学習
学習 学習データのカットオフ:適切な活用で精度向上
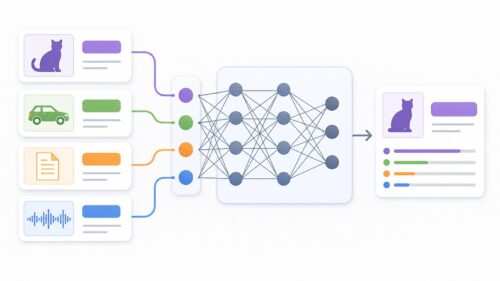
機械学習の模型を作るには、たくさんの情報が必要です。しかし、良い模型を作るには、情報の量だけでは足りません。情報の質も大切です。そこで「学習情報の切り捨て」という考え方が出てきます。これは、ある基準に基づいて、学習に使う情報の一部をわざと除外する方法です。まるで彫刻家がノミでいらない石を削り落として作品の形を整えるように、情報の切り捨ては情報の集まりからいらない部分を取り除き、模型の学習に最適な情報の組み合わせを作り上げます。
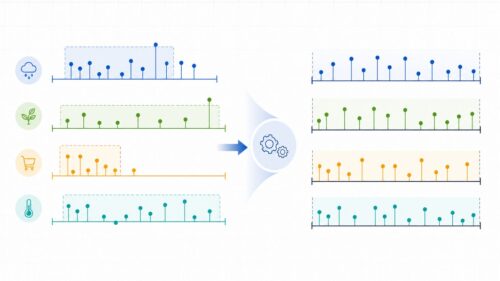
具体的には、ある期間外の情報や、ある条件を満たさない情報などを除外します。たとえば、最新の流行を予測する模型を作る場合、数年前のデータは現在の状況を反映していないため、学習データから除外することが考えられます。あるいは、特定の地域における商品の売れ行きを予測する模型を作る際に、他の地域の情報はかえって予測の精度を下げてしまう可能性があるため、除外する必要があるかもしれません。このように情報の切り捨ては、模型が雑音や古い情報に惑わされることなく、本当に大切な情報に集中して学習できるようにするための大切な作業です。
情報の切り捨てによって、模型の正確さや信頼性を高めることができます。しかし、どのような情報を切り捨てるかは、目的に合わせて慎重に決める必要があります。切り捨てる基準を誤ると、重要な情報を失い、かえって模型の性能を低下させてしまう可能性があるからです。そのため、情報の切り捨てを行う際には、事前にデータの特性を十分に理解し、適切な基準を設定することが不可欠です。また、切り捨てた情報が本当に不要であったかを確認するために、切り捨て前と後の模型の性能を比較することも重要です。