
AICとは?赤池情報量基準の意味・計算式・使い方を解説

AIの初心者
「赤池情報量基準」って、結局何を見るための指標なんですか?

AI専門家
簡単に言うと、複数の統計モデルから、データへの当てはまりと複雑さのバランスがよいものを選ぶための基準だよ。
AIの初心者
当てはまりが良いだけではだめなんですか?
AI専門家
そう。複雑すぎるモデルは手元のデータには合っても、新しいデータで外れやすい。AICはその行き過ぎを避ける目安になるんだ。
赤池情報量基準とは。
AIC(赤池情報量基準)は、統計モデルを選ぶときに使う代表的な指標です。英語では Akaike Information Criterion と呼ばれ、統計学、機械学習、時系列分析などで広く使われます。
モデル選択では、データによく当てはまることだけでなく、モデルが複雑になりすぎていないことも重要です。AICはこの二つを同時に見て、候補モデルの中から比較的よいモデルを選びやすくします。
この記事では、AICとは何か、値が小さいほどよいと言われる理由、計算式の読み方、実務で使うときの注意点を順番に整理します。
AICとは?統計モデルを選ぶための基準

AICとは、複数の統計モデルを比較し、どのモデルがデータをうまく説明しそうかを判断するための基準です。日本語では「赤池情報量基準」または「赤池情報量規準」と表記されます。
たとえば、気温を予測するモデルを作るとします。日照時間だけを使う単純なモデル、日照時間と湿度を使うモデル、さらに風速まで加えるモデルなど、候補はいくつも考えられます。使う情報を増やすほど学習データには合いやすくなりますが、必ずしも将来の予測がよくなるとは限りません。
AICは、モデルの「当てはまりの良さ」と「複雑さ」を一つの値にまとめます。基本的には、AICの値が小さいモデルほど、比較対象の中では望ましいと判断します。ただし、AICは絶対的な点数ではありません。AICが100だから良い、200だから悪いという読み方ではなく、同じデータで作った候補モデル同士の大小を比べます。
| 項目 | 説明 |
|---|---|
| AICの役割 | 候補モデルを比較し、当てはまりと複雑さのバランスがよいモデルを選ぶ |
| 基本的な読み方 | 同じデータで比較したとき、AICが小さいモデルを優先する |
| 使われる場面 | 回帰分析、時系列分析、機械学習のモデル比較など |
| 注意点 | 値そのものではなく、候補モデル間の相対的な差を見る |
AICが重視する「当てはまり」と「複雑さ」

統計モデルを作る目的は、集めたデータの背後にある規則性をうまく捉えることです。しかし、手元のデータにぴったり合うモデルを選べばよい、という単純な話ではありません。
モデルが単純すぎると、重要な特徴を取り逃がします。これは「過小適合」と呼ばれ、データの大まかな傾向さえ説明できない状態です。逆にモデルが複雑すぎると、データに含まれる偶然のゆらぎやノイズまで覚えてしまいます。これは「過学習」と呼ばれ、新しいデータに対する予測が悪くなりやすい状態です。
AICは、この二つの問題の中間を探すための考え方です。当てはまりが良いほど評価し、複雑なモデルほどペナルティを加えることで、単純すぎず複雑すぎないモデルを選びやすくします。
| モデルの状態 | 特徴 | 起こりやすい問題 |
|---|---|---|
| 単純すぎる | 変数や構造が少なく、データの傾向を捉えきれない | 過小適合 |
| 複雑すぎる | 学習データの細かなゆらぎまで追いかける | 過学習 |
| バランスがよい | 主要な傾向を捉えながら、余計な複雑さを抑える | 候補の中で選びやすい |
AICの計算式と読み方

