 アルゴリズム
アルゴリズム MLOpsとは?機械学習モデルを継続運用する仕組みと導入手順
MLOpsとは?機械学習モデルを継続運用する仕組みと導入手順 AIの初心者 MLOpsとは何ですか?機械学習の勉強をしていると出てきますが、モデルを作る話なのか、システム運用の話なのか分かりません。 AI専門家 MLOpsは、機械学習モデル...
記事数:(449)
アルゴリズム  アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム 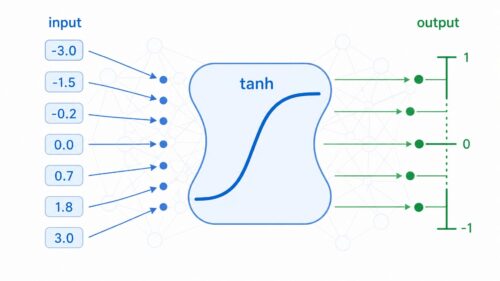 アルゴリズム
アルゴリズム 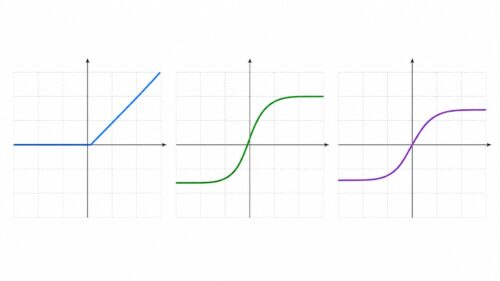 アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム 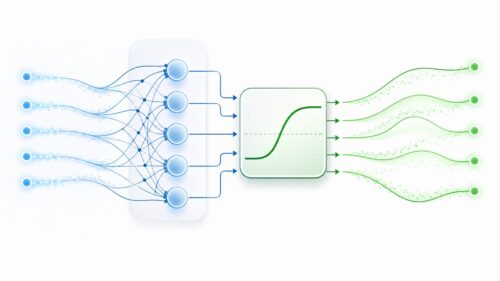 アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム  アルゴリズム
アルゴリズム