DeepLabとは?高精度な画像セグメンテーションをわかりやすく解説

AIの初心者
「DeepLab」って、画像の何を見分ける技術なんですか?

AI専門家
DeepLabは、画像の中の各ピクセルが何を表しているかを分類する技術だよ。人、車、道路、空のような領域を細かく色分けできるんだ。
AIの初心者
人が写っていたら、顔や腕などの部位まで全部わかるんですか?
AI専門家
基本的には「人」という領域を見つける技術で、誰なのか、体のどの部位なのかを細かく分ける技術とは別なんだ。入力画像のサイズ調整が必要になる場合もあるよ。
DeepLabとは。
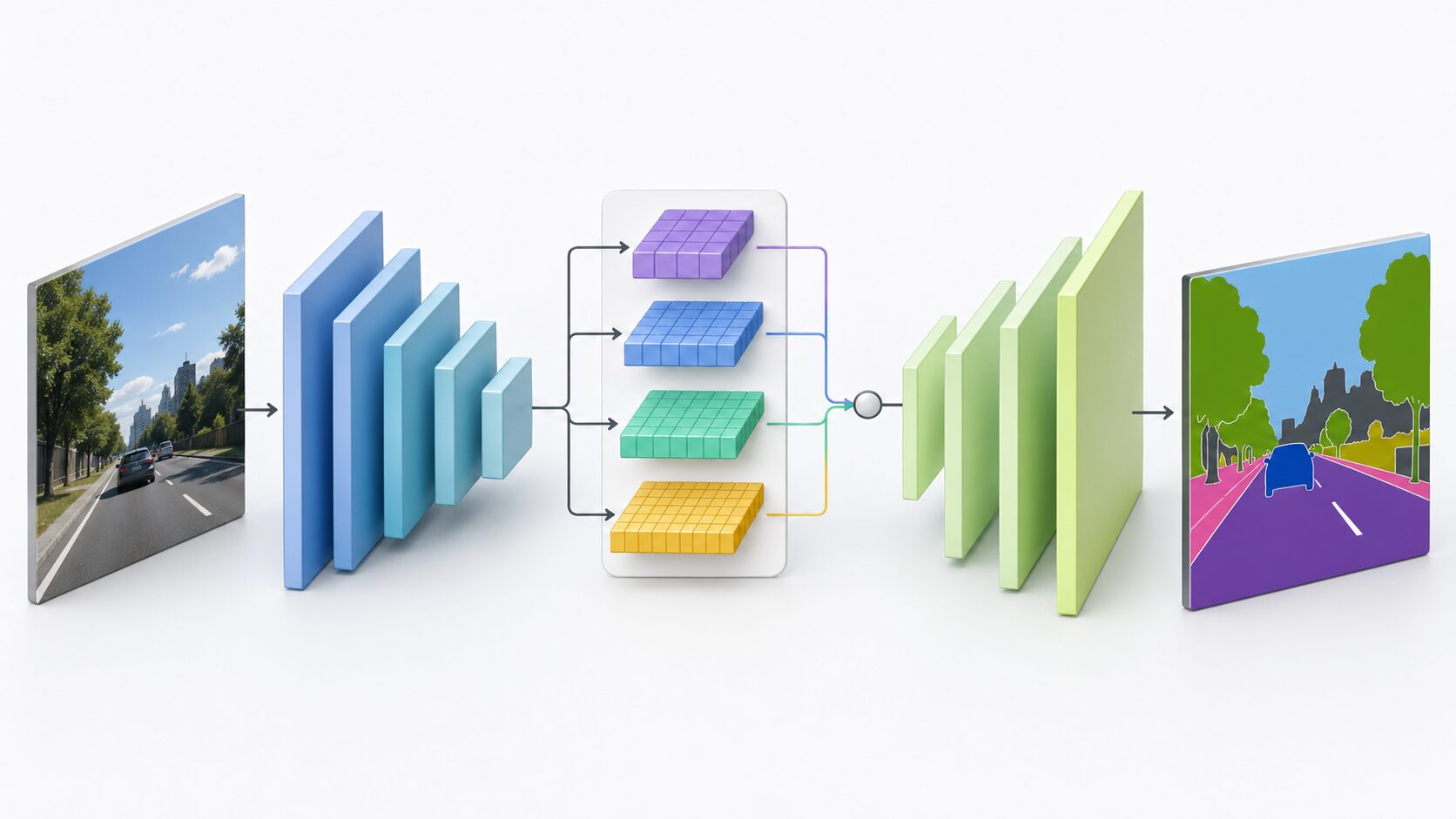
DeepLabは、画像の中の領域をピクセル単位で分類する意味的セグメンテーションの代表的な手法です。写真に写る人、車、道路、空、建物などをクラスごとに分け、どの部分が何を表しているかを色分けしたマスクとして出力します。高精度な画像認識、自動運転、医療画像解析、ロボットの環境理解などで使われる重要な技術です。
DeepLabとは
DeepLabは、ディープラーニングを使って画像を細かい領域に分ける画像セグメンテーション手法です。一般的な画像分類が「この写真には犬が写っている」と判断するのに対し、DeepLabは「このピクセルは犬、このピクセルは背景、このピクセルは道路」というように、画像内の位置ごとに意味を割り当てます。
このような処理は、semantic segmentation、日本語では意味的セグメンテーションと呼ばれます。物体の有無だけでなく、輪郭に沿って領域を分けられるため、場面を細かく理解したい用途に向いています。
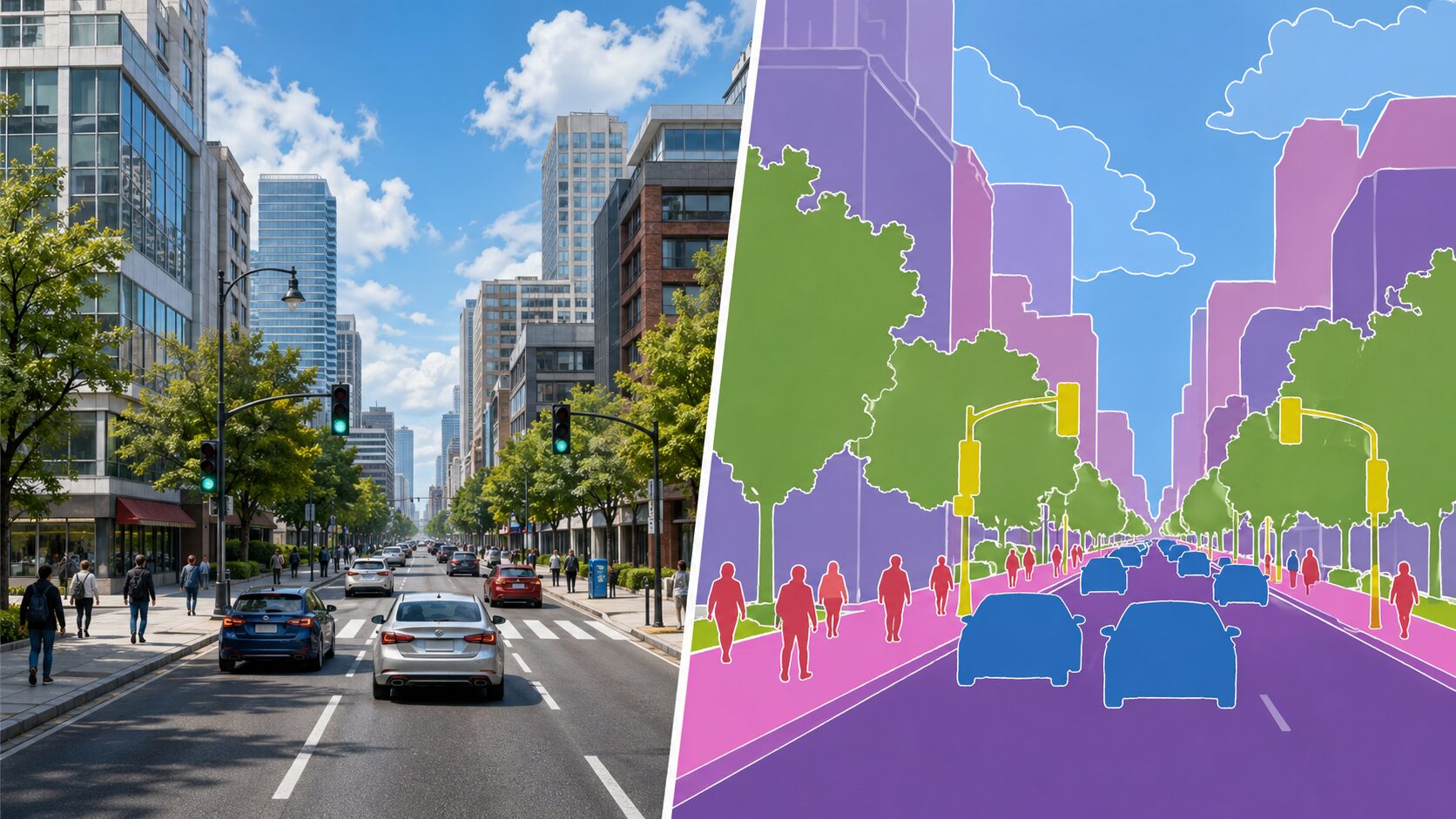
