白色化とは?意味・仕組み・活用例をわかりやすく解説

AIの初心者
『白色化』って標準化とどう違うんですか?どちらもデータのばらつきを整える処理ですよね?

AI専門家
近い処理だけれど、目的が少し違います。標準化は各特徴量の平均を0、分散を1にそろえる処理で、白色化はそれに加えて特徴量同士の相関を取り除きます。身長と体重のように一緒に増えやすい値を、分析しやすい形に変換するイメージです。
AIの初心者
相関を取り除くと、特徴量を別々の情報として扱いやすくなるということですか?
AI専門家
その通りです。相関が強いままだと、似た情報を二重に見てしまう場合があります。白色化を使うと、重複した影響を抑え、機械学習やデータ分析で特徴を整理しやすくなります。
白色化とは。
白色化とは、データの平均やばらつきを整えるだけでなく、特徴量同士の相関も取り除く前処理です。標準化を一歩進めた変換として、機械学習、画像認識、音声認識、自然言語処理などで使われます。
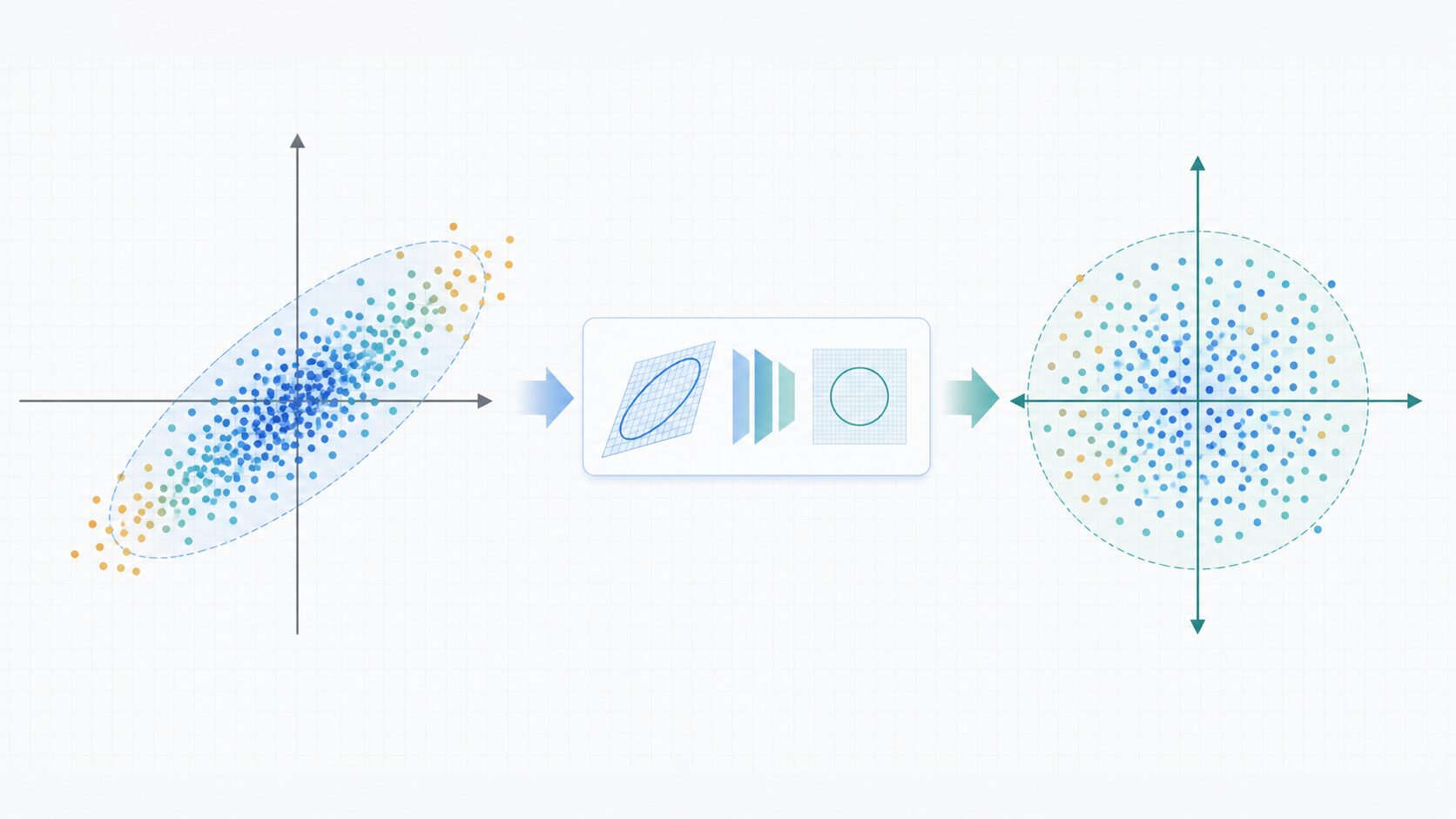
白色化とは?相関を取り除き分散をそろえる前処理
白色化とは、データを変換して、各特徴量の平均を0に近づけ、分散を1にそろえ、さらに特徴量同士の相関を取り除く処理です。機械学習や統計では、データの前処理として登場することが多く、英語では whitening と呼ばれます。
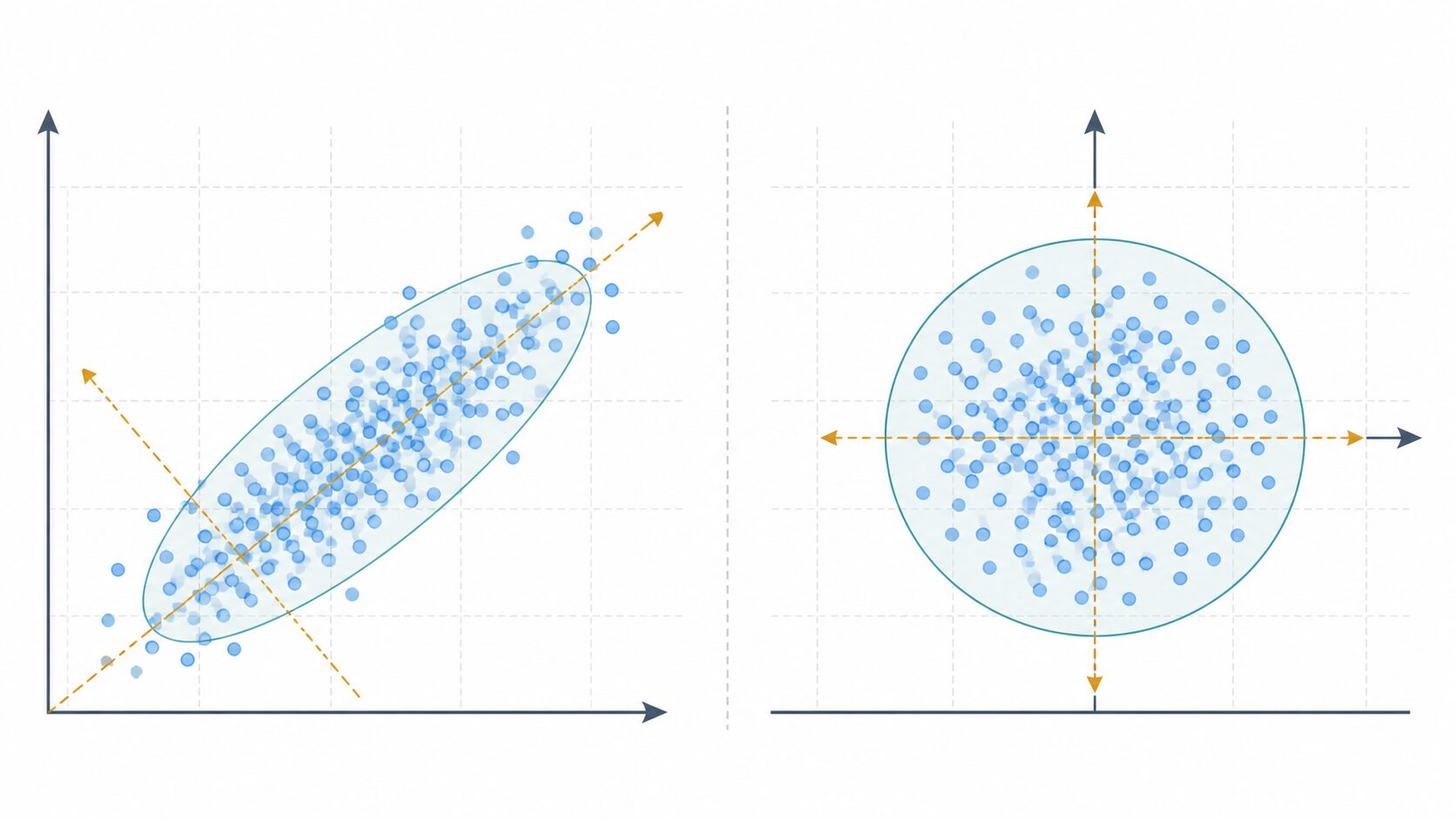
ポイントは、白色化のゴールが「無相関で、分散がそろったデータ」にすることです。たとえば身長と体重のように、片方が大きいともう片方も大きくなりやすい特徴量があります。このような相関が残ったままだと、モデルが同じ傾向を重複して学習することがあります。
白色化では、まずデータの中心をそろえ、次にデータの伸びている方向を見つけ、その方向ごとのばらつきを調整します。変換後のデータでは、ある特徴量が増えたからといって別の特徴量も同じように増える、という関係が弱くなります。
数学的には、白色化後のデータの共分散行列が単位行列になることを目指します。共分散行列は、特徴量同士の関係をまとめた表のようなものです。単位行列に近い状態では、対角成分の分散は1、対角以外の共分散は0に近くなります。
