次元削減とは?データを見やすくする基本をわかりやすく解説

AIの初心者
「次元削減」って、データを小さくするだけの話なんですか?

AI専門家
小さくするだけではありません。大切な情報をできるだけ残しながら、データを人間にも機械にも扱いやすい形へ整理する考え方です。
AIの初心者
少ない特徴にまとめると、どんな場面で役に立つんですか?
AI専門家
高次元データを2次元や3次元にして可視化したり、計算を軽くしたり、機械学習でノイズの影響を減らしたりできます。代表例がPCAです。
次元削減とは。
次元削減とは、たくさんの特徴量を持つデータから重要な情報をできるだけ残し、より少ない特徴量で表現し直す手法です。高次元データを2次元や3次元に落とし込めば、散布図で全体像を見たり、データ同士の関係を直感的に把握したりしやすくなります。この記事では、次元削減の意味、メリット、代表手法であるPCA、ワインデータでの活用例、Pythonで実装する流れ、使うときの注意点を初心者向けに整理します。
次元削減とは?多次元データを見やすくする考え方
機械学習やデータ分析で扱うデータは、多くの場合、複数の特徴量で表されます。たとえば人の健康データなら、身長、体重、年齢、血圧、運動量などが特徴量です。このような特徴量の一つひとつを、データ分析では「次元」と考えます。
特徴量が3個なら3次元データ、13個なら13次元データです。特徴量が増えるほど情報は増えますが、人間が全体像をつかむのは難しくなります。特に4次元以上のデータは、そのまま図として見ることができません。
そこで使われるのが次元削減です。次元削減は、元のデータに含まれる重要な構造をできるだけ保ちながら、少ない次元に変換します。身長、体重、年齢をそのまま見る代わりに、体格を表す指標と年齢の2軸で健康状態を確認するようなイメージです。
重要なのは、次元削減は単に不要な列を削除する作業ではないという点です。代表手法のPCAでは、複数の特徴量を組み合わせて新しい軸を作ります。そのため、元の特徴量をそのまま残す場合とは違い、データの見方そのものを整理し直す処理だと考えると理解しやすくなります。
次元削減で得られる3つの利点
次元削減の大きな利点は、データを見やすくし、計算を扱いやすくし、機械学習で重要な特徴を見つけやすくすることです。特にデータ可視化と前処理では、次元削減がよく使われます。
| 利点 | 内容 | 具体例 |
|---|---|---|
| データを可視化しやすい | 高次元データを2次元や3次元に変換し、散布図で全体像を確認できる。 | ワインの成分データを2次元にして、種類ごとのまとまりを見る。 |
| 計算量を減らせる | 特徴量の数を減らすことで、学習や予測に必要な計算を軽くできる。 | 画像や文章のような特徴量が多いデータを、扱いやすい大きさに圧縮する。 |
| ノイズを減らせる | 重要度の低い変動を取り除き、主要なパターンを見つけやすくする。 | 測定誤差やばらつきの影響を抑えて、分類に効く特徴を残す。 |
一方で、次元を減らせば必ず精度が上がるわけではありません。削減しすぎると必要な情報まで失われます。次元削減は、目的に合わせて「どの程度まで情報を残すか」を調整しながら使う手法です。
代表手法のPCAとは

PCAは主成分分析とも呼ばれ、次元削減の代表的な手法です。PCAは、データのばらつきが最も大きい方向を探し、その方向を新しい軸としてデータを表します。この新しい軸を主成分と呼びます。
