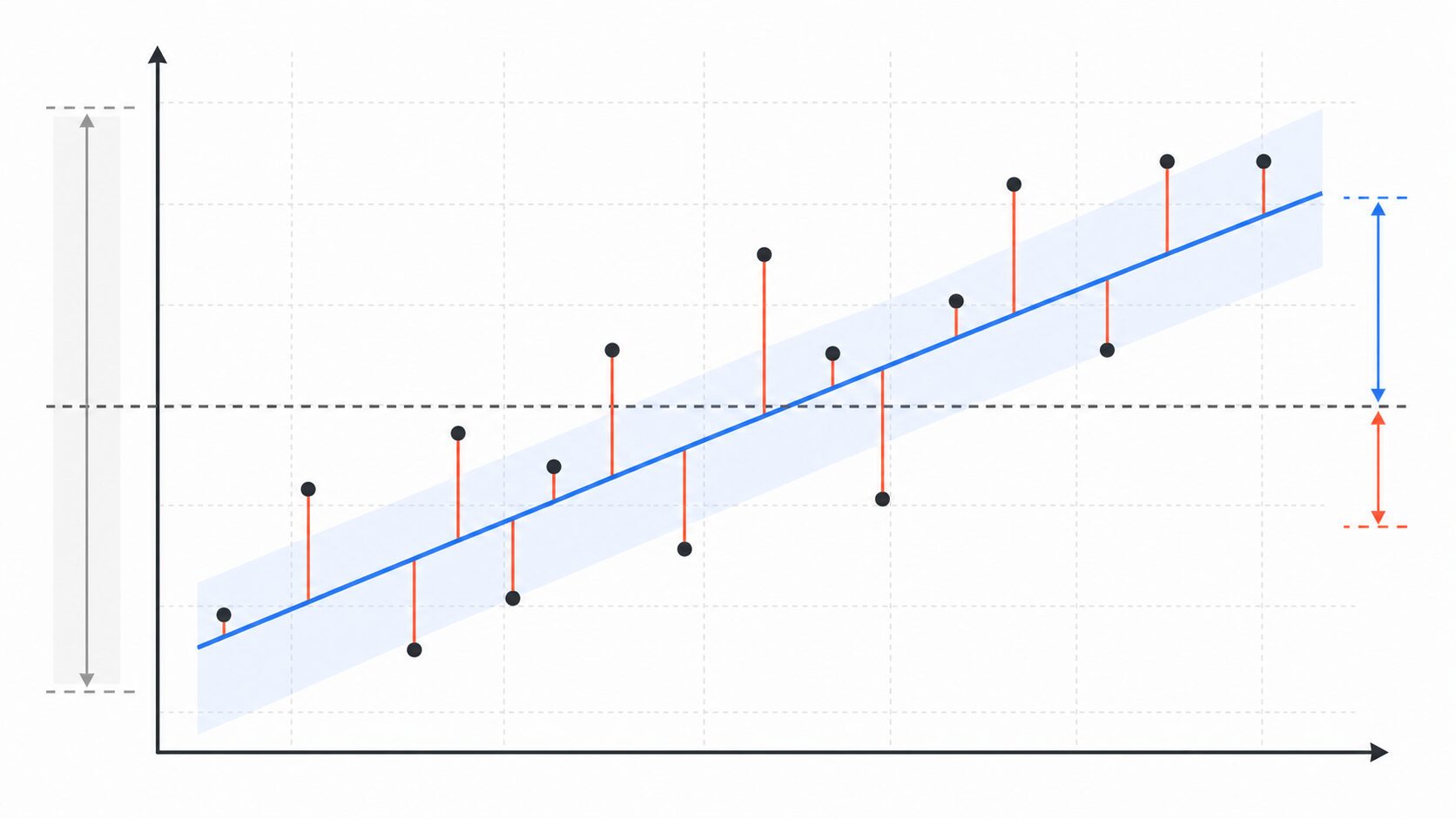
R2の計算式と「ばらつき」の考え方
\(R^2 = 1 – \frac{\sum_{i=1}^{n}(y_i – \hat{y}_i)^2}{\sum_{i=1}^{n}(y_i – \bar{y})^2}\)
R2の代表的な計算式は上の通りです。式だけ見ると難しく感じるかもしれませんが、考え方はシンプルです。R2は、全体のばらつきに対して、予測誤差がどれくらい小さくなったかを見ています。
式の分母にある \(\sum(y_i – \bar{y})^2\) は、実際の値が平均値からどれくらい離れているかを合計したものです。これは「平均値だけで予測した場合のばらつき」と考えられます。分子にある \(\sum(y_i – \hat{y}_i)^2\) は、実際の値とモデルの予測値の差、つまり残差を二乗して合計したものです。
もしモデルの予測が実際の値にかなり近ければ、残差の合計は小さくなります。その結果、分子が小さくなり、R2は1に近づきます。逆に、予測が平均値で考える場合とほとんど変わらなければ、R2は0に近づきます。
このように、R2は単に予測値と実測値の差を見るだけではありません。データ全体のばらつきに対して、その誤差がどれくらい小さいのかを比較している点が特徴です。そのため、同じ誤差でも、もともとのデータのばらつきが大きい場合と小さい場合では、R2の解釈が変わることがあります。
R2の値をどう解釈するか
R2は一般に0から1の間で解釈されます。R2が1に近いほど、モデルがデータの変動をよく説明できている状態です。R2が0に近いほど、モデルの説明力が弱い状態です。
| R2の値 | 解釈の目安 |
|---|---|
| 1に近い | モデルが実測値のばらつきをよく説明できている |
| 0.8程度 | ばらつきの約80%をモデルで説明できていると考えられる |
| 0に近い | 平均値だけで考える場合と比べて、モデルの説明力があまりない |
例えば、R2が0.8の住宅価格モデルなら、価格のばらつきの約8割を、広さや築年数などの変数で説明できていると解釈できます。残りの2割は、モデルに含まれていない要因、データの揺らぎ、測定誤差などによって残っている部分です。