例えば、街中の写真を入力すると、空、建物、道路、木、歩行者、車などを別々の領域として塗り分けられます。単に物体を四角い枠で囲む物体検出よりも、対象物の形に近い情報を得られる点が特徴です。
意味的セグメンテーションで何ができるのか
DeepLabが得意とするのは、画像内の各ピクセルをあらかじめ決められたクラスに分類することです。人、馬、車、犬、猫など、学習済みモデルが対応しているクラスであれば、対象が画像のどの範囲にあるかを細かく推定できます。
ただし、意味的セグメンテーションは「同じ種類のもの」を同じクラスとして扱います。複数の人が写っている場合、DeepLabはそれらを「人」の領域として認識できますが、1人目と2人目を別々の個体として識別するとは限りません。個体ごとに分けたい場合は、インスタンスセグメンテーションのような別の考え方が必要になります。
また、人の頭、腕、足のような部位を細かく分ける処理も、通常のDeepLabの目的とは異なります。DeepLabは「これは人の領域である」と判断する技術であり、「人の中のどの部位か」を常に分類する技術ではありません。この違いを理解しておくと、用途に合った手法を選びやすくなります。
DeepLabの基本構造
DeepLabの処理は、大きく見ると特徴を取り出す部分と、ピクセル単位の分類結果に戻す部分に分けられます。元記事ではこれを符号化と復号の流れとして説明しています。
まず、符号化に相当する部分では、入力画像から重要な特徴を抽出します。画像の細かい模様、輪郭、色の変化、物体の形などを段階的に読み取り、ニューラルネットワーク内部で扱いやすい特徴表現に変換します。これにより、画像全体の文脈と局所的な形の両方を利用できるようになります。
次に、復号に相当する部分では、抽出した特徴をもとに元の画像に近い解像度へ戻しながら、各ピクセルのクラスを推定します。最終的には、画像と同じような縦横サイズの分類マップが作られ、道路、空、人物、車などの領域が色分けされます。
