Bag-of-Wordsとは?単語の袋で文章を数値化する基本手法

AIの初心者
「袋の中の単語」って、文章をどう扱う考え方なんですか?本当に単語を袋に入れるようなものですか?

AI専門家
イメージとしては近いよ。文章を単語の集まりとして見て、どの単語が何回出てきたかを数える方法なんだ。例えば「今日はいい天気です。明日は雨です。」という文章で考えてみよう。
AIの初心者
単語ごとに分けて数える、ということですね。
AI専門家
その通り。「今日」「いい」「天気」「明日」「雨」のような単語を袋に入れて数える。ただし、単語の順番は見ないから、並び順が変わっても同じ単語が同じ回数出ていれば似た文章として扱われるんだ。
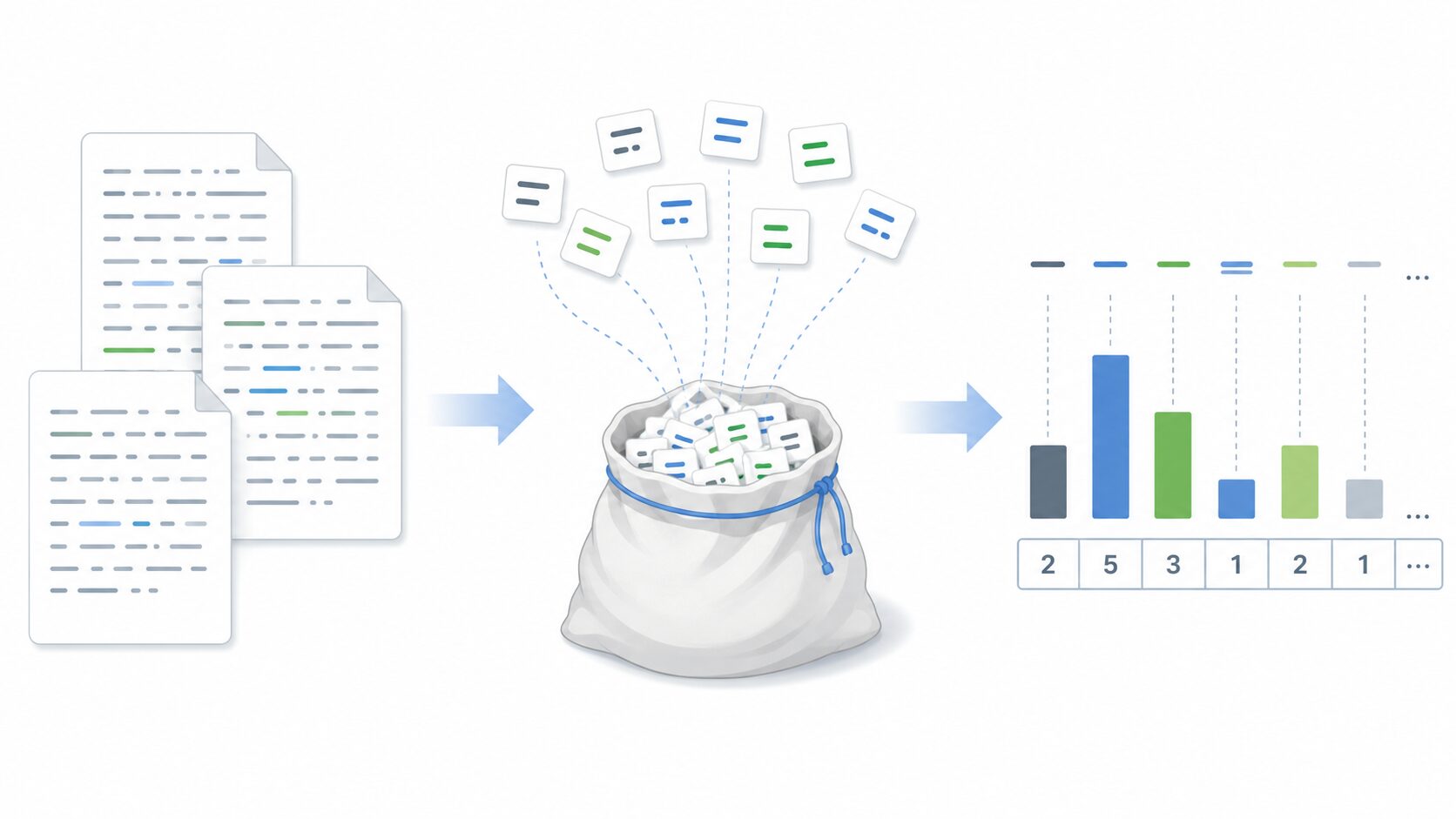
Bag-of-Wordsは、日本語では「単語の袋」と訳されることが多い、自然言語処理の基本的なテキスト表現手法です。文章をそのままコンピュータに渡すのではなく、文章中に出てくる単語の種類と回数を数え、数値データとして扱える形に変換します。
この考え方はとても単純ですが、文章検索、文章分類、迷惑メール判定など、多くの処理の土台になります。一方で、単語の順序や文脈を捨てるため、意味の細かな違いを扱いにくいという限界もあります。
Bag-of-Wordsとは何か
Bag-of-Wordsとは、文章を「どの単語が、何回出てきたか」という情報だけで表す方法です。袋の中に単語を入れていくように、単語の順番は気にせず、出現した単語と回数だけを数えます。
