過学習を防ぐDropOutとは?意味・仕組み・使い方をわかりやすく解説

AIの初心者
「Drop Out」って、一部の情報をわざと使わない学習方法なんですよね。情報を減らすのに、どうして過学習を防げるんですか?

AI専門家
良い質問ですね。DropOutは、学習中だけ一部のノードを休ませることで、モデルが特定の特徴や経路に頼りすぎるのを防ぎます。毎回少し違う条件で練習させるので、未知のデータにも対応しやすくなるのです。
AIの初心者
なるほど。毎回違う条件で学習するから、一つの手がかりだけを丸暗記しにくくなるんですね。でも、休ませたノードの情報は失われないんですか?
AI専門家
学習中は一部を使わない回がありますが、推論時には基本的に全体を使います。学習の過程で多くの経路が役割を分担するため、全体としてはより頑健なモデルになりやすいのです。
DropOutとは。
DropOut(ドロップアウト)は、ニューラルネットワークの学習中に一部のノードをランダムに無効化する正則化手法です。
目的は、訓練データへの丸暗記に近い過学習を抑え、未知のデータでも安定して判断できるモデルを作ることです。
学習中は毎回異なるノードが休むため、モデルは特定のノードや特徴だけに頼れなくなります。
一方、学習が終わった後の推論では、通常すべてのノードを使って予測します。
この性質により、DropOutは複数の小さなネットワークを組み合わせたような効果を、比較的少ない追加コストで得られる手法として使われています。
はじめに