データがある方向に大きく広がっている場合、その方向にはデータの違いを説明する重要な情報が多く含まれていると考えられます。PCAは、このばらつきの大きい方向から順番に主成分を作り、少ない軸でデータ全体の特徴を表そうとします。
PCAを数学的に見ると、データを中心化し、特徴量同士のばらつきや関係をもとに主成分の方向を求めます。ただし初心者向けには、まず「データの散らばり方を最もよく説明する方向を探す方法」と捉えると十分です。PCAは線形な変換なので、元の特徴量の組み合わせで新しい軸を作ります。そのため、比較的解釈しやすく、機械学習の前処理や探索的データ分析でよく使われます。
| PCAの目的 | データのばらつきをなるべく保ちながら、少ない次元で表現する。 |
|---|---|
| 第1主成分 | データのばらつきが最も大きい方向。 |
| 第2主成分 | 第1主成分と直交し、その条件の中でばらつきが大きい方向。 |
| 使いやすい場面 | 特徴量が多いデータの可視化、ノイズ低減、機械学習前処理。 |
ワインデータで見る次元削減の使いどころ
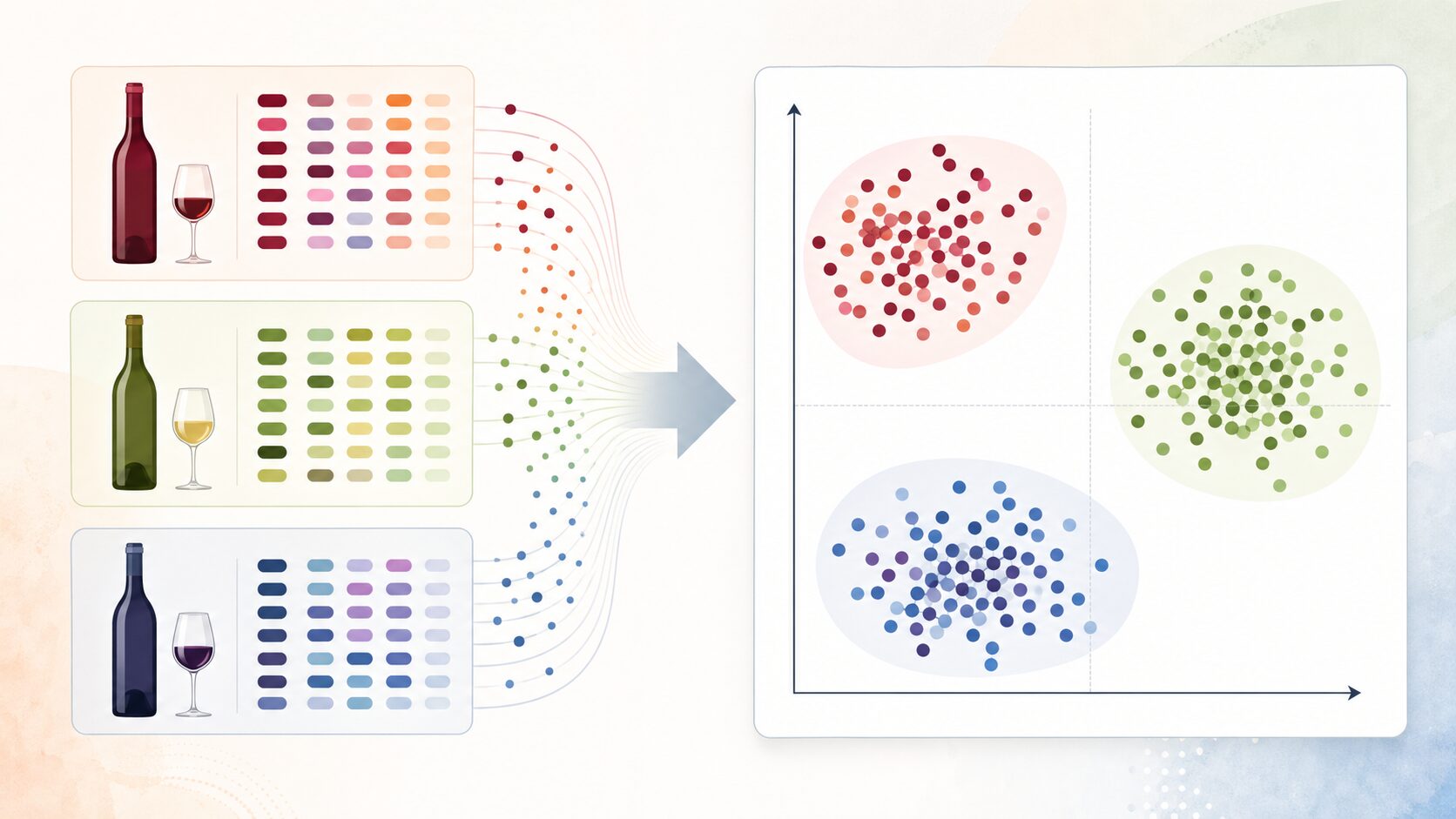
次元削減の効果を理解する例として、ワインデータはよく使われます。ワインにはアルコール量、酸味、色の濃さ、成分比率など、多くの数値的な特徴があります。これらをすべて同時に眺めても、種類ごとの違いは見えにくいものです。
PCAを使って13種類の特徴量を2次元に変換すると、ワインのサンプルを散布図上の点として表示できます。もし同じ種類のワインが近い位置に集まるなら、そのデータには種類ごとの特徴が含まれていると考えられます。
このとき、散布図の軸は「アルコール量」や「酸味」そのものではなく、複数の特徴量を組み合わせた主成分です。そのため、グラフは「元の特徴量をそのまま2つ選んだ図」ではなく、データ全体のばらつきを見やすくするために作られた新しい地図だと考えるとよいでしょう。
実務でも、顧客データ、画像特徴量、文章ベクトル、センサーデータなど、多くの特徴を持つデータをまず2次元に可視化して、外れ値やクラスタの有無を確認することがあります。次元削減は、モデルを作る前にデータの性質を知るための探索にも役立ちます。
PythonでPCAを実装する流れ
PythonでPCAを試す場合は、scikit-learnを使うと実装しやすくなります。基本的な流れは、データの読み込み、特徴量の標準化、PCAの適用、変換後データの可視化です。
特にPCAでは、標準化が重要です。特徴量ごとの単位や値の大きさが違うと、値の大きい特徴量の影響が強く出てしまいます。たとえば「年齢」と「年収」を同時に扱う場合、年収の数値が大きいため、標準化なしではPCAの結果が偏ることがあります。
| 手順 | 内容 |
|---|---|
| 1. データを用意する | CSVやscikit-learnのサンプルデータなどを読み込む。 |
| 2. 特徴量を標準化する | 平均0、分散1にそろえ、尺度の違いを抑える。 |
| 3. PCAを適用する | 2次元や3次元など、目的に合わせた次元数へ変換する。 |
| 4. 結果を可視化する | 散布図でクラスタ、外れ値、分布の傾向を確認する。 |