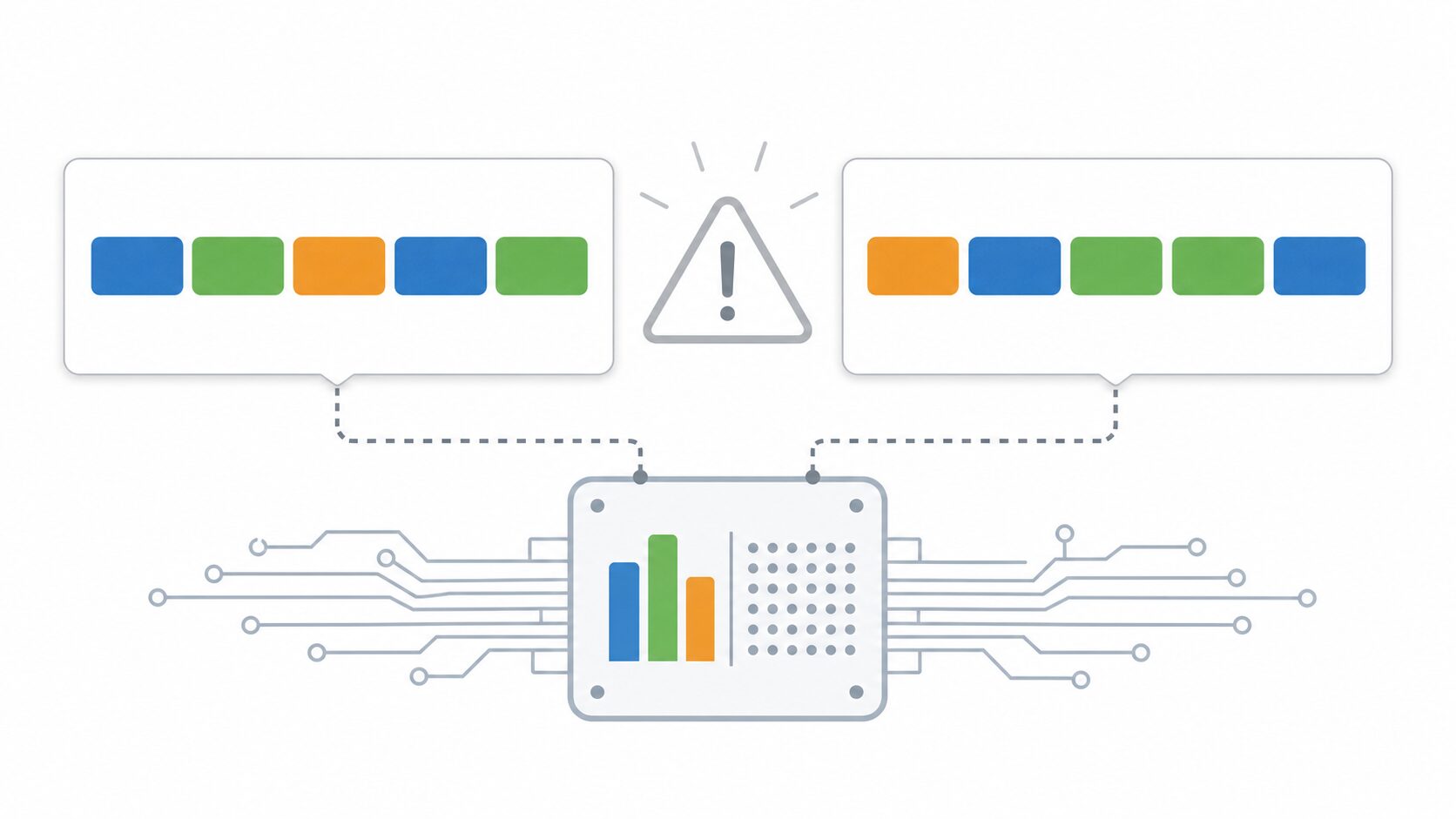
例えば「青い空、広い海」と「青い海、広い空」という2つの文を考えます。どちらにも「青い」「空」「広い」「海」が1回ずつ含まれています。語順は違いますが、Bag-of-Wordsでは同じ単語構成の文章として扱われます。
このように、Bag-of-Wordsは文章の意味を深く理解する方法ではありません。文章を機械学習で扱うために、まず単語の出現パターンへ置き換える方法だと考えると理解しやすくなります。
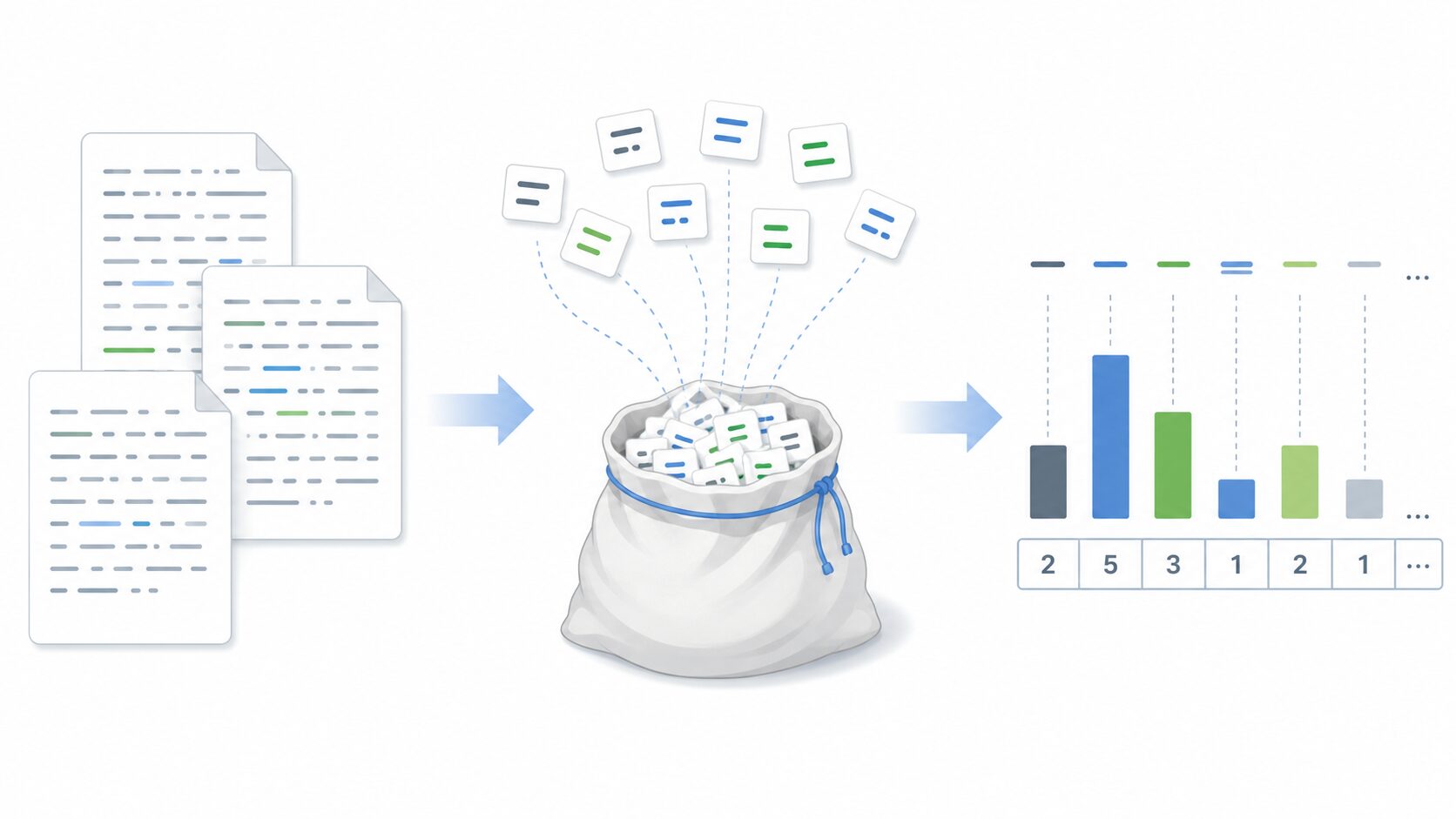
Bag-of-Wordsの仕組み
Bag-of-Wordsで文章を数値化するときは、主に次の流れで処理します。
- 分析したい文章を単語に分ける
- 対象文書全体に登場する単語の一覧を作る
- 各文章について、それぞれの単語が何回出たかを数える
- 出現回数を並べたベクトルとして表す
この単語一覧は「語彙」と呼ばれます。語彙に含まれる単語の順番を固定しておけば、どの文章も同じ長さの数値列で表せます。機械学習モデルは文字列そのものよりも数値データを扱いやすいため、この変換が重要になります。
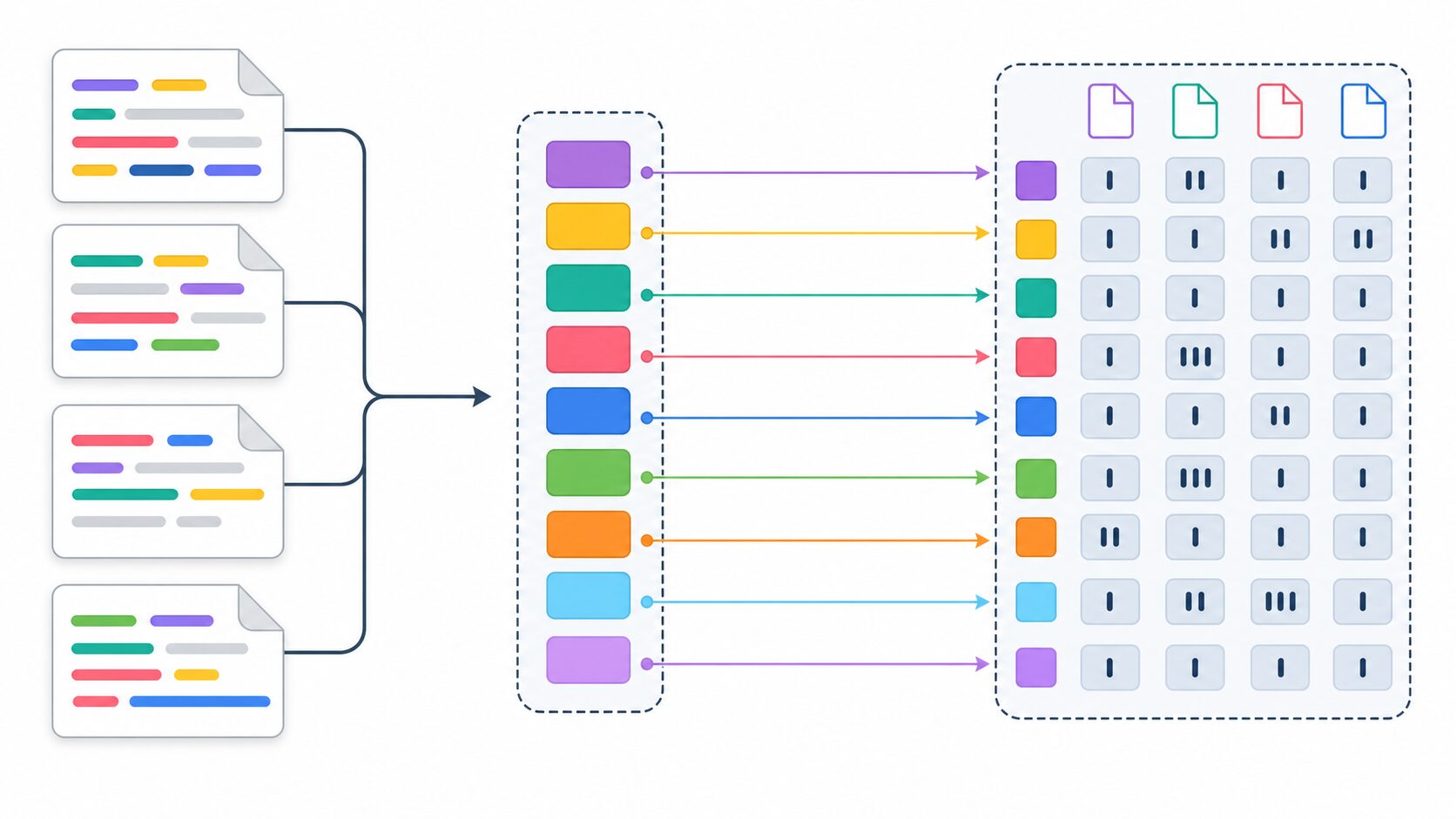
Bag-of-Wordsで文章をベクトル化する例
