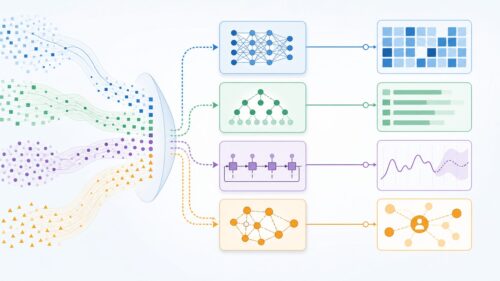
アルゴリズム
アルゴリズム 交差検証:機械学習の精度を高める手法
機械学習は、まるで人間のようにコンピュータに学習させる技術です。学習のためには多くのデータが必要です。しかし、集めたデータ全てを学習に使うと、新しいデータに対する予測精度、いわゆる汎化性能を測ることができません。そこで、交差検証という手法が用いられます。
交差検証は、限られた量のデータを有効に活用して、モデルの汎化性能を評価する統計的手法です。具体的には、集めたデータをいくつかのグループに分けます。そして、あるグループを学習用データ、残りのグループを検証用データとして扱います。まず、学習用データを使って機械学習モデルを学習させます。次に、学習済みモデルに検証用データを入力し、予測精度を評価します。
この手順を、検証用データとして使うグループを変えながら繰り返します。例えば、データを5つのグループに分けるとすると、それぞれのグループが1回ずつ検証用データとなります。それぞれの検証における予測精度を平均することで、モデルの全体的な予測性能を評価できます。
交差検証は、モデルの過学習を防ぎ、未知のデータに対する予測性能をより正確に見積もるために役立ちます。過学習とは、学習用データに特化しすぎてしまい、新しいデータに対する予測精度が低下する現象です。交差検証によって、過学習の度合いを確認し、モデルの調整を行うことができます。
このように、交差検証は機械学習モデルの信頼性を高める上で重要な役割を果たしています。交差検証によって得られた汎化性能は、モデルが実際に運用された際の性能を予測する上で重要な指標となるのです。