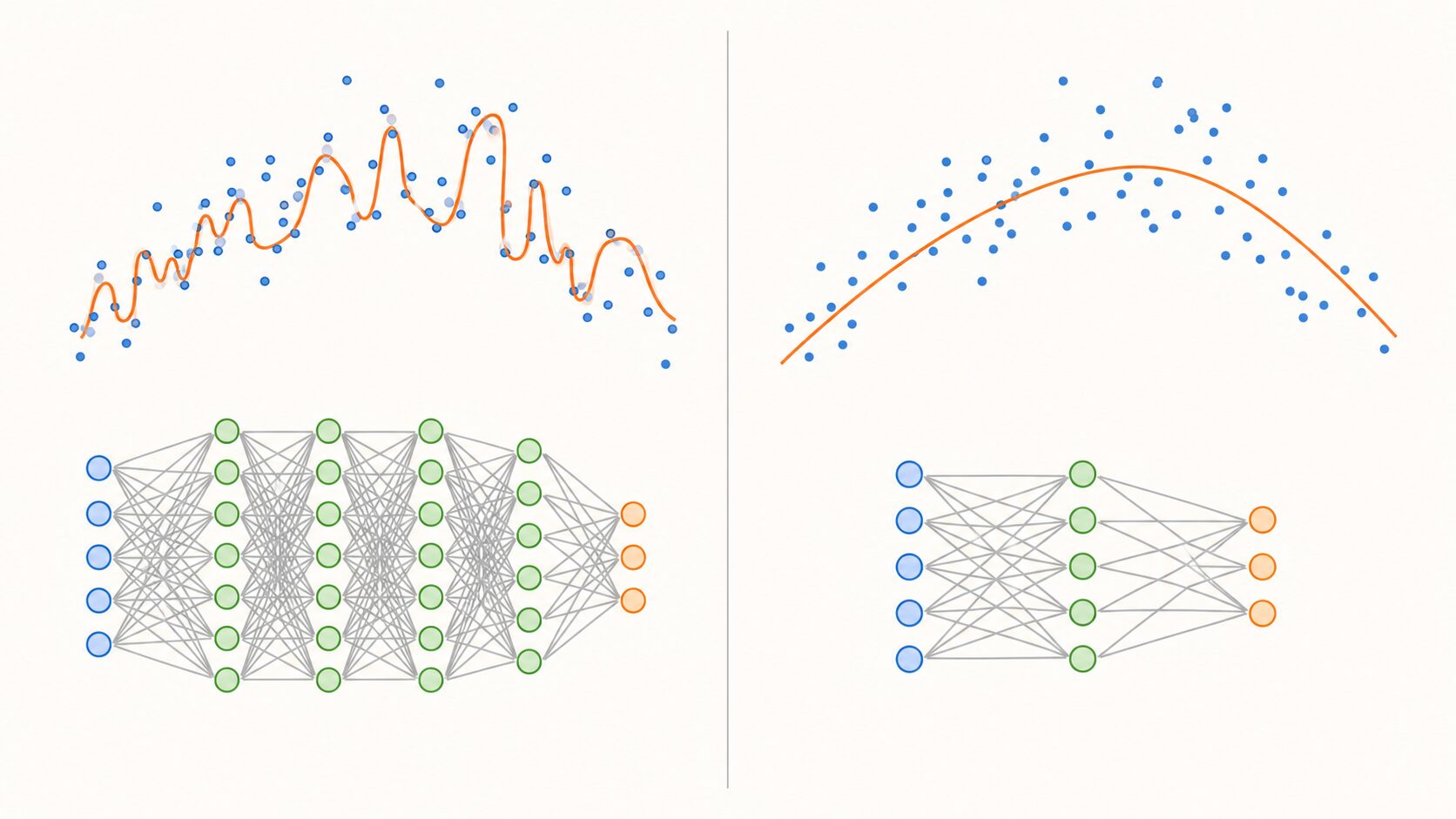
深層学習は、画像認識、自然言語処理、音声認識、推薦システムなど、さまざまなAI分野で使われています。多くのデータから複雑な特徴を学べる一方で、モデルが大きくなるほど訓練データに合わせすぎる過学習が起きやすくなります。
過学習とは、学習に使ったデータでは高い精度を出すのに、新しいデータでは性能が落ちる状態です。たとえば、問題集の答えを丸暗記しただけでは、少し形を変えた応用問題に弱くなります。機械学習モデルでも同じように、訓練データの細かなノイズや偶然の特徴まで覚えてしまうと、実際の利用場面で予測が不安定になります。
DropOutは、この過学習を防ぐための代表的な方法です。学習中にニューラルネットワークの一部をあえて使えない状態にすることで、モデルが特定のノードに依存しすぎないようにします。情報を減らすというより、毎回少し違う条件で学習させる訓練方法と捉えると理解しやすいでしょう。
| 項目 | 内容 |
|---|---|
| 課題 | 訓練データには強いが、新しいデータに弱くなる過学習 |
| 対策 | 学習中に一部のノードをランダムに無効化するDropOut |
| 期待できる効果 | 特定の特徴への依存を減らし、汎化性能を高める |
DropOutとは
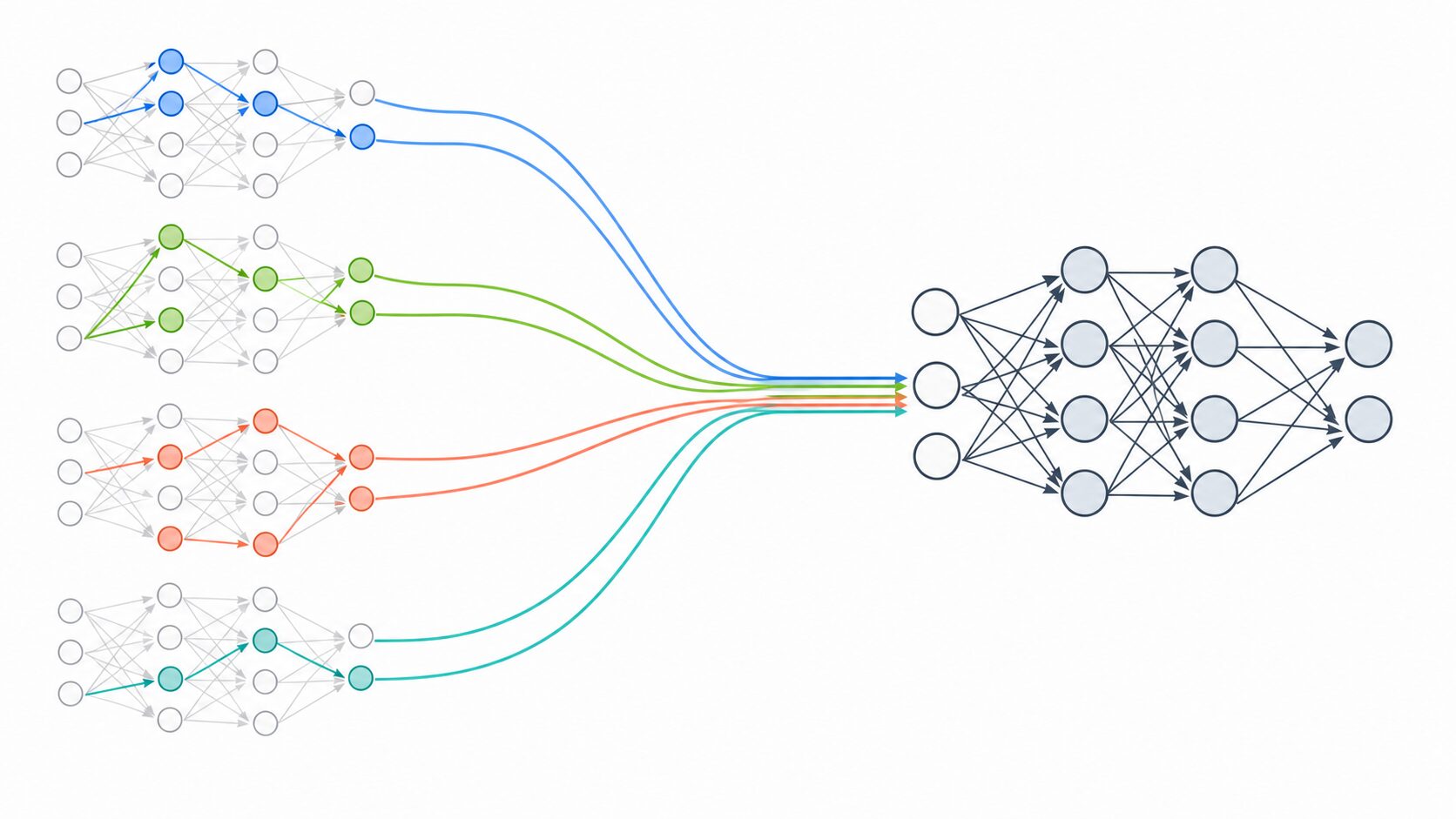
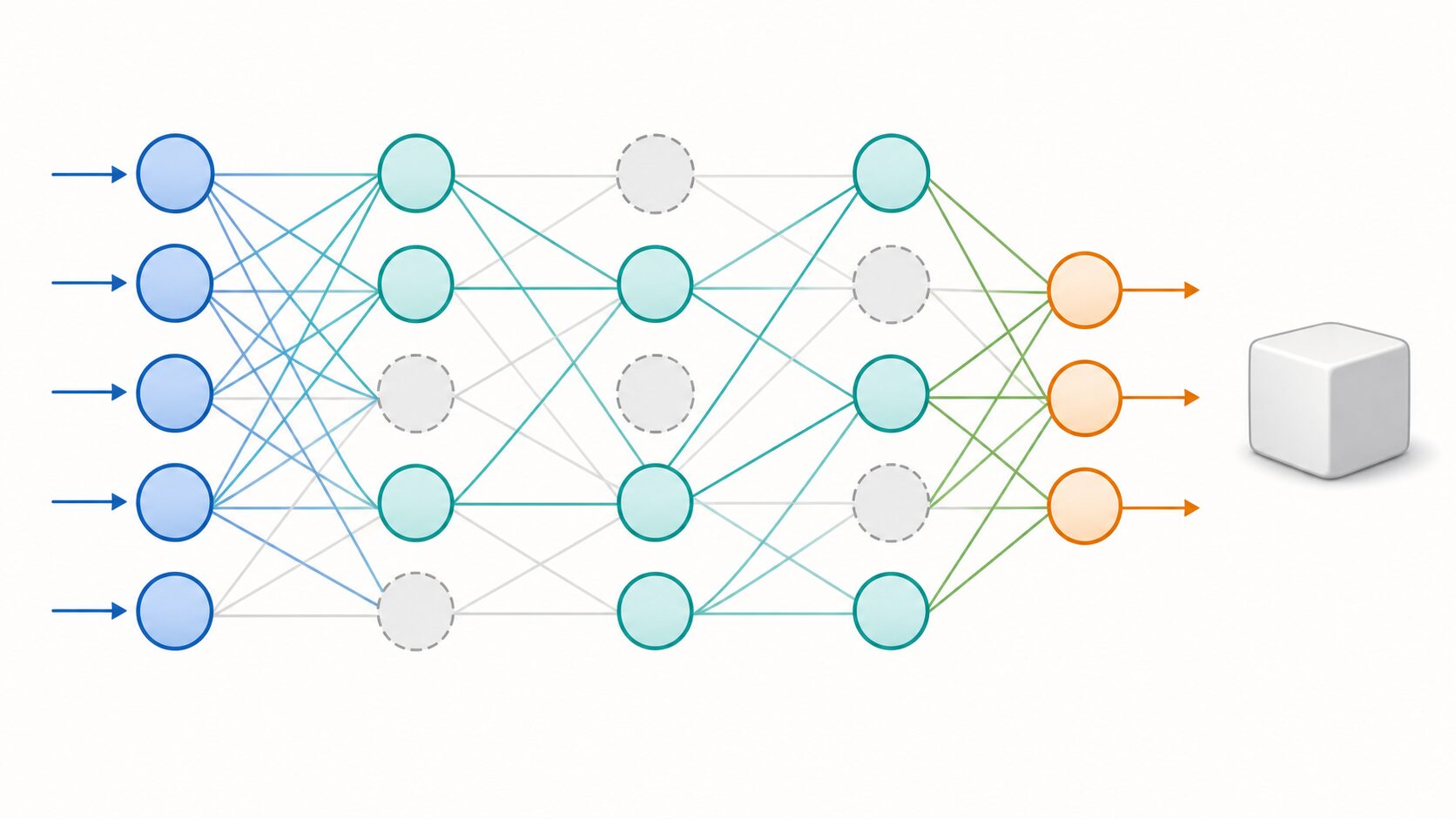
