アルゴリズム
アルゴリズム ソフトマックス関数:多クラス分類の要
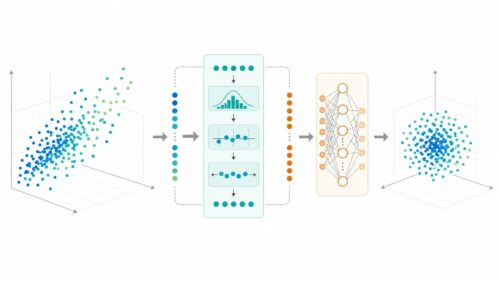
{複数の選択肢から一つを選ぶような問題、例えば写真の判別で被写体が猫か犬か鳥かを当てるような問題では、それぞれの選択肢が選ばれる確率を計算することが大切です。このような問題を多クラス分類問題と呼びます。機械学習では、このような多クラス分類問題を解く際に、ソフトマックス関数というものがよく使われます。
機械学習の予測モデルは、それぞれの選択肢に対して、どれくらい合致しているかを表す数値を出力します。しかし、この数値はそのままでは確率として扱うことができません。なぜなら、これらの数値は合計が1になるとは限らないし、負の値になる可能性もあるからです。そこで、ソフトマックス関数の出番です。
ソフトマックス関数は、これらの数値を受け取り、合計が1になるように変換してくれます。変換後の数値は、それぞれの選択肢が選ばれる確率として解釈することができます。それぞれの数値は0から1の間の値になり、全部の値を合計すると1になります。
具体的な仕組みとしては、まず各数値を指数関数に入れます。指数関数を使うことで、負の値も正の値に変換することができます。そして、すべての数値の指数関数の値を合計し、それぞれの数値の指数関数の値をこの合計値で割ります。このようにして、全体の割合を表すように変換されます。このことから、ソフトマックス関数は正規化指数関数とも呼ばれています。
このように、ソフトマックス関数は、多クラス分類問題において、モデルの出力値を確率として解釈できるように変換する重要な役割を担っています。それぞれの選択肢に対する確率が分かれば、最も確率の高い選択肢を選ぶことで、最終的な予測結果を得ることができます。