\(\mathrm{Cov}(Z) = I\)ここで \(Z\) は白色化後のデータ、\(I\) は単位行列を表します。数式だけを見ると難しく感じますが、意味としては「各特徴量の強さをそろえ、互いの重なりを減らす」と捉えると理解しやすくなります。
標準化との違い
標準化と白色化はどちらもデータの尺度を整える処理ですが、変換する範囲が異なります。標準化は、各特徴量について平均を0、分散を1にそろえます。一方、白色化はそれに加えて、特徴量同士の相関を取り除きます。
たとえば、価格と性能を比較したい場合、価格は円、性能は点数で表されるため、そのままでは大きさを比べにくいことがあります。標準化を行えば、単位や値の範囲が違う特徴量を同じ土俵に乗せやすくなります。
ただし、標準化をしても特徴量同士の相関は残ります。身長と体重を標準化しても、身長が高い人ほど体重も重くなりやすいという関係は消えません。白色化はこの関係まで調整するため、標準化よりも踏み込んだデータ変換だと言えます。
| 手法 | 主な目的 | 相関への対応 | 例 |
|---|---|---|---|
| 標準化 | 平均と分散をそろえる | 相関は基本的に残る | 価格と性能の尺度をそろえる |
| 白色化 | 平均・分散に加えて相関も整える | 特徴量同士の相関を取り除く | 身長と体重の重複した情報を整理する |
初心者が混同しやすい点は、白色化が「標準化の別名」ではないことです。標準化は各列を個別に整える処理、白色化は列同士の関係まで見て変換する処理、と分けて考えると整理しやすくなります。
白色化の基本手順
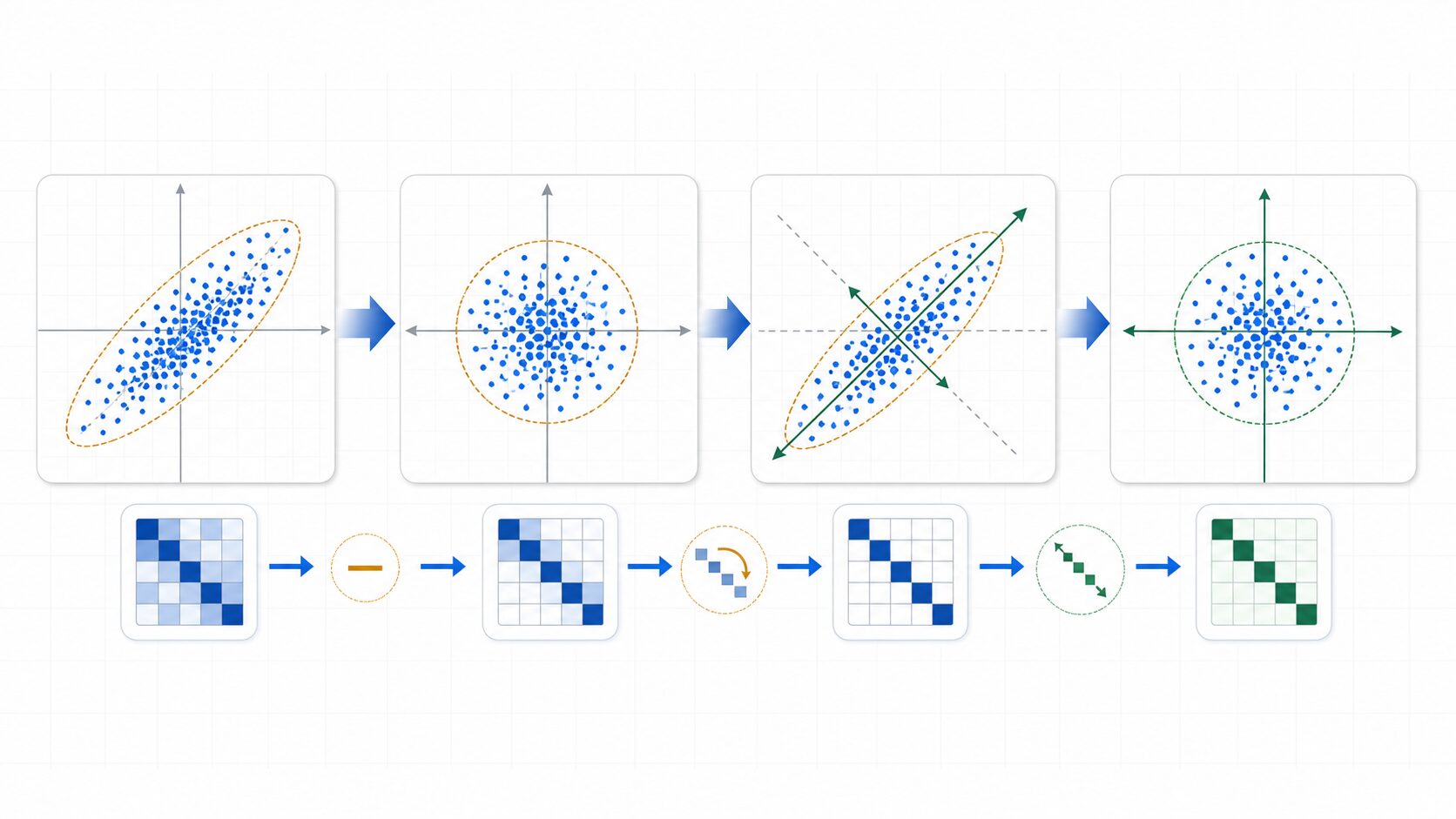
白色化は、データの分布を見ながら線形変換を行う処理です。代表的な流れは、中心化、共分散行列の計算、固有値分解、スケーリングの4段階で説明できます。
まず、各特徴量から平均を引いて、データの中心を原点付近へ移します。この処理を中心化と呼びます。中心化を行うことで、データの位置ではなく、広がり方や相関に注目しやすくなります。