語彙が「りんご」「みかん」「ぶどう」の3語だとします。ある文章に「りんご」が2回、「みかん」が1回出て、「ぶどう」が出てこなかった場合、その文章は「2、1、0」という数値列で表せます。
| 語彙 | りんご | みかん | ぶどう |
|---|---|---|---|
| 出現回数 | 2 | 1 | 0 |
この数値列が、文章の特徴を表すベクトルです。文章同士を比較するときは、このベクトルの近さを調べます。似た単語が似た回数で出ている文章ほど、近い文章として扱いやすくなります。
日本語では、英語のように単語の間に空白がないため、形態素解析などで単語に分ける前処理が必要になります。また、「は」「が」「です」のように頻繁に出る語をどう扱うかも、分析結果に影響します。
Bag-of-Wordsのメリット
Bag-of-Wordsの大きなメリットは、仕組みが単純で、計算が軽いことです。文章を単語の出現回数へ置き換えるだけなので、実装しやすく、大量の文書にも比較的速く適用できます。
また、どの単語が分類や検索に効いているのかを確認しやすい点も利点です。例えば、スポーツ記事には「試合」「選手」「得点」などの語が多く、経済記事には「市場」「企業」「金利」などの語が多い、といった傾向を読み取りやすくなります。
高度な言語モデルを使う前の基礎実験や、処理速度を重視する場面では、今でも有効な選択肢です。特に、文章の細かな語順よりも、含まれるキーワードの傾向が重要なタスクと相性がよい手法です。
