ReLU関数とは?意味・仕組み・活用例をわかりやすく解説

AIの初心者
「ReLU関数」って難しそうでよくわからないんですけど、簡単に教えてもらえますか?

AI専門家
そうだな。ReLU関数は、入力された値が0より小さければ0を返し、0以上ならその値をそのまま返す関数だよ。例えば、入力に-3を入れれば0が出てきて、5を入れれば5が出てくるんだ。
AIの初心者
なるほど。でも、なんでそんな関数を使うんですか?
AI専門家
AIの学習を効率よく進めるためなんだ。ReLU関数は計算が簡単で、深いニューラルネットワークでも学習が進みやすい場合が多いんだよ。
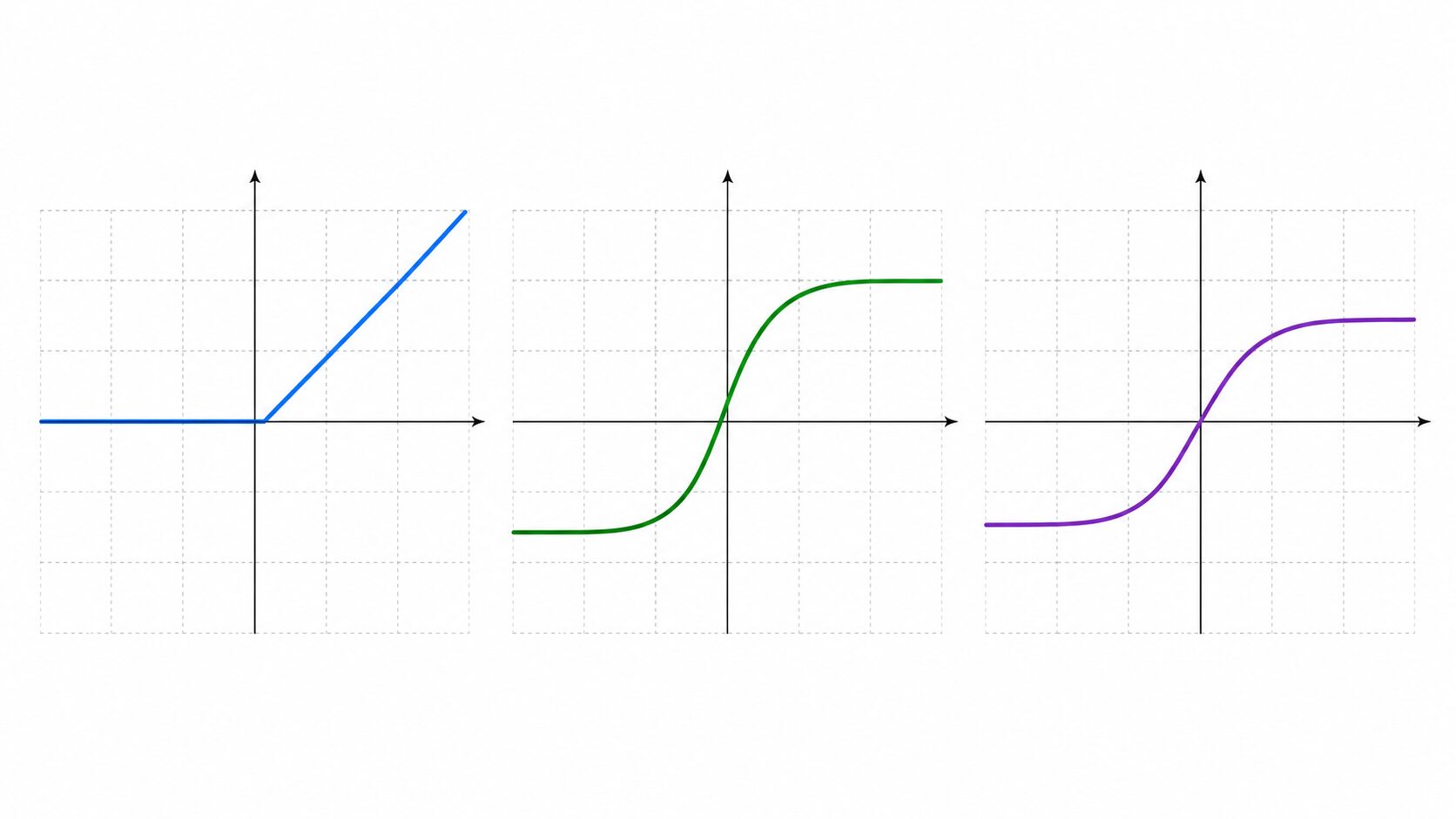
ReLU関数とは
ReLU関数とは、深層学習でよく使われる活性化関数の一つです。正式には「Rectified Linear Unit」と呼ばれ、日本語では「修正線形ユニット」と訳されます。ランプ関数と説明されることもあります。
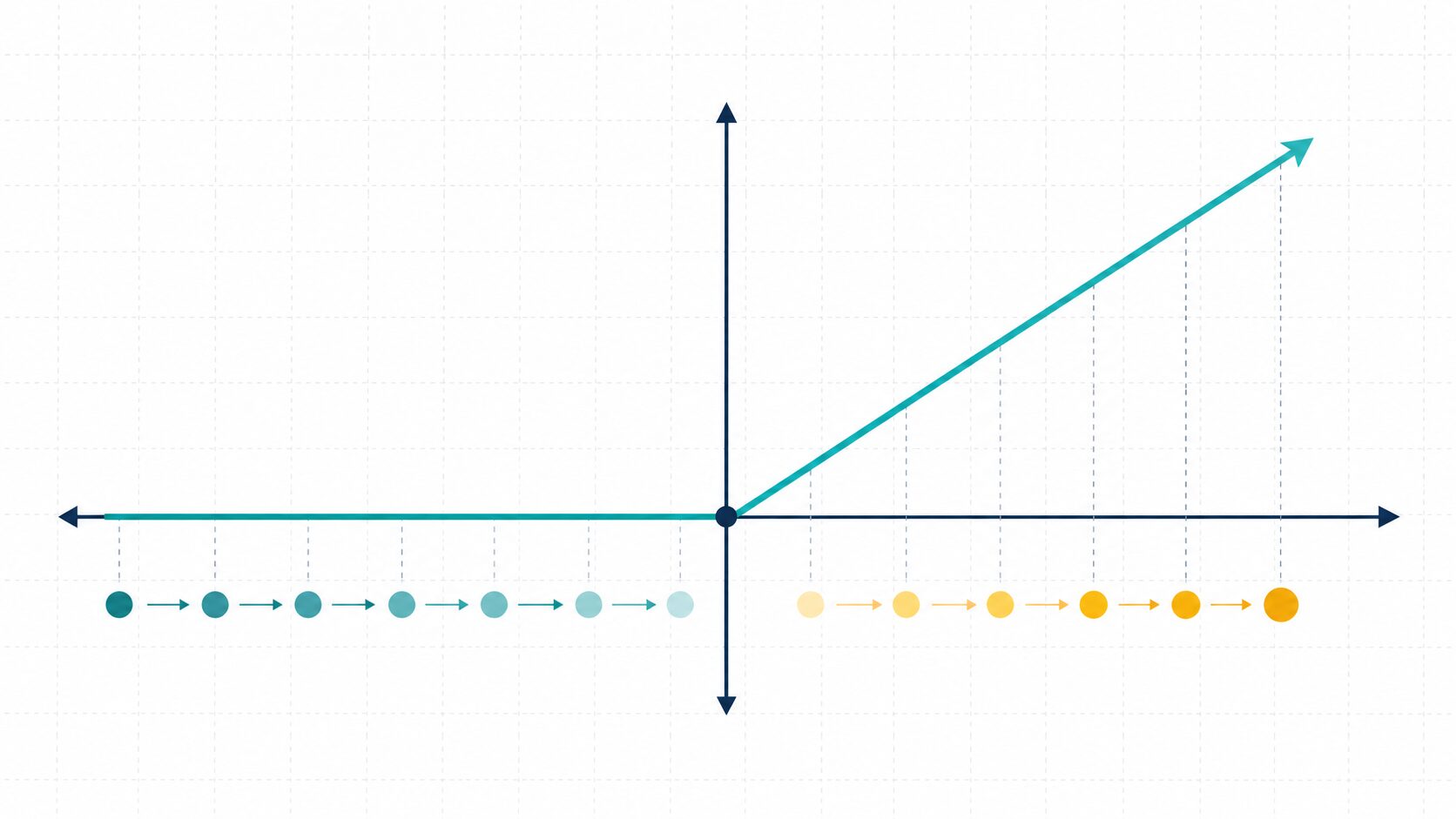
仕組みはとても単純です。入力値が0以下なら0を出力し、入力値が0より大きければ、その値をそのまま出力します。数式で書くと、一般に f(x) = max(0, x) と表されます。
例えば、入力が-3なら出力は0、入力が0なら出力は0、入力が5なら出力は5です。負の値を切り捨て、正の値だけを通す関数だと考えると理解しやすいでしょう。
活性化関数の中でのReLU関数の役割
ニューラルネットワークでは、各層が入力を受け取り、重みを掛けて合計し、その結果を次の層へ渡します。このとき、単なる足し算と掛け算だけでは、どれだけ層を重ねても表現できる関係が限られてしまいます。
そこで使われるのが活性化関数です。活性化関数は、ニューラルネットワークに非線形な変化を加え、画像、音声、文章のような複雑なパターンを学習しやすくします。
ReLU関数は、この活性化関数の中でも特にシンプルで計算しやすいため、多くの深層学習モデルで標準的に使われてきました。
ReLU関数の仕組み
ReLU関数のグラフは、0を境に形が変わります。0より左側、つまり入力が負の範囲では出力はずっと0です。一方、0より右側では入力値と出力値が同じになるため、右上がりの直線になります。