次に、共分散行列を計算します。共分散行列には、各特徴量がどれくらいばらついているか、また特徴量同士がどの方向に一緒に動きやすいかが入っています。白色化では、この行列を見て、データがどの方向に強く伸びているかを調べます。
その後、共分散行列の固有値と固有ベクトルを求めます。固有ベクトルはデータが伸びている方向、固有値はその方向のばらつきの大きさを表します。データを固有ベクトルの方向へ回転し、固有値の平方根で割ることで、各方向の分散をそろえます。
代表的な変換は次のように書けます。
\(Z = \Lambda^{-1/2} U^\top (X – \mu)\)ここで \(X\) は元データ、\(\mu\) は平均、\(U\) は固有ベクトルを並べた行列、\(\Lambda\) は固有値を並べた対角行列、\(Z\) は白色化後のデータです。実装では NumPy、scikit-learn、深層学習フレームワークなどの関数を使うことが多く、すべてを手計算する必要はありません。
実務では、固有値が非常に小さいと割り算の影響が大きくなるため、\(\epsilon\) のような小さな値を足して安定させることがあります。
\(Z = (\Lambda + \epsilon I)^{-1/2} U^\top (X – \mu)\)この \(\epsilon\) は、ゼロに近い値で割ってノイズを強めすぎないための調整項です。白色化をコードで使うときも、この安定化が入っているかを確認すると安心です。
白色化が役立つ場面

白色化は、特徴量同士の重複を減らしたい場面で役立ちます。特に、入力データの各成分が強く関係し合っている場合、白色化によってモデルが扱う情報を整理できます。
画像認識では、隣り合う画素や色の成分が似た値になりやすく、特徴量同士に相関が生まれます。白色化を使うと、明るさや色の偏り、局所的な重複を弱め、エッジや形のような特徴を扱いやすくできる場合があります。
音声認識でも、周波数成分や時間方向の特徴には相関が含まれます。周囲の雑音や話者の違いが混ざっている場合、前処理で特徴を整理することで、音声本来のパターンを見つけやすくなります。