DeepLabの強みは、単純に画像を小さくして分類するだけではなく、複数のスケールの情報を活用して対象物の輪郭を捉えようとする点にあります。大きな建物や道路のような広い領域だけでなく、信号機や標識のような小さな対象も扱いやすくするための工夫が取り入れられています。

DeepLabが識別できる対象と活用例
DeepLabは、学習に使ったデータセットに含まれるクラスを識別します。元記事では、人間、自転車、自動車、犬、猫、馬など、代表的な21種類の対象を例に挙げています。これは、どのモデルを使うか、どのデータで学習したかによって変わります。
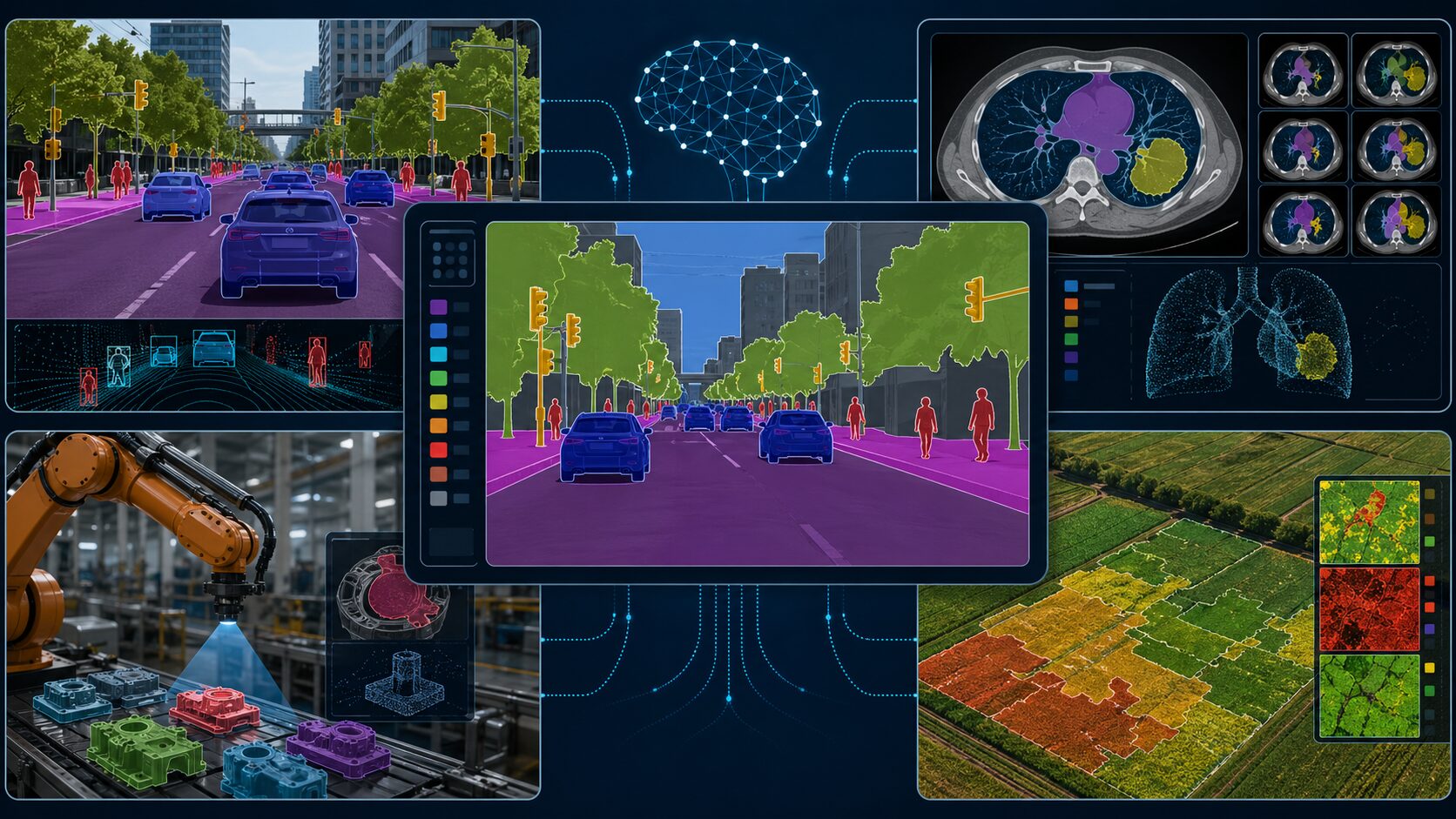
活用例としてわかりやすいのが自動運転です。車載カメラの映像から、道路、歩行者、車両、自転車、標識などを分けることで、周囲の状況理解に役立ちます。物体の位置だけでなく、道路や歩道の領域を把握できる点は、走行判断の補助に重要です。
医療分野では、CT画像やレントゲン画像、顕微鏡画像などから、臓器や病変らしい領域を切り出す用途が考えられます。医師の診断を置き換えるものではありませんが、確認すべき場所を示したり、画像解析の作業を効率化したりする支援技術として期待されています。
ロボット工学では、ロボットが周囲の環境を理解するために使えます。工場で部品や作業台の領域を認識したり、屋外ロボットが地面、障害物、植物などを見分けたりする場面です。農業では作物や雑草の分布を把握し、製造業では製品の欠陥検出や検査工程への応用が考えられます。

| 分野 | DeepLabで期待できること |
|---|---|
| 自動運転 | 道路、歩行者、車、自転車などの領域を把握し、周囲の状況理解を支援する |
| 医療画像 | 臓器や病変候補の領域を抽出し、画像確認や解析作業を補助する |
| ロボット | 作業対象、障害物、床面などを区別し、環境理解に役立てる |