DropOut(ドロップアウト)とは、ニューラルネットワークの学習中に、隠れ層などの一部のノードを一定の確率で一時的に無効化する手法です。無効化されたノードは、その学習ステップでは出力を次の層へ渡しません。
ここで重要なのは、ノードを永久に削除するわけではない点です。あるミニバッチでは休んだノードも、次のミニバッチでは使われることがあります。つまり、DropOutはネットワークの構造を固定的に小さくする方法ではなく、学習のたびに異なる部分ネットワークを使う方法です。
この仕組みによって、モデルは「このノードさえ見れば正解できる」という学習をしにくくなります。複数のノードや特徴を組み合わせて判断する必要があるため、データの一部が欠けたり、少し形が変わったりしても、予測が崩れにくくなります。
DropOutが過学習を防ぐ理由
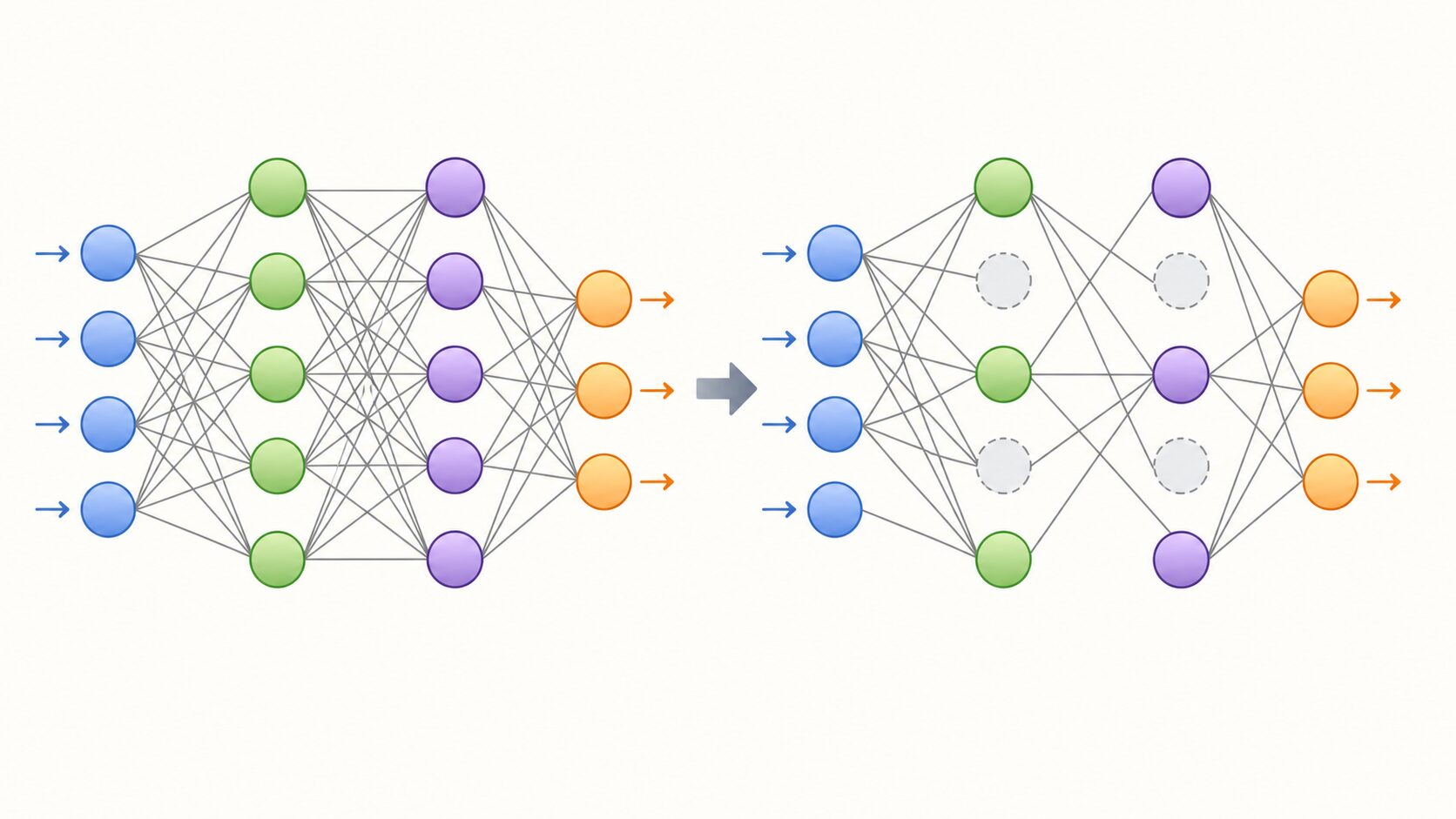
ニューラルネットワークは、多くのパラメータを持つほど複雑な関係を表現できます。しかし、表現力が高いことは、訓練データに含まれる偶然の偏りやノイズまで覚えられることも意味します。これが過学習の原因になります。
DropOutを使うと、学習中に一部のノードがランダムに使えなくなります。そのため、モデルは特定のノードや結合に強く依存できません。結果として、複数の特徴を組み合わせて判断するようになり、訓練データだけに最適化された脆いパターンを覚えにくくなります。
これは、学習中のモデルに適度なノイズを加える正則化と考えることもできます。写真の一部が少し隠れていても対象を認識できるように、モデルも一部の情報が使えない状況に慣れることで、未知データへの対応力を高めやすくなります。