自然言語処理では、単語や文をベクトルで表現すると、意味の近い成分が似た方向に集まることがあります。白色化やそれに近い変換を使うと、ベクトル空間の偏りを調整し、検索、分類、クラスタリングで扱いやすくなることがあります。
ただし、すべてのモデルで白色化が必要になるわけではありません。現代の深層学習では、バッチ正規化、レイヤー正規化、埋め込みの正規化など別の仕組みで分布を整えることも多くあります。白色化は、相関の強さが分析や学習の邪魔をしているときに検討する前処理として考えるのが現実的です。
| 分野 | 白色化で期待できること | 注意したい点 |
|---|---|---|
| 画像認識 | 画素や色成分の重複を減らし、特徴を見やすくする | 画像の自然な構造まで変えすぎない |
| 音声認識 | 雑音や話者差の影響を整理しやすくする | 小さな成分のノイズ増幅に注意する |
| 自然言語処理 | ベクトル空間の偏りを調整する | 意味構造を壊していないか評価する |
白色化の注意点
白色化は便利な前処理ですが、強い変換を行うため注意点もあります。特に、計算コスト、ノイズ増幅、元データの意味の変化は事前に確認しておきたいポイントです。
1つ目は計算コストです。白色化では共分散行列を計算し、固有値分解や特異値分解を行います。特徴量の数が多いほど行列が大きくなるため、大規模データでは処理時間やメモリ使用量が問題になることがあります。
2つ目はノイズ増幅です。白色化では分散が小さい方向も分散1にそろえようとします。もしその方向に含まれている情報の多くがノイズであれば、白色化によってノイズまで目立つ形になる可能性があります。そのため、実務では小さな固有値をそのまま扱わず、\(\epsilon\) を足したり、主成分を一部だけ使ったりします。
3つ目は解釈性の変化です。白色化後の特徴量は、元の特徴量を混ぜ合わせた新しい軸になることがあります。分析結果を人間が説明する必要がある場合、変換後の軸が何を意味しているのかが分かりにくくなる点に注意が必要です。
また、白色化はデータの分布を人工的に変える処理です。元の相関構造自体に意味がある場合や、相関をモデルに学習させたい場合には、白色化が逆効果になることもあります。使う前に、標準化、PCA、正規化、白色化のどれが目的に合うかを比べることが大切です。
