データ正規化と重みの初期化

AIの初心者
先生、「データの正規化」と「重みの初期化」って、何だか難しそうでよくわからないです…。具体的にどんなことをするんですか?

AI専門家
そうだね、少し難しいかもしれないね。例えば、アパートの家賃を、広さと築年数から予測するAIを作るとしよう。このとき、広さは平方メートル、築年数は年数で表されるよね。これらの単位はバラバラで、そのままではAIがうまく学習できないんだ。そこで、「データの正規化」が必要になる。これは、例えば0から1までの範囲のように、全てのデータを同じ範囲に収める処理のことだよ。
AIの初心者
なるほど。つまり、色々な単位のデータを、AIが理解しやすいように同じスケールに変換するってことですね。それで、「重みの初期化」はどういう処理をするんですか?
AI専門家
AIは、入力されたデータに重みをかけて計算するんだけど、この重みを適切に初期化しないと、うまく学習が進まないんだ。「重みの初期化」とは、AIの学習を始める前に、この重みを適切な値に設定すること。例えば、重みに偏りがないように、ランダムに値を割り振るんだよ。適切な初期値を設定することで、AIはスムーズに学習を進めることができるようになるんだ。
データの正規化・重みの初期化とは。
人工知能を扱う際に、『データの整え方と重さの最初の決め方』という大切な用語があります。データの整え方とは、データを扱う前段階として、全ての数値を0から1の範囲に置き換えることです。重さの最初の決め方とは、模型の重さに偏りがでないように、学習を始める前に、平均的な分布になるよう重さを最初に決めておくことです。例えば、貸家の広さと築年数から家賃を予想する場合、「平方メートル」と「年数」というように、数値の大きさが大きく異なる二つの単位が使われます。この違いは、模型の学習の正確さを悪くするため、0から1の範囲に整えることで、数値の範囲を統一します。また、重さの最初の値によっては、特定の部分が全く働かなくなったり、逆に働きすぎたりといった悪い影響が出てしまうため、学習の準備として、重さを最初に決めておく必要があります。
正規化の目的

情報をうまく扱う機械を作るには、準備段階がとても大切です。その中でも、情報の整え方の一つである「正規化」は重要な役割を担います。正規化とは、様々な範囲に散らばっている情報を、決められた範囲、例えば0から1の間に収めるように変える作業のことです。では、なぜこのような作業が必要なのでしょうか。
たとえば、賃貸物件の値段を予想する機械を想像してみてください。この機械には、物件の広さ(平方メートル)と築年数(年)の情報を与えるとします。広さと築年数は、単位も範囲も全く違います。もし、そのまま機械に情報を与えると、広さの情報ばかりが重視され、築年数の情報が軽視される可能性があります。つまり、機械が正しく学習できないのです。
正規化を行うことで、これらの情報の範囲を同じように揃え、機械がすべての情報を受け入れやすくします。これは、すべての情報を同じように大切にするということです。そうすることで、機械の学習速度と正確さが向上します。
また、正規化は情報の偏りをなくす効果もあります。例えば、ある情報が極端に大きな値を持つ場合、その情報が機械の学習に過剰な影響を与えてしまうことがあります。正規化によって値の範囲を調整することで、このような偏りを防ぎ、より安定した結果を得ることができます。
さらに、正規化は異なる種類の情報を比較しやすくするという利点もあります。例えば、身長と体重のように単位も範囲も異なる情報を比較する場合、正規化によって両者を同じ尺度に変換することで、より意味のある比較が可能になります。このように、正規化は機械学習において、データの前処理として非常に重要な役割を果たしているのです。
| 正規化のメリット | 説明 |
|---|---|
| 情報の均一化 | 広さや築年数など、単位や範囲の異なる情報を同じ尺度に変換し、機械がすべての情報を受け入れやすくする。 |
| 学習速度と正確さの向上 | すべての情報を同じように扱うことで、機械学習の効率と精度が向上する。 |
| 情報の偏りの解消 | 極端に大きな値を持つ情報が学習に過剰な影響を与えることを防ぎ、安定した結果を得られるようにする。 |
| 異なる種類の情報の比較 | 身長と体重など、異なる種類の情報を同じ尺度に変換することで、比較を容易にする。 |
正規化の方法