DropOutの仕組み
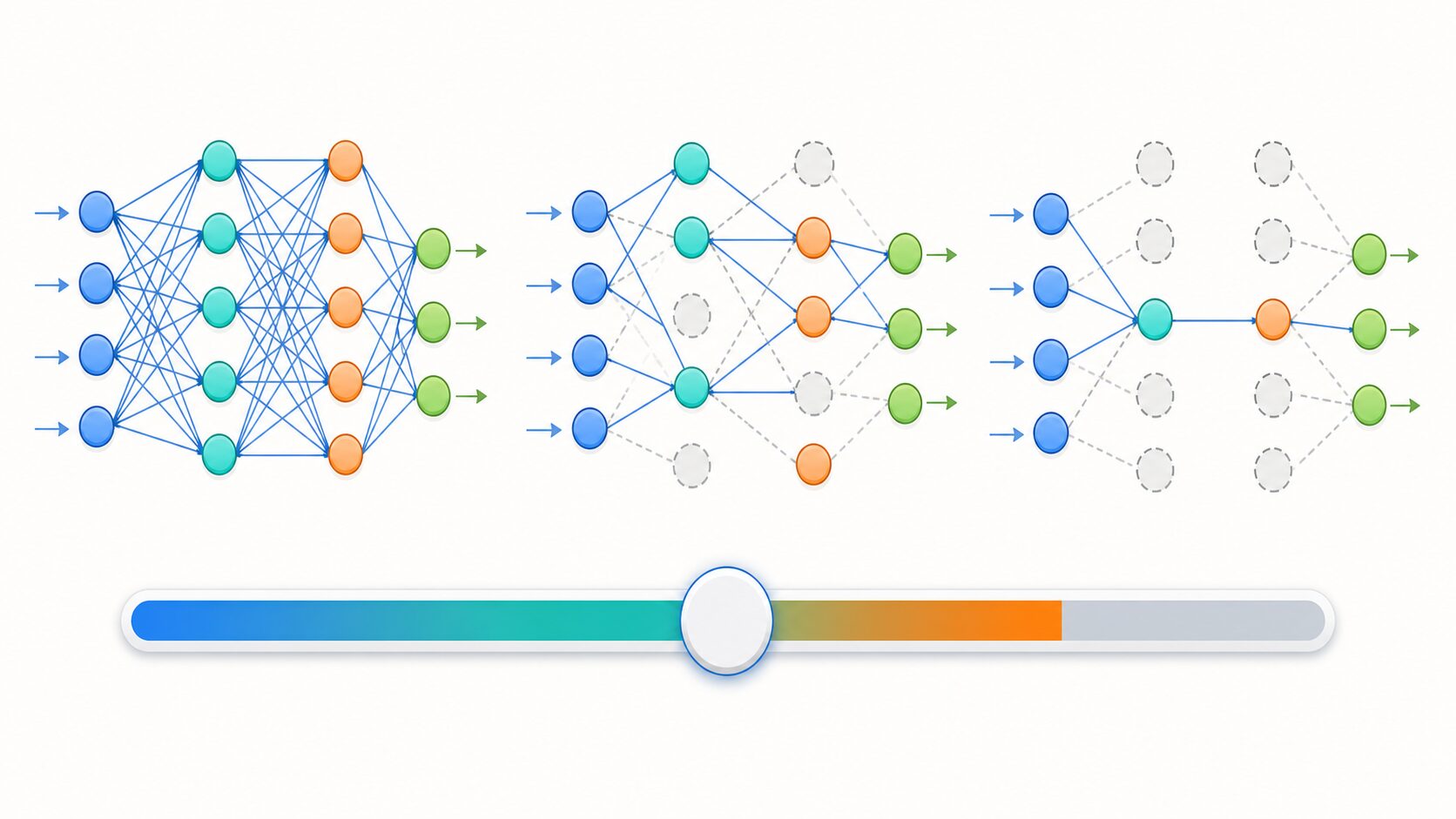
DropOutでは、あらかじめ設定したドロップアウト率に従って、各ノードを残すか休ませるかをランダムに決めます。たとえばドロップアウト率を0.5にすると、対象となる層のノードのうち、おおよそ半分がその学習ステップで無効化されます。
学習中の流れは、まず入力データをネットワークへ入れ、対象層のノードを確率的に無効化します。次に、残ったノードだけで順伝播と誤差計算を行い、逆伝播で重みを更新します。次のデータでは、別のノードの組み合わせが使われるため、モデルは毎回少し違う構造で学習することになります。
推論時、つまり実際に予測するときは、通常すべてのノードを使います。ただし、学習中に一部のノードを落としていた分、出力の大きさが変わらないように調整が必要です。現在の多くの実装では、学習時に出力をあらかじめスケーリングする inverted dropout が使われるため、推論時に特別な処理を意識しなくてよい場合が多いです。
| 段階 | DropOutの動き |
|---|---|
| 学習時 | 一部のノードをランダムに無効化し、残った経路で重みを更新する |
| 推論時 | 基本的にすべてのノードを使って予測する |
| 調整 | 学習時または推論時に出力のスケールをそろえる |
DropOutの効果
