
標準化とは?データ分析で使う意味・計算方法・正規化との違いを解説

AIの初心者
『標準化』ってよく聞くんですけど、何をする処理なのかまだ曖昧です。どんな場面で使うのでしょうか?

AI専門家
標準化は、数値の平均とばらつきをそろえて、違う単位のデータを比べやすくする処理だよ。たとえば国語と数学の点数を比べるとき、平均点や点数の散らばりが違うと、点数だけでは公平に判断しにくいんだ。
AIの初心者
単に平均点との差を見るだけでは足りないんですね。
AI専門家
その通り。標準化では平均を0、標準偏差を1にそろえる。すると、平均からどれくらい離れている値なのかを同じ尺度で見られるようになるんだ。
データ分析や機械学習では、年齢、年収、身長、購買金額、アクセス回数のように、単位も数値の範囲も違うデータを同時に扱います。こうしたデータをそのまま使うと、値の大きい項目だけが強く影響してしまい、分析結果や学習結果が偏ることがあります。
標準化とは、データを平均0・標準偏差1の尺度に変換する前処理です。この記事では、標準化の意味、計算方法、正規化との違い、活用場面、注意点を初心者向けに整理します。

標準化とは何か
標準化は、データの中心を平均0に移し、ばらつきの単位を標準偏差1にそろえる変換です。変換後の値は、元の単位そのものではなく、平均から標準偏差何個分だけ離れているかを表します。
たとえば、あるテストで平均点が60点、標準偏差が10点のとき、80点は平均より20点高い値です。標準偏差10点を基準にすると、80点は平均から標準偏差2個分高い値だと読めます。別のテストの平均点やばらつきが違っても、このような基準に変換すれば比較しやすくなります。