Jupyter Notebookを使えば、セルごとに処理を実行しながら結果を確認できます。PCAの結果を見るときは、変換後の散布図だけでなく、各主成分がどれだけ情報を説明しているかを示す寄与率も確認すると、次元を何個残すべきか判断しやすくなります。
t-SNE・UMAPなどPCA以外の手法
次元削減にはPCA以外にも、t-SNEやUMAPといった手法があります。PCAは線形な関係を捉えるのが得意ですが、データの構造が曲がっていたり、局所的な近さを重視したりしたい場合には、別の手法が合うことがあります。
| 手法 | 特徴 | 向いている用途 |
|---|---|---|
| PCA | 分散の大きい方向を新しい軸にする線形手法。 | 解釈しやすい次元削減、前処理、全体傾向の確認。 |
| t-SNE | 近いデータ同士の関係を2次元で見やすくする非線形手法。 | 複雑なデータのクラスタ可視化。 |
| UMAP | 局所構造を保ちながら、比較的高速に低次元へ写す非線形手法。 | 大きめのデータの可視化、クラスタ探索。 |
t-SNEやUMAPは見た目の分かりやすい散布図を作れる一方で、点と点の距離やクラスタ同士の距離をそのまま厳密に解釈できるとは限りません。可視化はあくまでデータ理解の入口であり、結論を出す前には元データや別の分析結果も確認する必要があります。
次元削減を使うときの注意点
次元削減は便利ですが、万能ではありません。まず、次元を減らすほど情報は失われます。可視化を目的に2次元へ落とす場合と、機械学習モデルの前処理として数十次元を残す場合では、適切な削減の強さが異なります。
次に、PCAを使う場合は標準化を忘れないことが大切です。尺度がそろっていないデータでは、単位の大きい特徴量が主成分を支配し、意図しない結果になることがあります。
また、教師あり学習の前処理で次元削減を使うときは、学習データだけでPCAなどの変換器を学習し、検証データやテストデータには同じ変換を適用します。全データを先に使って変換を学習してしまうと、評価データの情報が学習側に漏れる可能性があります。
次元削減の結果は、データを見るための強力な手がかりです。ただし、可視化されたクラスタが見えたからといって、すぐに因果関係や明確な分類ルールがあると決めつけないようにしましょう。元データの意味、前処理、手法の性質を合わせて確認することが重要です。
まとめ
次元削減とは、多くの特徴量を持つデータを、重要な情報をできるだけ残しながら少ない次元で表現する手法です。高次元データを2次元や3次元に変換すれば、データの分布、クラスタ、外れ値を視覚的に確認しやすくなります。
代表手法のPCAは、データのばらつきが大きい方向を主成分として取り出す方法です。ワインデータのように複数の特徴量を持つデータでは、PCAによって種類ごとのまとまりや特徴の違いを散布図で把握できます。
一方で、次元削減は情報を圧縮する処理なので、目的に合わせた手法選びと結果の読み取りが欠かせません。PCA、t-SNE、UMAPなどの特徴を理解し、可視化、前処理、ノイズ低減といった用途に合わせて使うことが、データ分析や機械学習を進めるうえで重要です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年4月30日 | 次元削減の定義、PCAの仕組み、ワインデータでの可視化例、Python実装の流れ、t-SNE・UMAPとの違いと注意点を初心者向けに再構成 |