数値データを扱う際、値の範囲や分布の違いが解析結果に影響を与えることがあります。これを防ぐため、データを一定の範囲や分布に変換する手法を正規化と呼びます。様々な正規化の方法がありますが、それぞれに特徴があり、適切な方法を選ぶことが大切です。データの特性や解析の目的に合わせて、最適な正規化手法を選択することで、より正確で信頼性の高い結果を得ることができます。
代表的な正規化手法の一つに、最小最大正規化があります。この手法では、データ全体の中で最も小さい値を0に、最も大きい値を1に変換します。そして、その他の値も0から1の範囲に収まるように、元のデータの大小関係を保ったまま比例的に変換します。この手法は、データの範囲を限定したい場合や、異なる単位のデータを比較したい場合に有効です。例えば、テストの点数を0点から100点の範囲から0から1の範囲に変換することで、異なる教科の点数を比較しやすくなります。
一方、標準化と呼ばれる正規化手法もあります。標準化では、データの平均値を0に、標準偏差を1に変換します。つまり、変換後のデータは平均値を中心とした分布になり、データのばらつき具合が標準偏差1で表されます。標準化は、外れ値と呼ばれる極端に大きい値や小さい値の影響を受けにくいという利点があります。最小最大正規化では、外れ値があると、他のデータが狭い範囲に押し込められてしまう可能性がありますが、標準化では外れ値の影響が軽減されます。そのため、外れ値が含まれるデータに対しては、標準化がより適切な場合が多いです。
このように、正規化には様々な方法があり、それぞれ異なる特徴を持っています。最小最大正規化は値の範囲を調整するのに適しており、標準化は外れ値の影響を軽減するのに適しています。データの性質や分析の目的を理解し、適切な正規化手法を選択することが重要です。
| 正規化手法 | 特徴 | メリット | デメリット | 適用例 |
|---|---|---|---|---|
| 最小最大正規化 | データを0から1の範囲に変換 | 値の範囲を限定、異なる単位のデータを比較可能 | 外れ値の影響を受けやすい | テストの点数変換 |
| 標準化 | 平均0、標準偏差1に変換 | 外れ値の影響を受けにくい | データの範囲は限定されない | 外れ値を含むデータの処理 |
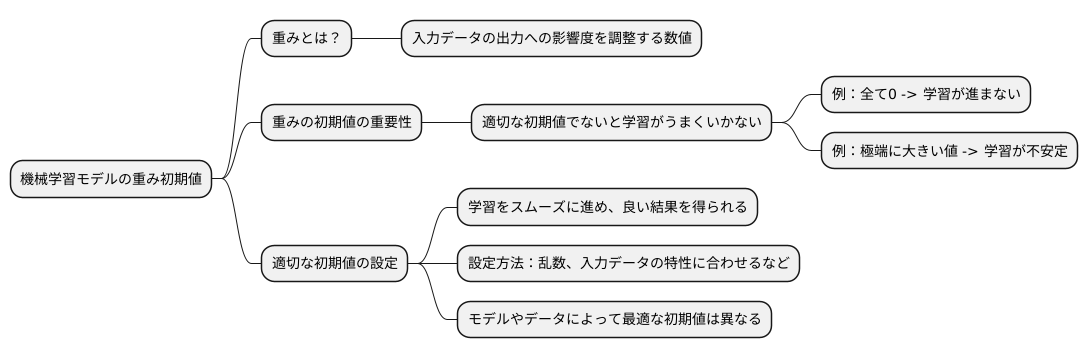
重みの初期化