この形は、負の値を止めて、正の値だけをそのまま通すゲートのように見ることができます。ニューラルネットワークの中では、ある特徴が強く現れたときだけ信号を次へ進める働きとして理解できます。
ただし、入力がちょうど0の点ではグラフが折れ曲がるため、数学的には滑らかではありません。実装上は、この点の勾配を0、1、または便宜的な値として扱うことがあります。
ReLU関数がよく使われる理由
ReLU関数の大きな利点は、計算が軽いことです。シグモイド関数のように指数計算を使う関数と比べると、ReLU関数は「0より大きいか」を判定するだけで済みます。
深層学習では、膨大なデータと多数のパラメータを使って何度も計算を繰り返します。そのため、1回あたりの計算が少し軽くなるだけでも、学習時間全体に大きな差が出ます。
もう一つの利点は、勾配消失問題を抑えやすいことです。勾配消失問題とは、層が深くなるほど学習に必要な信号が小さくなり、前の層までうまく届かなくなる問題です。
ReLU関数は、入力が正の範囲では勾配が1になります。そのため、シグモイド関数やtanh関数のように勾配が極端に小さくなりにくく、深いネットワークでも学習を進めやすいという特徴があります。
ReLU関数の課題
ReLU関数には便利な点が多い一方で、弱点もあります。代表的なのがDying ReLU問題です。
Dying ReLU問題とは、一部のニューロンが学習中に常に0を出力するようになり、ほとんど学習に貢献しなくなる現象です。大きな負の値が入り続けると、そのニューロンは出力も勾配も0になり、更新されにくくなります。
この問題を避けるために、負の入力に対してもわずかな傾きを残すLeaky ReLUや、傾き自体を学習で調整するParametric ReLUなどの改良版が使われることがあります。
他の活性化関数との比較
ReLU関数を理解するには、他の代表的な活性化関数と比べるとわかりやすくなります。よく比較されるのは、シグモイド関数とtanh関数です。
| 関数 | 主な特徴 | 注意点 |
|---|---|---|
| ReLU関数 | 入力が正ならそのまま出力し、負なら0を出力する。計算が軽く、深いネットワークで使いやすい。 | Dying ReLU問題が起きることがある。 |