AICは、次の式で表されます。
\(\mathrm{AIC} = -2 \log L + 2k\)ここで、\(L\) は尤度を表します。尤度とは、あるモデルが観測データをどれくらいもっともらしく説明できるかを表す量です。実際には最大対数尤度 \(\log L\) を使い、値が大きいほど、そのモデルはデータにうまく当てはまっていると考えます。
\(k\) はパラメータ数です。回帰モデルであれば係数や切片など、モデルを調整するための値の数に対応します。パラメータ数が多いほど表現力は増えますが、過学習の危険も高くなります。
式を見ると、最大対数尤度 \(\log L\) が大きいほど \(-2 \log L\) は小さくなり、AICも小さくなります。一方で、パラメータ数 \(k\) が増えると \(2k\) が大きくなり、AICも大きくなります。つまりAICは、よく当てはまるモデルを評価しつつ、複雑さには罰則を与える仕組みになっています。
| 式の要素 | 意味 |
|---|---|
| \(-2 \log L\) | データへの当てはまりの良さを反映する部分。小さいほど当てはまりがよい |
| \(2k\) | モデルの複雑さに対するペナルティ。パラメータ数が多いほど大きい |
| AIC全体 | 当てはまりと複雑さを合わせた比較用の値。小さいほど優先しやすい |
AICを使ったモデル選択の手順
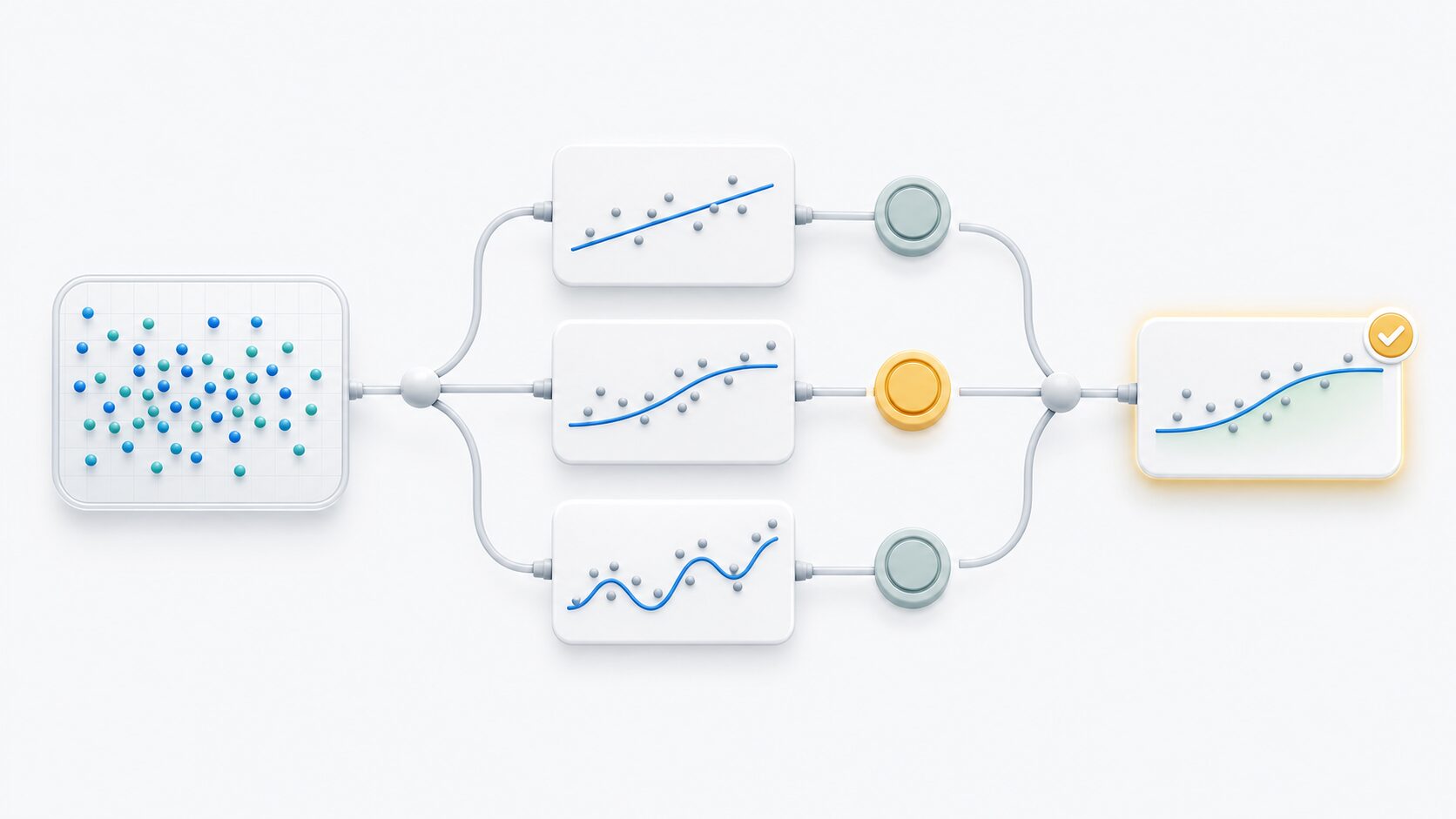
AICを使うときは、まず同じ目的を持つ候補モデルをいくつか用意します。たとえば気温予測なら、日照時間だけを使うモデル、日照時間と湿度を使うモデル、日照時間・湿度・風速を使うモデルを比較対象にできます。
次に、すべての候補モデルを同じデータで推定し、それぞれのAICを計算します。AICが100、105、110のように並んだ場合、100のモデルが最も小さいため、候補の中では優先しやすいモデルと判断します。
ただし、AIC差がごく小さい場合は、機械的に最小値だけを選ぶのではなく、モデルの解釈しやすさ、使う変数の妥当性、予測結果の安定性も確認します。実務では、AICはモデル選択の出発点として使い、残差の確認や予測精度の検証と組み合わせるのが自然です。
| 手順 | 確認すること |
|---|---|
| 1. 候補モデルを作る | 同じ目的に対して、変数や構造の異なるモデルを用意する |
| 2. 同じデータで推定する | 比較条件をそろえ、AICの大小を意味のあるものにする |
| 3. AICを比較する | 最も小さいAICのモデルを候補として選ぶ |
| 4. 他の観点も見る | 説明しやすさ、残差、予測性能、業務上の妥当性を確認する |