ただし、「R2が何以上なら良いモデルか」は分野や目的によって変わります。物理実験のように規則性が強いデータでは高いR2が期待されることがあります。一方、人間の行動や経済のように不確実性が大きいデータでは、R2がそれほど高くなくても実務上意味のあるモデルになることがあります。
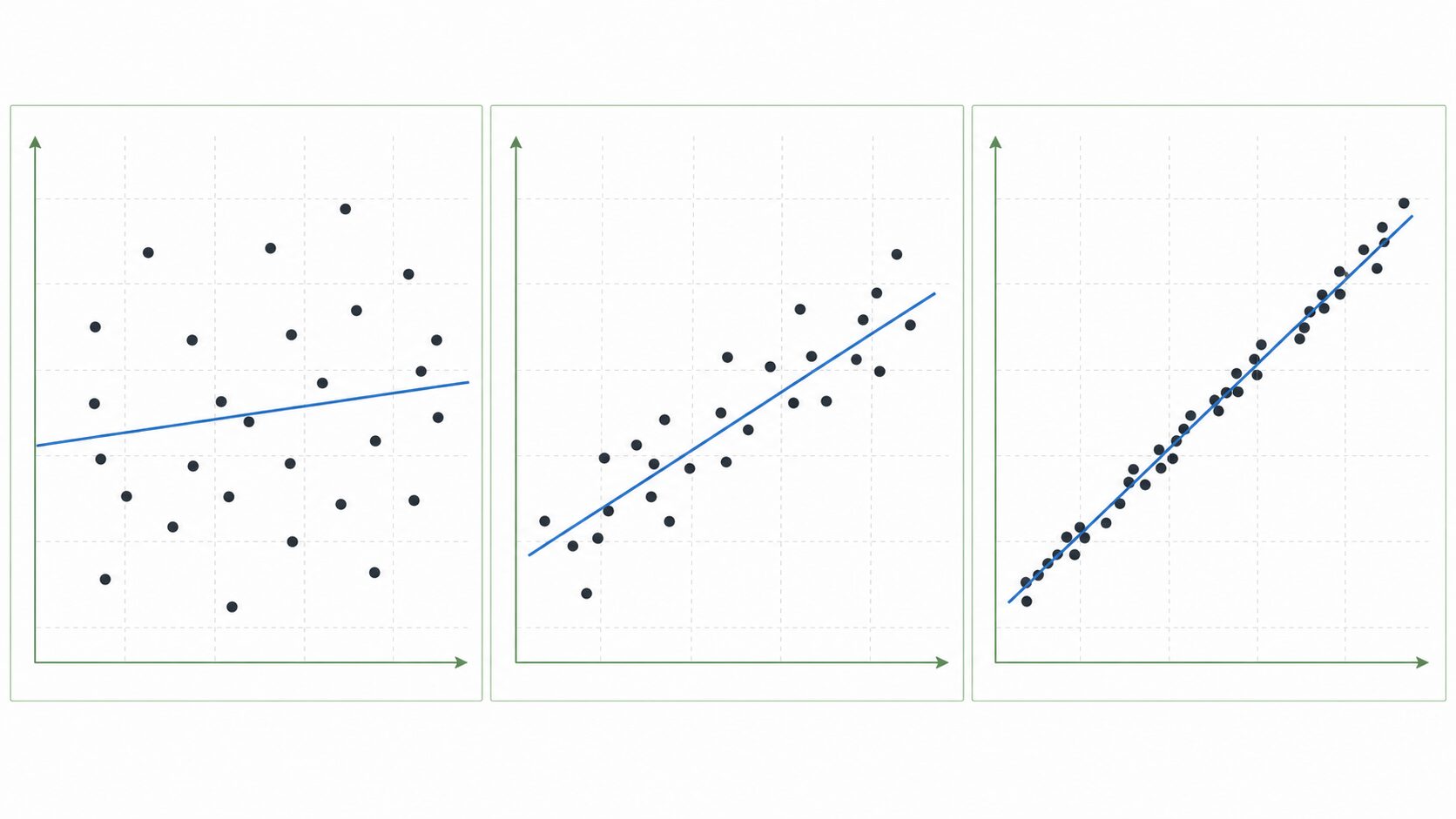
そのため、R2を見るときは数値だけを機械的に判断するのではなく、予測したい対象、データの性質、モデルの使い道を合わせて考えることが大切です。
決定係数R2の活用例
R2は、回帰モデルの評価が必要なさまざまな場面で使われます。機械学習だけでなく、統計学、経済学、医療、マーケティング、品質管理など、数値を予測したり説明したりする分野で広く利用されています。
経済学では、経済成長率や消費額などを説明するモデルの評価にR2が使われます。例えば、労働人口、資本投入、技術革新などを説明変数として経済成長率を予測する場合、R2を見ることで、そのモデルが現実の経済変動をどれくらい説明できているかを確認できます。
投資や金融の分野では、株価やリターンの変動を説明するモデルでR2が使われます。市場全体の動き、金利、業績指標などを使って価格変動を説明しようとするとき、R2はモデルが過去データの動きをどの程度捉えたかを示します。ただし、金融データは将来の不確実性が大きいため、R2が高くても将来の利益を保証するものではありません。
医療やヘルスケアでは、検査値、生活習慣、年齢、遺伝的要因などからリスクや数値指標を予測するモデルでR2が使われることがあります。R2を見ることで、モデルが患者データの変動をどれくらい説明しているかを把握できます。ただし、医療では誤差の大きさ、見逃しのリスク、データの偏りなども重要なので、R2だけで判断することはできません。
AI・機械学習の学習では、住宅価格予測、売上予測、需要予測、気温予測などの回帰タスクでR2をよく使います。モデルを複数作ったときに、どちらがデータの傾向をよく捉えているかを比較する入口として便利です。
R2を見るときの注意点と限界
R2は分かりやすい指標ですが、これだけでモデルの良し悪しを決めるのは危険です。特に注意したいのは、過学習、因果関係の誤解、外れ値の影響、データ分割の問題です。