| 農業・製造業 | 作物、雑草、欠陥部分などの領域を見つけ、管理や検査の効率化につなげる |
Pythonで扱われる理由
DeepLabの実装や実験では、Pythonがよく使われます。Pythonは機械学習や画像処理のライブラリが豊富で、データの読み込み、前処理、モデルの学習、推論結果の可視化までを一つの流れで扱いやすいからです。
実際には、PythonだけでDeepLabが動くわけではありません。TensorFlowやPyTorchのような深層学習フレームワーク、画像処理ライブラリ、GPU環境、学習済みモデル、データセットなどを組み合わせて利用します。初心者は「Pythonで書かれている」という説明を、実装環境全体の入り口として理解するとよいでしょう。
既存の学習済みモデルを使えば、自分で大量の画像を集めて一から学習しなくても、サンプル画像に対してセグメンテーション結果を試せます。一方で、特定の業務や研究テーマに使う場合は、対象分野に合ったデータで再学習や微調整を行う必要があります。
DeepLabの制限事項
DeepLabは高性能な画像セグメンテーション手法ですが、万能ではありません。まず、基本的な意味的セグメンテーションでは、同じクラスの複数物体を個別に区別することは苦手です。複数の人が写っている場合、すべてを「人」の領域としてまとめて扱うことがあります。
次に、部位識別にも注意が必要です。人を人として見つけられても、頭、腕、脚を別々のクラスとして出力するには、そのような部位ラベルで学習されたモデルが必要です。通常のDeepLabを使えば何でも細かく分解できる、というわけではありません。
入力画像の大きさにも実務上の制約があります。モデルによっては、一定のサイズにリサイズしてから入力する必要があります。リサイズによって細かい対象が潰れたり、縦横比の扱いを誤って形が歪んだりすると、精度に影響する可能性があります。