PCA白色化とZCA白色化の違い
白色化にはいくつかの種類があります。代表的なものが PCA白色化 と ZCA白色化 です。どちらも相関を取り除き、分散をそろえる点は同じですが、変換後の見え方が異なります。
PCA白色化は、データを主成分の軸へ回転してから分散をそろえます。主成分分析とつながりが深く、次元削減と組み合わせて使いやすい方法です。ただし、変換後の軸は元の特徴量とは向きが変わるため、直感的な見た目や元データとの対応は弱くなります。
ZCA白色化は、白色化したあとで元の座標系に近い向きへ戻すような変換です。画像データでは、白色化後も元画像に近い見た目を保ちやすいため、前処理の結果を視覚的に確認したい場面で使われることがあります。
| 種類 | 特徴 | 向いている場面 |
|---|---|---|
| PCA白色化 | 主成分の軸へ回転して分散をそろえる | 次元削減や特徴抽出と組み合わせたい場合 |
| ZCA白色化 | 元データに近い向きを保ちながら白色化する | 画像など、変換後の見た目も確認したい場合 |
まとめ
白色化とは、データの平均と分散を整えるだけでなく、特徴量同士の相関を取り除く前処理です。標準化が各特徴量の尺度をそろえる処理であるのに対し、白色化は共分散行列を単位行列に近づけ、特徴量の重複を減らすところまで踏み込みます。
機械学習やデータ分析では、画像、音声、テキストベクトルなど、相関の強いデータを扱う場面で役立つことがあります。一方で、計算コストがかかる、ノイズを増幅する、元の特徴量の意味が見えにくくなるといった注意点もあります。
初めて学ぶ場合は、まず「標準化は各特徴量をそろえる」「白色化は特徴量同士の関係まで整える」と覚えるとよいでしょう。そのうえで、分析の目的、モデルの性質、データの相関の強さを見ながら、白色化を使うべきか判断することが大切です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月21日 | 数式の読み方と白色化の使い分けを補い、手順を追いやすく更新 |