Bag-of-Wordsの欠点と注意点
Bag-of-Wordsは単語の順番を無視するため、語順によって意味が変わる文章を区別できません。例えば「私は犬が好きです」と「犬は私が好きです」は、使われている単語がほぼ同じでも意味は異なります。しかし、Bag-of-Wordsでは非常に似た文章として扱われます。
皮肉や反語も苦手です。「この映画、最高につまらないね」という文では、「最高」という肯定的に見える単語だけを見て、文章全体の否定的なニュアンスを見落とす可能性があります。
さらに、「少し嬉しい」と「とても嬉しい」のような程度の違いも扱いにくい場合があります。単語の出現回数だけでは、修飾語の働きや文脈上の意味を十分に反映できないためです。
| 注意点 | 例 | 起こりやすい問題 |
|---|---|---|
| 語順を無視する | 私は犬が好きです / 犬は私が好きです | 意味の違いを区別しにくい |
| 文脈を読めない | 最高につまらない | 皮肉や反語を誤解しやすい |
| 頻出語に影響される | これ、する、です | 文章の特徴でない語が目立つ |
Bag-of-Wordsの主な活用例
Bag-of-Wordsは、文章の特徴を手軽に数値化したい場面で使われます。代表的な用途は、迷惑メール判定、文章検索、ニュース記事の分類、問い合わせ内容の分類などです。