さらに、自動運転やロボット制御のようにリアルタイム性が求められる場面では、精度だけでなく処理速度も重要です。高精度なモデルほど計算量が増える傾向があるため、用途に応じて速度、メモリ使用量、精度のバランスを考える必要があります。
| 項目 | 注意点 |
|---|---|
| 個体識別 | 同じクラスの複数物体を、個別のIDとして分ける用途には別手法が必要になる |
| 部位識別 | 人の腕や足などを分けるには、部位ラベルに対応した学習データとモデルが必要 |
| 画像サイズ | 入力前のリサイズや前処理が結果に影響することがある |
| 処理速度 | リアルタイム用途では、精度だけでなく推論時間や計算資源も評価する必要がある |
今後の展望
DeepLabのような画像セグメンテーション技術は、今後もさまざまな分野で重要性が高まると考えられます。特に、より細かい領域の識別、異なる画像サイズへの柔軟な対応、リアルタイム処理の高速化は、実用化を進めるうえで大きな課題です。
医療では、より精密な病変領域の抽出や、複数種類の組織の分類が求められます。自動運転では、夜間、雨天、逆光など条件が悪い環境でも安定して認識できることが重要です。ロボットや製造業では、未知の環境や新しい製品にも対応できる汎用性が求められます。
DeepLabを理解するうえで大切なのは、画像を「一枚の写真」として見るのではなく、ピクセルごとに意味を持つ地図として扱う発想です。この考え方を押さえておくと、画像分類、物体検出、インスタンスセグメンテーションなど、関連する画像認識技術との違いも理解しやすくなります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年4月30日 | DeepLabの定義、意味的セグメンテーションの仕組み、活用例、Python実装、制限事項を初心者向けに再構成 |