AWS Bedrock(ベッドロック)とは?
AWS Bedrock(ベッドロック)は、AWS上で複数の基盤モデルを選び、生成AIアプリやAIエージェントを構築・運用するためのフルマネージド型の生成AIプラットフォームです。公式名称はAmazon Bedrockですが、この記事では検索されることの多い表記に合わせて、AWS Bedrock(ベッドロック)と表記します。
基盤モデルとは、大量のデータで学習された汎用AIモデルのことです。AWS Bedrock(ベッドロック)では、文章生成、要約、翻訳、画像生成、検索補助、コード支援、エージェント実行などの機能を、APIやAWSの管理画面から利用できます。

重要なのは、AWS Bedrock(ベッドロック)が単体のチャットAIではない点です。モデルを呼び出すだけでなく、社内データを使うRAG、Knowledge Bases(ナレッジベース)、Agents、AgentCore、AgentCore Runtime、Guardrails、評価、ログ監視などを組み合わせて、企業向けの生成AIアプリを作るための基盤として使います。
ただし、AWS Bedrock(ベッドロック)を使えば何でも自動化できるわけではありません。業務データの整理、アクセス権限、回答品質の評価、コスト管理、運用ルールの設計が必要です。また、利用できるモデルや機能はリージョンによって異なるため、実装前にAWS公式情報を確認しましょう。
AWS Bedrock(ベッドロック)でできること
AWS Bedrock(ベッドロック)では、複数の基盤モデルを1つのサービス上で試し、用途に合わせて選び、アプリケーションへ組み込めます。代表的なモデル提供元には、Amazon Nova、Anthropic Claude、Cohere、Meta Llama、Mistral AI、Stability AI、OpenAI gpt-ossなどがあります。ただし、対応モデル、モデルID、料金、リージョンは変わるため、最新の一覧はAWS公式ドキュメントで確認する必要があります。
主な用途は、チャット、文章生成、要約、翻訳、埋め込み生成、画像生成、マルチモーダル処理、コード支援などです。たとえば、社内FAQチャットボット、顧客問い合わせの一次回答、営業メールや提案書のたたき台作成、議事録要約、製品マニュアル検索、開発者向けコード支援などに活用できます。
実務では、最初から大規模な自動化を目指すよりも、問い合わせ対応や社内文書検索のように効果を測りやすい業務から始めるのが現実的です。モデルの性能だけでなく、回答の根拠、処理速度、コスト、運用担当者の確認フローまで含めて設計することが大切です。
KnowledgeBase/Knowledge Basesとは?RAGで社内データを使う仕組み
「KnowledgeBase」と検索されることもありますが、AWSの機能名としてはAmazon Bedrock Knowledge Basesです。この記事では、Knowledge Bases(ナレッジベース)と表記します。
Knowledge Bases(ナレッジベース)は、RAGをマネージドに実装するための機能です。RAGとは、モデルが学習済みの知識だけで答えるのではなく、社内文書やデータソースから関連情報を検索し、その内容をプロンプトに追加して回答させる仕組みです。つまり、モデルを再学習するのではなく、必要な情報を検索して回答に使わせます。
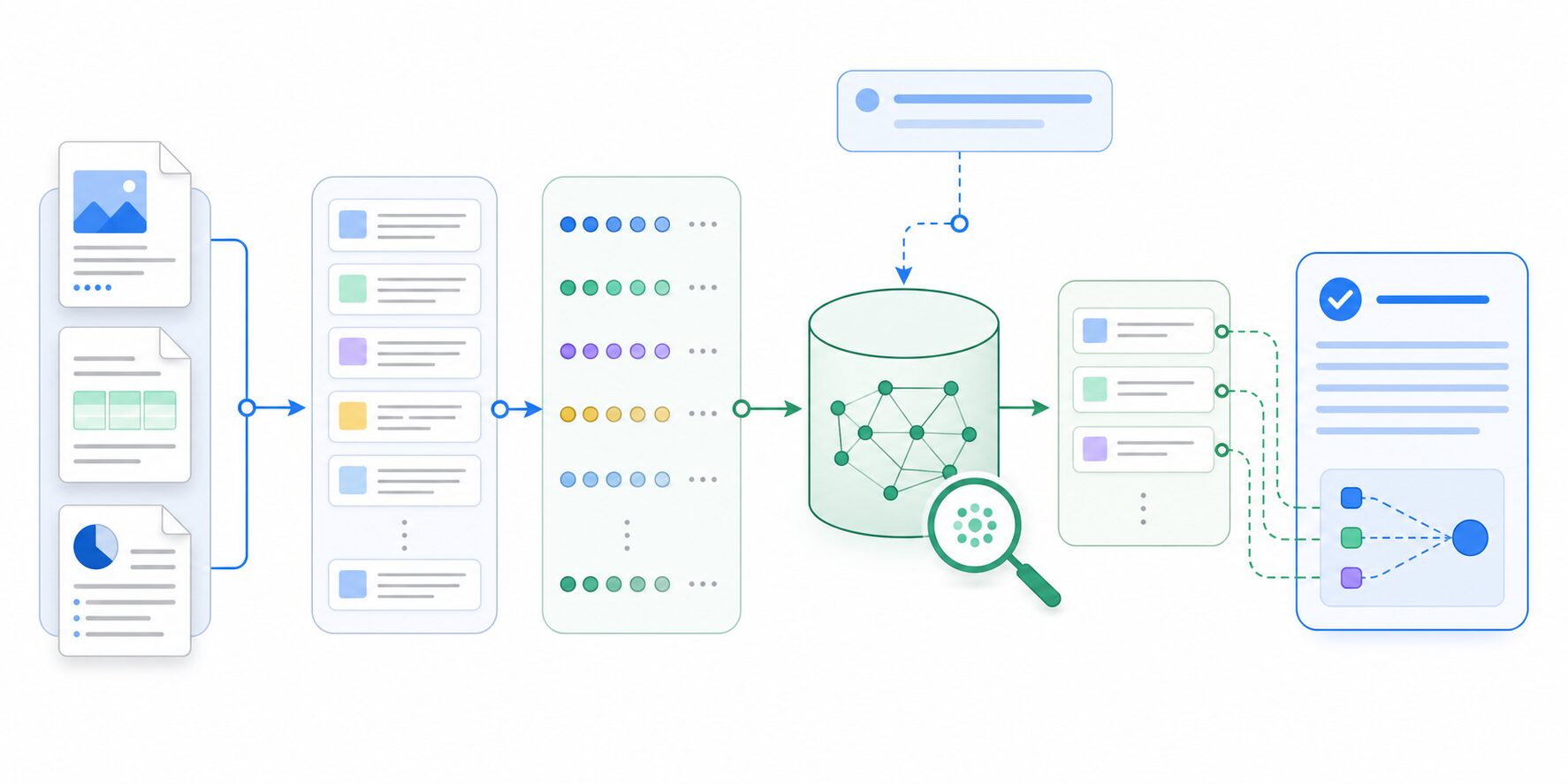