データ分析では、年齢のように数十程度の値を取る項目と、年収のように数百万単位の値を取る項目が同じ表に並ぶことがあります。標準化を行うと、単位や桁の違いによる影響を抑え、各項目を同じ土俵で扱いやすくなります。
標準化が必要になる理由
標準化が必要になる大きな理由は、数値の大きさがそのまま重要度として扱われてしまう場面があるからです。たとえば、年齢が20から80の範囲、年収が300万円から1,000万円の範囲にあるデータを使うと、年収の数値幅のほうが圧倒的に大きく見えます。
距離や勾配を使う機械学習の手法では、この差が特に問題になります。値の範囲が大きい特徴量がモデルの判断に強く効き、値の範囲が小さい特徴量の情報が埋もれることがあるためです。標準化は、特徴量ごとの尺度をそろえ、学習を安定させるための基本的な前処理として使われます。
ただし、標準化はデータの意味を消す作業ではありません。元のデータが持っていた大小関係や分布の形を保ちながら、比較しやすい尺度へ移し替える処理です。異なる通貨を共通の通貨へ換算するように、分析しやすい基準へ変えると考えると理解しやすいでしょう。
標準化の計算方法
標準化では、まず対象データの平均値を求め、次に標準偏差を求めます。そのうえで、個々の値から平均値を引き、その結果を標準偏差で割ります。
\(x’ = \frac{x – \mu}{\sigma}\)ここで、\(x\) は元の値、\(\mu\) は平均値、\(\sigma\) は標準偏差、\(x’\) は標準化後の値です。標準化後のデータは、平均が0、標準偏差が1になるように変換されます。