AICを見るときの注意点
AICは便利な指標ですが、万能ではありません。まず押さえたいのは、AICが小さいモデルが「真のモデル」だと保証されるわけではない、という点です。現実の現象は複雑で、手元のデータや候補モデルの範囲によって結果は変わります。
また、異なるデータセットで計算したAICを直接比較してはいけません。AICはデータへの当てはまりを含む指標なので、データが変わると値の意味も変わります。比較するモデルは、同じ観測データ、同じ目的変数、同じ条件で推定する必要があります。
さらに、AICはモデルの複雑さを主にパラメータ数で扱います。非線形な構造を持つモデルや、前処理・特徴量設計が複雑なモデルでは、パラメータ数だけでは実際の複雑さを十分に表せない場合があります。そのため、AICだけで結論を出さず、ドメイン知識や予測検証と合わせて判断することが大切です。
BICや交差検証との違い
AICと並んでよく出てくる指標にBICがあります。BICはベイズ情報量基準と呼ばれ、AICと同じように当てはまりと複雑さを考慮します。ただし、一般にBICはサンプルサイズを含むペナルティを使うため、AICよりも複雑なモデルを避ける方向に働きやすいことがあります。
一方、交差検証は、データを分割して学習用と検証用に分け、未知データに対する予測性能を確かめる方法です。AICは数式にもとづくモデル比較の指標、交差検証は実際の予測性能を検証する手続き、と考えると違いがつかみやすくなります。
| 方法 | 主な見方 | 特徴 |
|---|---|---|
| AIC | 当てはまりと複雑さのバランス | 予測重視のモデル比較で使われやすい |
| BIC | 当てはまりと、より強めの複雑さペナルティ | シンプルなモデルを選びやすい場合がある |
| 交差検証 | 未知データでの予測性能 | 実際の予測誤差を確認しやすい |
まとめ
AIC(赤池情報量基準)は、統計モデルを選ぶときに、データへの当てはまりとモデルの複雑さを同時に評価するための指標です。基本的には、同じデータで比較した候補モデルの中でAICが小さいものを優先します。
重要なのは、AICを絶対的な良し悪しの点数として読まないことです。AICは候補モデル間の比較に使う相対的な目安であり、異なるデータセット同士の比較には向きません。最終的なモデル選択では、AICに加えて、残差の確認、予測精度、解釈しやすさ、業務上の妥当性も合わせて見ると判断しやすくなります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月2日 | 初回公開 |
| 2026年5月31日 | 式の読み方と比較手順を補い、注意点を整理 |