DropOutの主な効果は、過学習の抑制と汎化性能の向上です。ランダムにノードを休ませることで、モデルは一部の経路だけに頼らず、複数の特徴を使って判断するようになります。これにより、訓練データにはない入力にも安定して対応しやすくなります。
もう一つの見方として、DropOutは多数の小さなネットワークを学習して、それらの結果をまとめる疑似アンサンブルのような働きをします。本当に多数のモデルを個別に学習させると計算コストが大きくなりますが、DropOutなら一つのネットワークの中で、毎回異なる部分ネットワークを使うことで近い効果を狙えます。
また、ノイズに対する耐性を高める効果もあります。入力や中間特徴の一部が不完全でも判断できるように学ぶため、画像の一部が隠れている場合や、文章データに余計な表現が混ざる場合などにも、より頑健な特徴を学習しやすくなります。
DropOutの適用範囲
DropOutは、全結合層でよく使われます。全結合層は多くのパラメータを持ちやすく、訓練データに合わせ込みやすいため、DropOutによる正則化の効果が出やすい領域です。
畳み込みニューラルネットワークでもDropOutは使われますが、画像の局所的な特徴を扱う畳み込み層では、通常のDropOutよりも空間方向をまとめて落とす方法が使われることもあります。どの方法がよいかは、モデル構造、データ量、タスクの性質によって変わります。
一方で、出力層には通常DropOutを使いません。出力層は最終的な分類確率や予測値を出す場所であり、ここをランダムに無効化すると、学習したい目的そのものが不安定になるためです。DropOutは主に、特徴を学習する途中の層に使うと考えると整理しやすくなります。