機械学習のモデルは、たくさんのつまみを回して調整するように、たくさんの数値を調整することで学習していきます。この調整する数値のことを重みと呼びます。重みは、入力データがどれくらいモデルの出力に影響を与えるかを調整する重要な役割を担っています。この重みの初期値、つまり学習を始める前の値の設定が、学習の成否に大きく関わってきます。
適切な初期値を設定しないと、モデルがうまく学習できず、正しい答えにたどり着けないことがあります。例えば、全ての重みを0に設定してしまうと、全ての部分が同じように動いてしまい、学習が全く進みません。これは、たくさんの計算をする部分があるのに、全て同じ計算をしている状態なので、調整する意味がなくなってしまうからです。また、逆に極端に大きな値で初期化すると、特定の部分だけが過剰に反応してしまい、学習が不安定になります。これは、特定の部分だけが過剰に影響を与えてしまい、他の部分が無視されてしまうからです。まるで、オーケストラで一つの楽器だけが異常に大きな音を出すと、全体の調和が崩れてしまうようなものです。
このような問題を避けるためには、重みの初期値を適切に設定することが重要です。初期値の設定方法は様々で、乱数を使う方法や、入力データの特性に合わせて設定する方法などがあります。適切な初期値を設定することで、学習をスムーズに進めることができ、より良い結果を得ることができます。適切な初期値の選び方は、モデルの種類や扱うデータによって異なるため、状況に応じて適切な方法を選択する必要があります。丁度、料理によって最適な味付けが異なるように、モデルの種類やデータによって最適な重みの初期値も異なります。
重みの初期化方法

機械学習モデルの学習において、重みの初期値設定は学習の成否を大きく左右する重要な要素です。適切な初期値を設定することで、学習速度の向上や精度の改善が見込めます。逆に不適切な初期値を設定すると、学習がうまく進まず、良い結果が得られない可能性があります。
重みの初期値設定には様々な方法があり、それぞれに特徴があります。よく使われる方法の一つに、正規分布に基づいた初期値設定があります。正規分布とは、平均値を中心とした左右対称な山型の分布で、自然界の現象によく見られる分布です。この正規分布を用いることで、重みにばらつきを持たせることができます。ばらつきを持たせることで、モデルは多様なパターンを学習できるようになり、より複雑な問題にも対応できるようになります。初期値のばらつき具合は、正規分布の標準偏差という値で調整できます。
正規分布以外にも、一様分布に基づいた初期値設定もよく用いられます。一様分布とは、一定の範囲内で全ての値が等しい確率で現れる分布です。こちらも重みにばらつきを持たせる効果がありますが、正規分布に比べて値の分布が均一であるため、特定の範囲に偏った初期値を避けることができます。
近年では、使用する活性化関数に特化した初期値設定方法も提案されています。活性化関数とは、モデルの出力を調整する関数のことです。活性化関数の種類によって、適切な初期値の範囲や分布が異なります。例えば、「シグモイド関数」や「ハイパボリックタンジェント関数」といった活性化関数に対しては、特定の初期値設定方法を用いることで、学習効率を向上させることができます。
このように、重みの初期値設定には様々な方法があり、モデルの構造や使用する活性化関数によって最適な方法が異なります。適切な初期値設定方法を選ぶことで、モデルの学習をスムーズに進め、より高い精度を実現できる可能性が高まります。そのため、様々な初期値設定方法を試してみて、最適な方法を選択することが重要です。
| 重みの初期値設定方法 | 説明 | 特徴 |
|---|---|---|
| 正規分布に基づいた初期値設定 | 平均値を中心とした左右対称な山型の分布に従って初期値を設定する。 | 重みにばらつきを持たせることで、多様なパターンを学習できる。標準偏差でばらつき具合を調整可能。 |
| 一様分布に基づいた初期値設定 | 一定の範囲内で全ての値が等しい確率で現れる分布に従って初期値を設定する。 | 重みにばらつきを持たせる。正規分布に比べて値の分布が均一。特定の範囲に偏った初期値を避けることができる。 |
| 活性化関数に特化した初期値設定 | 使用する活性化関数に適した初期値を設定する。 | 活性化関数の種類によって、適切な初期値の範囲や分布が異なる。学習効率を向上させることができる。 |
初期化と正規化の関係