計算の流れは単純です。たとえば、元の値が80、平均が60、標準偏差が10なら、標準化後の値は \((80 – 60) / 10 = 2\) です。これは「平均より標準偏差2個分高い」という意味になります。
実務では、表計算ソフトでも計算できますし、Pythonでは scikit-learn の StandardScaler などを使って処理できます。ただし機械学習では、学習データで求めた平均と標準偏差を、検証データやテストデータにも同じように適用する点が重要です。全データを先にまとめて標準化すると、テストデータの情報が学習側へ漏れることがあるためです。
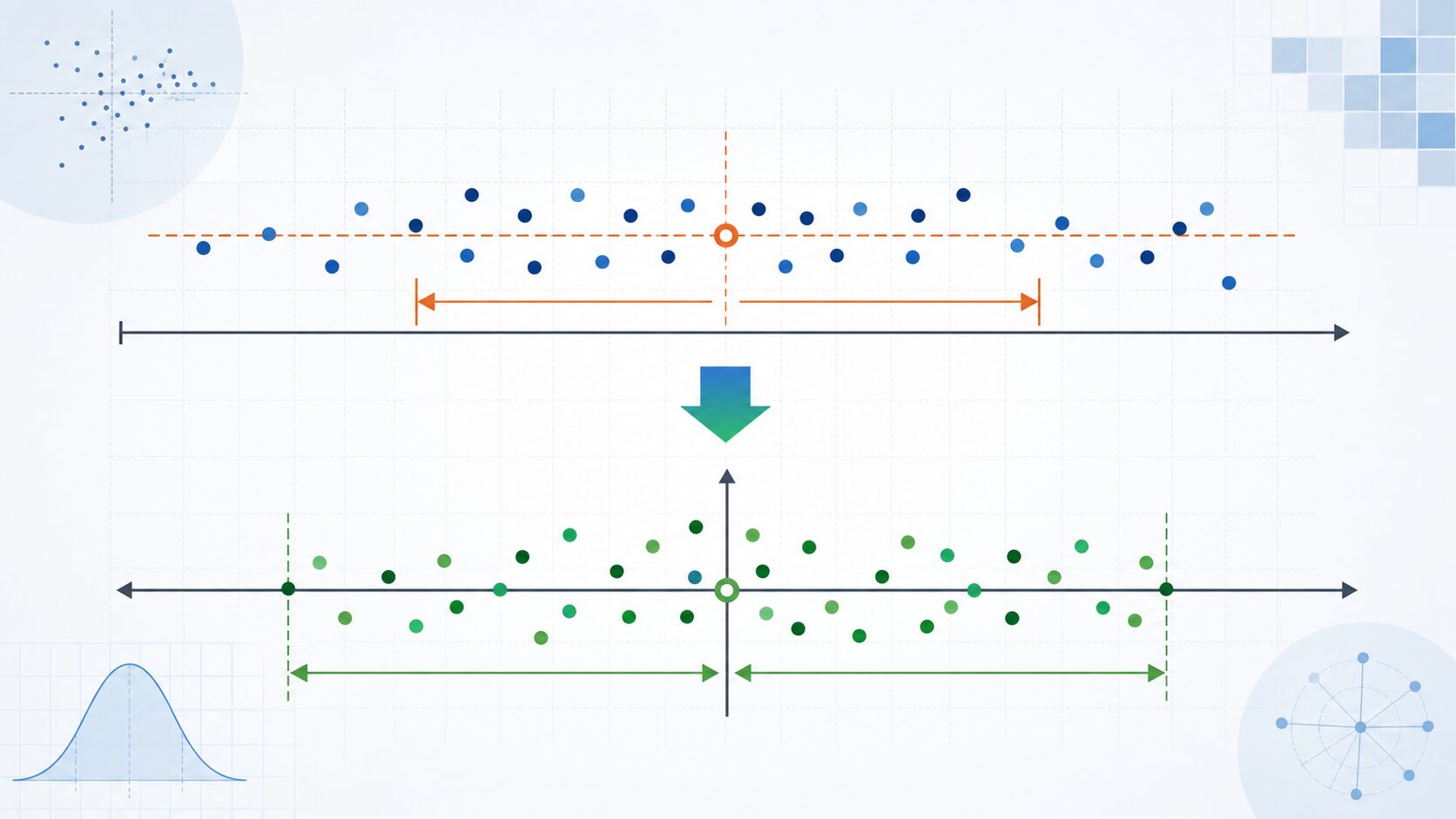
標準化と正規化の違い
標準化とよく比較される処理に、正規化があります。どちらもデータの尺度を調整する前処理ですが、そろえる基準が異なります。
標準化は平均と標準偏差を使って、平均0・標準偏差1へ変換する方法です。一方、正規化は最小値と最大値を使い、値を0から1などの決まった範囲へ収める方法として使われることが多いです。
| 項目 | 標準化 | 正規化 |
|---|---|---|
| 主な基準 | 平均値と標準偏差 | 最小値と最大値 |
| 変換後の目安 | 平均0、標準偏差1 | 0から1など一定範囲 |
| 向いている場面 | 平均からの離れ具合を見たい場合、正規分布に近いデータ | 値の範囲を固定したい場合、画像データなど |
| 注意点 | 外れ値で平均や標準偏差が歪む | 外れ値で多くの値が狭い範囲に押し込まれる |