基本的な流れは、まず社内文書やデータソースを取り込み、文書を小さな単位に分け、埋め込みと呼ばれる検索用の数値表現に変換します。その後、ベクトルインデックスに保存し、ユーザーから質問が来たときに関連する情報を検索します。検索された情報をモデルに渡すことで、社内データに基づいた回答を生成できます。
Knowledge Bases(ナレッジベース)では、根拠となる引用の提示、データソースの同期、画像を含むマルチモーダル検索、構造化データへの問い合わせ、検索結果のリランキングなども活用できます。Agentsと組み合わせれば、エージェントがKnowledge Bases(ナレッジベース)を参照しながら、業務タスクを進めることもできます。
たとえば、人事規程PDFを参照して回答する社内チャットボット、製品仕様書や障害対応手順を参照するサポートAI、営業資料や過去提案書をもとに提案書の下書きを作る支援ツールなどに向いています。
注意点として、元データが古い、矛盾している、権限管理が不十分といった状態では、回答品質や情報漏えいリスクに影響します。RAGは便利ですが、データ品質とアクセス権限の設計が回答品質を大きく左右する点を押さえておきましょう。
AgentsとAgentCoreの違い
AWS Bedrock(ベッドロック)を理解するときに混同しやすいのが、AgentsとAgentCoreです。
Amazon Bedrock Agentsは、基盤モデル、Knowledge Bases(ナレッジベース)、API、業務システム、ユーザーとの会話を組み合わせて、タスクを実行するエージェントを作る機能です。ユーザーの依頼を解釈し、必要な情報を聞き返し、Knowledge Bases(ナレッジベース)を参照し、APIやアクショングループを呼び出して処理を進めます。
一方、AgentCoreは、AIエージェントを安全に構築、デプロイ、運用するためのエージェント基盤です。Bedrock内外のモデルやフレームワークと組み合わせて使える点が特徴です。AgentCoreには、Runtime、Memory、Gateway、Identity、Code Interpreter、Browser、Observability、Evaluations、Policy、Registryなどのサービスがあります。
たとえば、「顧客からの問い合わせを分類し、マニュアルを参照し、CRMに対応履歴を登録する」ような処理では、Agentsで会話とタスク実行を設計し、AgentCoreで実行環境、認証、ツール連携、監視、評価を整える、と考えると分かりやすいです。
チャットボットは主に会話や回答を行いますが、エージェントは外部ツールを呼び出して手順を進めます。そのため、エージェントに与える権限、実行できる操作、確認ステップ、ログ、監査の設計が重要です。
AgentCore Runtimeとは?エージェントを動かす実行環境
AgentCore Runtimeは、AIエージェントやツールを安全にデプロイし、実行するためのサーバーレス実行環境です。Runtimeという名前の通り、モデルそのものではなく、エージェントコードやツールを動かす場所です。
AgentCore Runtimeは、特定のフレームワークやモデルに縛られにくく、LangGraph、LlamaIndex、Strands Agents、CrewAIなどのフレームワークや、Bedrock内外のモデルと組み合わせられます。また、MCPやA2Aといったプロトコルを使い、他のツールやエージェントとの連携にも対応します。