| 場所 | 使い方の目安 |
|---|---|
| 全結合層 | 過学習対策として使われることが多い |
| 畳み込み層 | タスクにより通常のDropOutや派生手法を検討する |
| 出力層 | 最終予測が不安定になるため通常は使わない |
ドロップアウト率の決め方と注意点
ドロップアウト率は、無効化するノードの割合です。率を0.5にすると、対象層のノードの半分程度を学習ステップごとに休ませます。全結合層では0.5前後が例としてよく挙げられますが、これは必ず最適という意味ではありません。
ドロップアウト率が高すぎると、学習に使える情報が少なくなりすぎて、モデルが十分に特徴を覚えられないことがあります。この状態は、過学習を防ぐ以前に学習不足を招く可能性があります。逆に低すぎると、正則化の効果が弱く、特定のノードへの依存を十分に抑えられない場合があります。
実務や学習では、訓練データの損失だけでなく、検証データの精度や損失を見ながら調整します。データ拡張、重み減衰、早期終了、バッチ正規化など、ほかの正則化手法と併用する場合は、DropOutを強くしすぎない方がよいこともあります。検証データで性能を確認しながら決めることが大切です。
DropOutと関連手法の違い
DropOutは正則化手法の一つですが、過学習対策はこれだけではありません。重み減衰は重みが大きくなりすぎることを抑える方法で、データ拡張は訓練データを変形してデータのバリエーションを増やす方法です。早期終了は、検証データの性能が悪化し始めた段階で学習を止める方法です。
これらはいずれも過学習を抑える目的を持ちますが、働き方は異なります。DropOutはネットワーク内部の一部をランダムに使えなくすることで、特徴の依存関係を分散させます。重み減衰はパラメータの大きさを抑え、データ拡張は入力データ側の多様性を増やします。組み合わせることで効果が高まる場合もありますが、過度に使うと学習が進みにくくなるため、検証結果を見ながら調整する必要があります。
まとめ
DropOutは、深層学習モデルの過学習を防ぐために使われる代表的な正則化手法です。学習中に一部のノードをランダムに無効化し、特定の特徴や経路への依存を減らすことで、未知のデータにも対応しやすいモデルを目指します。
ポイントは、DropOutが情報を単純に捨てる方法ではなく、学習中だけ一部を使えない状況を作る方法だということです。推論時には通常すべてのノードを使い、学習中に得た分散した特徴表現をもとに予測します。
使う場所は全結合層が代表的で、出力層には通常使いません。ドロップアウト率はデータやモデルによって最適値が変わるため、訓練データだけでなく検証データの結果を見ながら調整します。過学習、正則化、汎化性能を学ぶうえで、DropOutは必ず押さえておきたい基本概念です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年6月4日 | 学習時と推論時の違い、率の調整観点を追記 |