どちらを使うべきかは、データの性質と分析の目的によって変わります。正規分布に近い連続値の特徴量を扱う場合は標準化が候補になります。値を明確な範囲へ収めたい場合や、最小値と最大値に意味がある場合は正規化が使いやすいことがあります。
標準化が使われる場面
標準化は、さまざまな分野でデータを比較しやすくするために使われます。特に、複数の項目を同時に扱う分析や、特徴量の尺度が学習結果に影響しやすい機械学習で重要です。
金融分野では、株価、為替レート、金利、取引量など、単位も変動幅も違うデータを比較します。標準化によって、異なる市場や指標の動きを同じ基準で見やすくなります。
医療分野では、検査値やバイタルデータなどを扱います。測定項目ごとに単位が違うため、統計分析や予測モデルに入れる前に尺度をそろえることがあります。ただし医療データは解釈が重要なので、標準化後の値だけでなく、元の単位での意味も確認する必要があります。
販売促進やマーケティングでは、購買金額、来店回数、サイト滞在時間、クリック数などを組み合わせて顧客傾向を分析します。標準化を使うと、特定の大きな数値だけに分析が引っ張られるのを抑え、複数の行動指標を比べやすくなります。
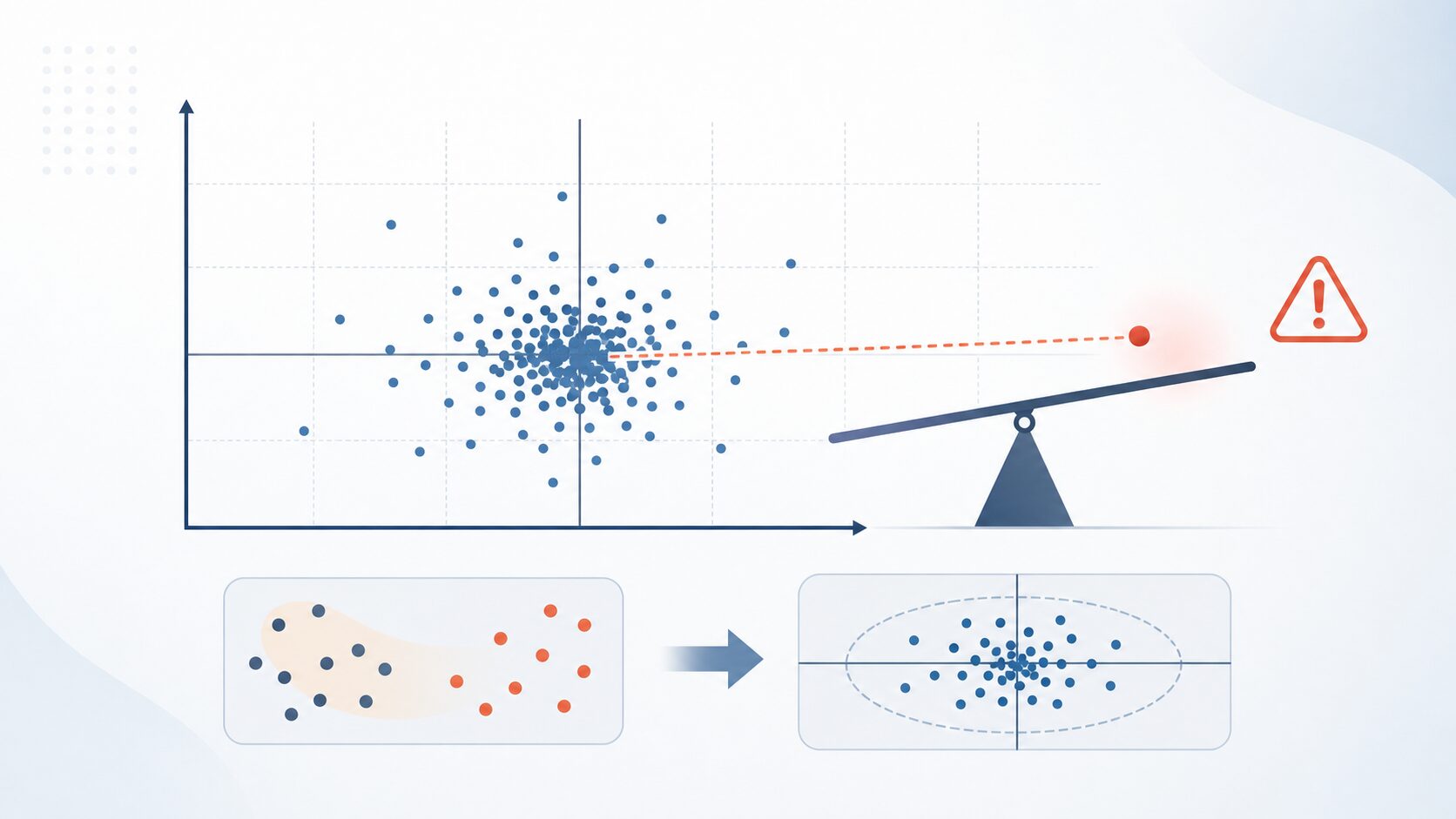
標準化を使うときの注意点
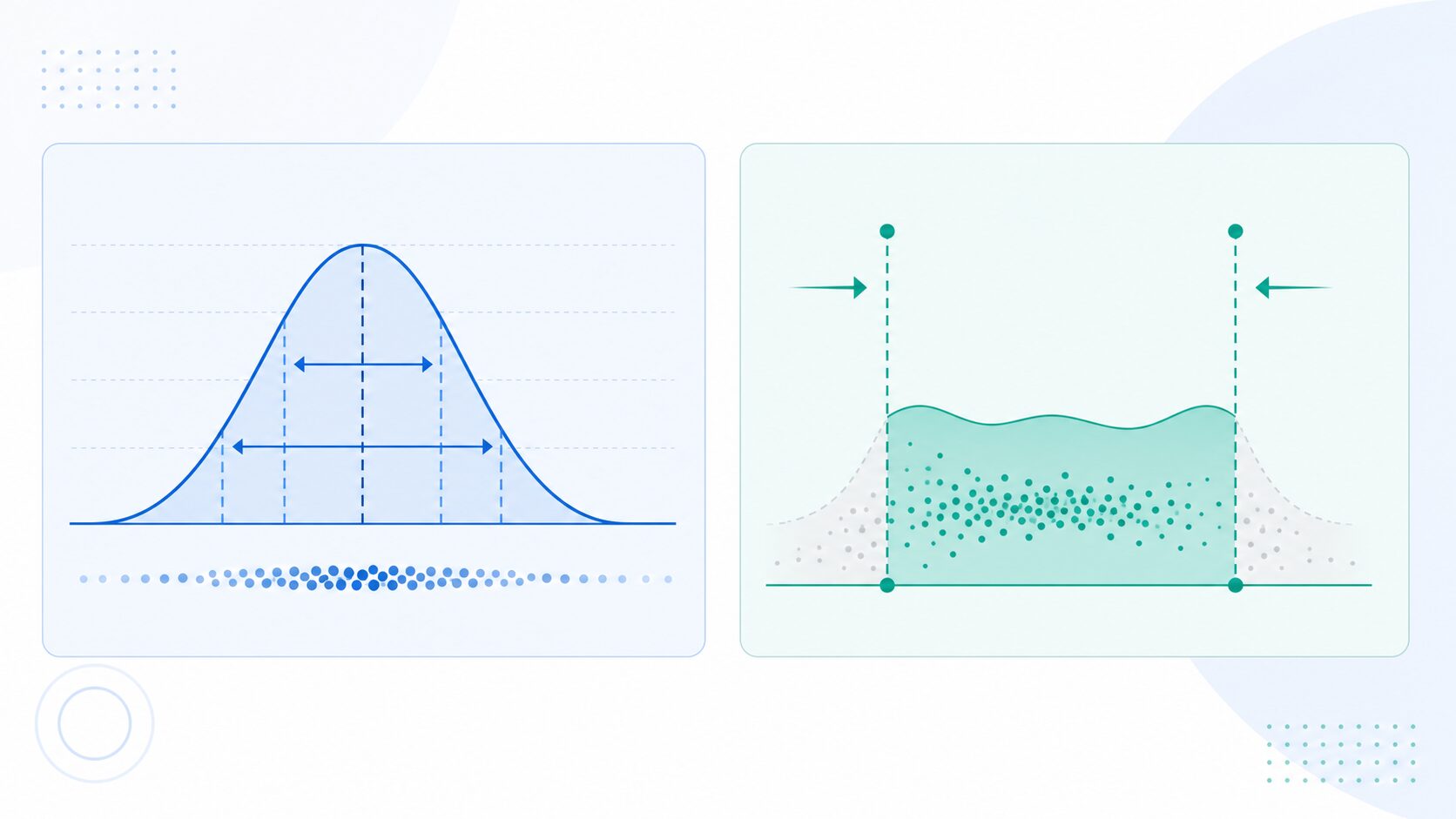
標準化は便利な前処理ですが、万能ではありません。まず、標準化は分布の形を変える処理ではありません。偏った分布は、標準化しても偏った形のままです。データが大きく歪んでいる場合は、対数変換や正規化など、別の処理を検討することがあります。