特徴として、セッションごとに分離された実行環境、長時間処理、永続ファイルシステム、認証、観測性、大きなペイロード、双方向ストリーミングなどがあります。長時間かかる調査、複数ステップの業務処理、マルチモーダル処理のように、単純な1回のチャット応答では終わらない用途に向いています。
サーバーレスであっても、権限、ネットワーク、ログ、コスト、タイムアウト、データ保持の設計は必要です。特に本番運用では、エージェントがどのツールを呼び出せるのか、失敗したときにどう止めるのか、誰が結果を確認するのかを明確にしておく必要があります。
セキュリティとガードレール
AWS Bedrock(ベッドロック)を企業で使う場合、セキュリティ、プライバシー、責任あるAIの設計は欠かせません。Guardrailsは、ユーザー入力とモデル応答の両方を評価し、リスクを下げるための仕組みです。

Guardrailsでは、コンテンツフィルター、禁止トピック、機密情報フィルター、単語フィルター、画像コンテンツフィルターなどを組み合わせられます。また、AgentsやKnowledge Bases(ナレッジベース)にも適用できます。
たとえば、個人情報を含む入力や回答を制御する、社外秘情報を回答に出さないよう権限を設計する、禁止トピックや不適切表現を抑制する、といった使い方があります。加えて、IAM、KMS、ログ、監査、データアクセス権限、リージョン選定も重要です。
ただし、Guardrailsはリスクを下げる仕組みであり、完全な保証ではありません。本番利用では、人間の確認、評価データ、ログ監視、運用ルールをセットで設計しましょう。
AWS Bedrock(ベッドロック)のメリット
AWS Bedrock(ベッドロック)の大きなメリットは、複数の基盤モデルを比較し、用途に合わせて選びやすいことです。モデルを入れ替えながら検証できるため、文章生成に強いモデル、検索補助に向くモデル、画像生成に使うモデルなどを業務ごとに選べます。
また、インフラ管理を抑えながら生成AI機能を導入でき、Knowledge Bases(ナレッジベース)で社内データ活用を始めやすい点も利点です。さらに、AgentsやAgentCoreを使えば、単なる回答型チャットから、業務システムと連携して処理を進めるAIエージェントへ発展させやすくなります。
AWSのIAM、KMS、CloudWatchなどの権限管理、暗号化、監査、ログ監視と組み合わせやすいことも、企業利用では重要です。コスト面では、従量課金やプロビジョンドスループットなど、用途に応じた設計ができます。
AWS Bedrock(ベッドロック)の注意点
AWS Bedrock(ベッドロック)では、モデルごとに得意分野、料金、遅延、対応リージョン、入力上限、出力品質が異なります。「一番新しいモデル」を選ぶのではなく、用途に合うモデルを選ぶことが重要です。
RAGの品質は、元データ、チャンク設計、埋め込みモデル、検索設定、リランキング、プロンプト設計に左右されます。社内文書を入れれば自動的に高品質な回答が返るわけではありません。
エージェントも便利ですが、ツール実行や権限設計を誤ると、誤操作や情報漏えいにつながります。実行できる操作を限定し、重要な処理には人間の承認を入れ、ログを残して検証できるようにしましょう。
コストは、推論回数、トークン量、埋め込み、検索、エージェント実行、ログ、周辺AWSサービスによって増えます。本番導入前にPoCを行い、回答品質、コスト、失敗時のフォールバック、運用負荷を確認することが大切です。
活用事例