迷惑メール判定では、「無料」「当選」「今すぐ」など、迷惑メールに多く現れやすい単語の出現傾向が手がかりになります。文章検索では、検索語と文書に共通する単語が多いほど関連度が高いと判断できます。
文章分類では、カテゴリごとによく出る単語の傾向を利用します。スポーツ、経済、政治などの記事を分類する場合、それぞれのカテゴリに特徴的な単語がどれだけ含まれるかを見れば、大まかな分類が可能です。
TF-IDF、n-gram、単語埋め込みとの違い
Bag-of-Wordsの弱点を補うために、関連する手法がよく使われます。特に、TF-IDF、n-gram、単語埋め込みは、Bag-of-Wordsと一緒に理解しておきたい重要な考え方です。
| 手法 | 何を見るか | 補える点 |
|---|---|---|
| Bag-of-Words | 単語の出現回数 | 文章を簡単に数値化できる |
| TF-IDF | 単語の出現頻度と珍しさ | どの文書にも出る一般語の影響を下げられる |
| n-gram | 連続する複数語の並び | 語順の情報を一部取り込める |
| 単語埋め込み | 単語の意味的な近さ | 似た意味の単語を近い表現として扱える |
TF-IDFは、「その文章にはよく出るが、他の文章にはあまり出ない単語」を重視します。n-gramは「太郎が」「花子を」のように連続する語のまとまりを数えるため、語順の情報を少し取り込めます。単語埋め込みは、単語を多次元の数値で表し、意味の近さを扱う方法です。
