アルゴリズム
アルゴリズム オートエンコーダ:データ圧縮と表現学習
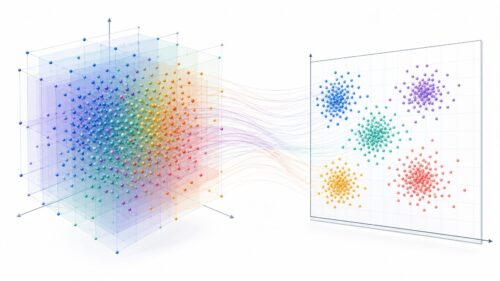
{次元削減とは、データが持つ多くの情報をできるだけ失わずに、データを表す要素の数、つまり次元数を減らす手法のこと}です。
たとえば、顧客一人ひとりの情報を数百もの項目で詳しく記録していたとします。住所や年齢、購入履歴など、項目が多ければ多いほど、その顧客のことをよく理解できるかもしれません。しかし、あまりに項目が多すぎると、顧客全体の特徴を掴むのが難しくなります。まるで木を見て森を見ずの状態です。膨大な数の項目を一つ一つ見ているだけでは、顧客全体の傾向やグループ分けなどは見えてきません。また、項目が多いほど、情報を処理するのに時間も費用もかかってしまいます。そこで、次元削減という手法が役立ちます。
次元削減を使うと、数百もあった項目を、顧客全体の特徴を捉えるのに本当に必要な少数の項目に絞り込むことができます。たとえば、顧客の購買行動を分析するために、購入金額や購入頻度という二つの項目に絞り込むといった具合です。もちろん、項目を絞り込む際に、顧客全体の特徴をできるだけ損なわないように工夫する必要があります。次元削減の手法には様々なものがありますが、どの手法を使うかによって、情報の損失の度合いが変わってきます。
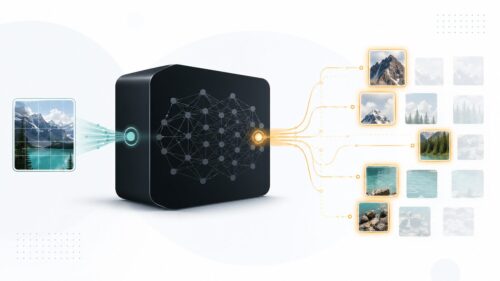
次元削減は、顧客データの分析以外にも、様々な場面で使われています。たとえば、デジタルカメラやスマートフォンで撮影した画像データは、そのままではサイズが大きすぎて保存や転送に時間がかかります。そこで、次元削減を使って画像データのサイズを小さくすることで、画質をあまり落とさずに、必要な容量を減らすことができます。また、工場などで機械の状態を監視するセンサーデータからノイズを取り除いたり、大量の文書データの中から重要なキーワードを抽出したりするのにも、次元削減が役立ちます。このように次元削減は、データ分析を効率化し、様々な分野で役立つ重要な技術と言えるでしょう。