| 用途 | 使うBedrock機能 | 期待効果 | 注意点 |
|---|---|---|---|
| カスタマーサポート | 基盤モデル、Knowledge Bases、Agents | FAQ、製品マニュアル、対応履歴を参照した回答支援 | 誤回答時の確認フローと権限管理が必要 |
| 社内ナレッジ検索 | Knowledge Bases、埋め込み、RAG | 社内規程、議事録、設計書、手順書を検索しやすくする | 元データの更新、重複、公開範囲を整理する |
| 営業・マーケティング | 基盤モデル、Knowledge Bases | 提案書、メール、広告文、顧客別資料の下書きを作成 | 顧客情報や社外秘情報の扱いに注意する |
| 開発・IT運用 | 基盤モデル、Agents、AgentCore | 障害ログの要約、手順書検索、コードレビュー支援 | 自動実行範囲と承認ステップを明確にする |
| 業務エージェント | Agents、AgentCore Runtime、Gateway、Identity | 申請チェック、チケット分類、CRM更新、レポート作成を支援 | ツール権限、監査ログ、失敗時の停止条件を設計する |
導入の基本ステップ
- 解決したい業務課題を決める。
- 使うデータと権限範囲を整理する。
- モデルを比較し、用途に合う基盤モデルを選ぶ。
- 必要に応じてKnowledge Bases(ナレッジベース)でRAGを構成する。
- ツール実行が必要ならAgentsやAgentCoreを検討する。
- Guardrails、IAM、ログ、評価指標を設定する。
- PoCで品質、コスト、運用負荷を確認してから本番化する。
初心者の場合は、まず社内FAQやマニュアル検索のような小さな業務から始めるのがおすすめです。回答品質とコストを測りながら、エージェント化や業務システム連携へ段階的に広げると、失敗時の影響を抑えやすくなります。
まとめ
AWS Bedrock(ベッドロック)は、基盤モデルを使うだけでなく、RAG、エージェント、ガードレール、評価、運用機能まで含めて生成AI活用を進めるためのAWSの重要基盤です。
2026年時点では、Knowledge Bases(ナレッジベース)、Agents、AgentCore、AgentCore Runtimeを理解すると、単なるチャットAIから、業務で動くAIエージェントへ発展させやすくなります。
まずは小さな社内検索や問い合わせ支援から始め、データ品質、権限、評価、コストを確認しながら広げるのが現実的です。最新の対応モデルやリージョンは変わるため、導入前にはAWS公式ドキュメントを確認しましょう。
参照元
- Amazon Bedrock Documentation
- Amazon Bedrock supported models
- Amazon Bedrock Knowledge Bases
- Amazon Bedrock Agents
- Amazon Bedrock AgentCore overview
- Amazon Bedrock AgentCore Runtime
- Amazon Bedrock Guardrails
更新履歴
| 更新日 | 更新内容 |
|---|---|
| 2026年5月 | AWS Bedrock(ベッドロック)の説明を2026年時点の内容に更新。Knowledge Bases、Agents、AgentCore、AgentCore Runtime、Guardrails、企業利用時の注意点を追加。 |