まず、説明変数を増やすとR2は上がりやすい傾向があります。関係の薄い変数を加えても、学習データに対する当てはまりは見かけ上よくなることがあります。しかし、そのモデルが新しいデータでも同じように当たるとは限りません。このように、学習データに合わせすぎて将来の予測性能が落ちる状態を過学習と呼びます。
次に、R2は因果関係を示す指標ではありません。ある変数を使ったモデルのR2が高くても、その変数が目的変数の原因であるとは言い切れません。例えば、アイスクリームの売上と水難事故の件数に相関があったとしても、アイスクリームが事故の原因とは言えません。どちらも気温の上昇という別の要因に影響されている可能性があります。
また、外れ値があるとR2の値が大きく変わることがあります。極端に大きい値や小さい値が少数含まれているだけで、モデルの当てはまりの見え方が変わる場合があります。R2を見る前に、データの分布や外れ値の有無を確認することも大切です。
さらに、R2は学習データだけでなく、検証データやテストデータでも確認する必要があります。学習データでR2が高く、テストデータでR2が低い場合、そのモデルは学習データにだけ適合している可能性があります。
調整済み決定係数との違い
調整済み決定係数は、説明変数の数を考慮してR2を補正した指標です。通常のR2は、説明変数を増やすと下がりにくく、上がりやすい性質があります。そのため、変数をたくさん入れた複雑なモデルほど良く見えてしまうことがあります。
調整済み決定係数は、この問題を和らげるために使われます。説明変数を増やしても、モデルの改善が十分でなければ値が上がりにくくなります。つまり、複雑さに見合うだけ説明力が増えたかを確認しやすい指標です。
| 指標 | 特徴 | 使いやすい場面 |
|---|---|---|
| 決定係数R2 | データのばらつきをどれだけ説明できたかを見る | 単純な回帰モデルの当てはまりを確認する |
| 調整済み決定係数 | 説明変数の数を加味してR2を補正する | 説明変数の数が異なるモデルを比較する |
例えば、住宅価格を予測するモデルで、広さだけを使うモデルと、広さ、築年数、駅距離、部屋数、地域、設備などを使うモデルを比較するとします。通常のR2は後者のほうが高くなりやすいですが、それが本当に実務上役立つ改善なのかは別問題です。このような場面では、調整済み決定係数を見ることで、変数を増やした価値を判断しやすくなります。
MAE・RMSEなど他の評価指標との使い分け