機械学習の分野では、学習を始める前にデータを整えたり、重みの初期値を適切に設定したりすることがとても大切です。この作業を怠ると、学習がうまく進まなかったり、良い結果が得られなかったりすることがあります。
データの正規化は、入力データの範囲を調整する作業です。例えば、あるデータの範囲が0から100で、別のデータの範囲が0から1だとします。この2つのデータをそのまま一緒に学習に使うと、範囲の広いデータの影響が大きくなりすぎて、範囲の狭いデータの特徴がうまく学習できない可能性があります。そこで、正規化によって、すべてのデータの範囲を同じにすることで、それぞれのデータの特徴が平等に学習されるようにします。よく使われる方法として、すべてのデータを0から1の範囲に揃える方法などがあります。
重みの初期化は、学習の開始時に、モデルの重みに適切な初期値を設定する作業です。重みは、モデルが学習を進める上で非常に重要な役割を果たします。もし、重みの初期値が適切でないと、学習がうまく進まないことがあります。例えば、すべての重みを0に設定してしまうと、モデルは全く学習できません。また、重みの初期値が大きすぎると、学習の途中で値が大きくなりすぎてしまい、うまく学習できないこともあります。逆に小さすぎると、学習が進まないこともあります。そのため、適切な初期値を設定することが重要です。よく使われる初期化の方法として、ランダムに小さな値を割り当てる方法などがあります。
正規化と重みの初期化は、どちらも学習を効率的に進めるために欠かせない前処理です。データの正規化によって入力データの範囲を調整し、重みの初期化によって適切な初期値を設定することで、モデルはスムーズに学習を進めることができ、精度の向上につながります。これらの技術は、画像認識や自然言語処理など、様々な分野で広く活用されています。
| 前処理 | 内容 | 効果 | 問題点(対処なし) | 例 |
|---|---|---|---|---|
| データの正規化 | 入力データの範囲を調整する。 | それぞれのデータの特徴が平等に学習される。 | 範囲の広いデータの影響が大きくなりすぎて、範囲の狭いデータの特徴がうまく学習できない。 | すべてのデータを0から1の範囲に揃える。 |
| 重みの初期化 | 学習開始時にモデルの重みに適切な初期値を設定する。 | モデルはスムーズに学習を進めることができ、精度の向上につながる。 |
|
ランダムに小さな値を割り当てる。 |
まとめ

学習を始めるにあたって、機械学習の仕組みでは、データの調整と、重みの初期設定がとても大切です。これは、まるで、料理をする前に材料をきちんと揃え、鍋やフライパンを温めておくようなものです。
まず、データの調整について説明します。これは、正規化と呼ばれ、様々な種類のデータを同じスケールに変換する作業です。例えば、野菜の大きさを揃えるように、データの範囲を調整することで、学習の効率が良くなります。正規化には、最大値と最小値を使って調整する方法や、平均と標準偏差を使って調整する方法など、いくつか種類があります。どの方法を選ぶかは、扱うデータの性質によって変わってきます。例えば、野菜炒めを作る場合は、野菜を同じくらいの大きさに切るのが良いでしょう。しかし、煮物を作る場合は、野菜の種類によって大きさを変えることもあります。このように、データの性質に合わせて正規化の方法を選ぶことが大切です。
次に、重みの初期設定について説明します。重みとは、機械学習のモデルが学習するパラメータのことです。適切な初期値を設定することで、モデルが早く、そして正確に学習できるようになります。これは、料理を始める前に、鍋を適切な温度に温めておくようなものです。重みの初期値の設定方法にもいくつか種類があります。例えば、小さな乱数を使う方法や、特別な計算式を使う方法などがあります。どの方法を選ぶかは、モデルの種類によって異なります。例えば、炒め物を作る場合は、強火で鍋を温めるのが良いでしょう。しかし、煮物を作る場合は、弱火でじっくり温めるのが良いでしょう。このように、モデルの種類に合わせて重みの初期値の設定方法を選ぶことが大切です。
データの正規化と重みの初期設定は、機械学習モデルの学習において、土台となる重要な要素です。適切な方法を選ぶことで、モデルの学習速度と精度が向上し、より良い結果を得ることができます。様々な方法を試し、データやモデルに合った最適な方法を見つけることが、高性能な機械学習モデルを作る鍵となります。
| 項目 | 内容 | 例 |
|---|---|---|
| データの調整(正規化) | 様々な種類のデータを同じスケールに変換する作業。学習の効率向上に貢献。 | 野菜の大きさを揃える。最大値と最小値、平均と標準偏差を使った調整方法など。野菜炒め(同じ大きさ)、煮物(種類によって大きさ調整)。 |
| 重みの初期設定 | 機械学習モデルが学習するパラメータの初期値設定。モデルの学習速度と精度向上に貢献。 | 鍋を適切な温度に温めておく。小さな乱数、特別な計算式など。炒め物(強火)、煮物(弱火)。 |