次に、標準化は外れ値の影響を受けます。平均値と標準偏差を使うため、極端に大きい値や小さい値があると、変換の基準そのものが引っ張られてしまいます。外れ値が多い場合は、外れ値を確認したうえで、中央値や四分位範囲を使うロバストな尺度変換を検討するとよいでしょう。
また、標準化後の値は元の単位ではありません。身長を標準化した値が0.5だったとしても、それは0.5センチメートルという意味ではなく、平均より標準偏差0.5個分高いという意味です。分析結果を人に説明する場合は、必要に応じて元の尺度に戻す、または「平均との差」として説明する工夫が必要です。
機械学習では、標準化のタイミングにも注意します。学習データだけで平均と標準偏差を計算し、その値を使って検証データやテストデータを変換します。これにより、将来の未知データを扱う状況に近い形で評価できます。
まとめ
標準化とは、データを平均0・標準偏差1の尺度へ変換し、単位や数値範囲の違う項目を比較しやすくする処理です。データ分析や機械学習では、特徴量の尺度をそろえ、特定の項目だけが過度に影響するのを防ぐ目的でよく使われます。
計算方法は、元の値から平均を引き、標準偏差で割るだけです。ただし、外れ値の影響、分布の形、標準化後の値の解釈、学習データとテストデータの扱いには注意が必要です。正規化との違いも押さえたうえで、データの性質と分析目的に合った前処理を選びましょう。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年6月11日 | 計算式、正規化との差、外れ値への扱いを本文に補足 |