R2はモデルの説明力を把握するのに便利ですが、誤差の大きさそのものを知りたい場合には、MAEやRMSEなどの指標も重要です。
MAEは平均絶対誤差で、予測値と実測値の差の絶対値を平均したものです。単位が元データと同じなので、「住宅価格の予測が平均で何万円ずれているか」のように実務的に理解しやすい指標です。
RMSEは二乗平均平方根誤差で、大きな誤差をより強く評価します。大きく外す予測を避けたい場合に役立ちます。例えば需要予測や在庫管理では、大きな誤差が損失につながることがあるため、RMSEも確認すると判断しやすくなります。
| 指標 | 見ているもの | 注意点 |
|---|---|---|
| R2 | データのばらつきをどれだけ説明できたか | 高くても過学習や因果関係の誤解に注意 |
| 調整済みR2 | 説明変数の数を考慮した説明力 | 複数モデル比較で特に有用 |
| MAE | 平均的な誤差の大きさ | 大きな誤差を特別に重く扱わない |
| RMSE | 大きな誤差を重く見た誤差の大きさ | 外れ値の影響を受けやすい |
実務では、R2だけを見るのではなく、R2で説明力を確認し、MAEやRMSEで誤差の大きさを確認し、さらに検証データで性能が保たれているかを見る、という使い方が現実的です。
まとめ
決定係数R2は、回帰モデルがデータのばらつきをどれくらい説明できているかを示す指標です。R2が1に近いほど、モデルは実測値の変動をよく説明できていると考えられます。R2が0.8なら、データの変動の約80%をモデルで説明できている、というイメージです。
一方で、R2が高いからといって必ず良いモデルとは限りません。説明変数を増やしすぎると過学習が起こることがありますし、R2は因果関係を証明するものでもありません。外れ値やデータの分割方法によっても解釈が変わります。
R2を正しく使うには、調整済み決定係数、MAE、RMSE、検証データでの性能なども合わせて確認することが大切です。R2はモデル評価の入口として非常に便利ですが、最終判断は複数の指標とデータの背景を合わせて行いましょう。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月1日 | 決定係数R2の意味、計算式、値の読み方、調整済みR2との違い、評価時の注意点を初心者向けに再構成 |