| シグモイド関数 | 出力が0から1の範囲に収まるため、確率のような値を表しやすい。 | 入力が大きすぎる、または小さすぎると勾配が小さくなりやすい。 |
| tanh関数 | 出力が-1から1の範囲に収まり、0を中心にした値を扱える。 | シグモイド関数と同じく、深い層では勾配消失が問題になることがある。 |
画像認識などの深いニューラルネットワークではReLU関数がよく使われます。一方で、出力を確率として扱いたい場合や、モデルの構造によってはシグモイド関数やtanh関数が適している場合もあります。
ReLU関数を使うときの考え方
ReLU関数は、深層学習において非常に有力な選択肢です。特に、隠れ層の活性化関数として使うと、計算効率と学習の進みやすさの両方を得やすくなります。
ただし、どんな場面でも必ず最適とは限りません。学習が不安定になる場合や、出力が0に偏る場合は、Leaky ReLU、Parametric ReLU、ELUなどの改良版を試す価値があります。
大切なのは、ReLU関数を「深層学習でよく使われる定番」として覚えるだけでなく、なぜ使いやすいのか、どのような弱点があるのかを合わせて理解することです。
まとめ
ReLU関数は、入力が0以下なら0、正ならその値をそのまま返す活性化関数です。仕組みは単純ですが、計算が軽く、深いニューラルネットワークでも学習を進めやすいため、深層学習の発展を支えてきました。
一方で、Dying ReLU問題のように、ニューロンが働かなくなる課題もあります。そのため、実際のモデル構築では、シグモイド関数、tanh関数、Leaky ReLUなどと比較しながら、タスクや構造に合った活性化関数を選ぶことが重要です。
ReLU関数は、深層学習を学ぶうえで最初に押さえておきたい基本的な活性化関数です。定義、利点、課題をセットで理解しておくと、ニューラルネットワークの仕組みをより見通しやすくなります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月2日 | 初回公開 |
| 2026年4月28日 | ReLU関数の定義、活性化関数としての役割、利点、Dying ReLU問題、他の活性化関数との比較を初心者向けに再構成 |