Bag-of-Wordsを学ぶときのポイント
Bag-of-Wordsを学ぶときは、「単純だから古い」と片づけるのではなく、文章を数値化する最初の考え方として理解することが大切です。現在の高度な自然言語処理でも、テキストを数値表現に変換するという基本は変わりません。
実務や学習では、前処理の影響も意識しましょう。単語の分け方、表記ゆれの統一、不要語の除去、頻出語への重み付けによって、同じBag-of-Wordsでも結果が変わります。
一方で、文脈理解や意味理解が重要なタスクでは、Bag-of-Wordsだけでは限界があります。目的が文章分類なのか、意味検索なのか、感情分析なのかによって、TF-IDF、n-gram、単語埋め込み、言語モデルなどを使い分ける必要があります。
まとめ
Bag-of-Wordsは、文章を単語の種類と出現回数で表す、自然言語処理の基本的な手法です。単語の順番を無視するため仕組みは単純ですが、文章を数値データに変換できるため、検索、分類、迷惑メール判定などで役立ちます。
ただし、語順、文脈、皮肉、修飾語のニュアンスを扱うのは苦手です。そのため、Bag-of-Wordsの長所と限界を理解したうえで、TF-IDF、n-gram、単語埋め込みなどの関連手法と組み合わせて考えることが重要です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年6月11日 | ベクトル化の手順、限界、関連手法の比較を補強 |