
オートエンコーダで次元削減とは?仕組み・特徴表現・活用例を解説

AIの初心者
オートエンコーダは次元削減に使えると聞きました。どうして情報を減らすと、かえって大事な特徴が見つかるんですか?

AI専門家
次元削減は、たくさんの情報をそのまま持つのではなく、復元や判断に必要な要点を残す作業だと考えるとわかりやすいよ。りんごの絵なら、背景の細部よりも赤い色や丸い形のほうが重要だよね。オートエンコーダも、入力を一度小さな表現に圧縮し、そこから元に戻す練習を通じて、データの本質的な特徴を学習するんだ。
AIの初心者
つまり、ただ情報を捨てるのではなく、復元に必要な情報を選び取るということですか?
AI専門家
その通り。ボトルネックのように狭い層を通すことで、細かなノイズや偶然の違いよりも、共通して役立つ特徴が残りやすくなる。だからオートエンコーダは、次元削減だけでなく、ノイズ除去や異常検知にも応用できるんだ。
オートエンコーダとは。
オートエンコーダは、日本語では自動符号化器とも呼ばれるニューラルネットワークの一種です。入力データをいったん小さな表現へ圧縮し、そこから元のデータを復元するように学習します。この圧縮と復元の過程で、データを説明するうえで重要な特徴を取り出し、次元削減、ノイズ除去、異常検知などに利用できます。

オートエンコーダで次元削減とは
オートエンコーダによる次元削減とは、入力データをより少ない数の特徴量に圧縮し、それでも元のデータをできるだけ復元できるように学習する方法です。画像、音声、文章、購買履歴のようなデータは、多数の値で表されます。すべての値をそのまま扱うと計算が重くなり、重要でない揺らぎやノイズまで学習してしまうことがあります。
次元削減では、データが持つ情報をなるべく保ちながら、扱う軸の数を減らします。たとえば果物の画像を考えると、背景の模様や小さな傷よりも、色、形、大きさ、輪郭のような特徴のほうが種類の判別に役立ちます。オートエンコーダは、このような重要な情報を低次元の表現としてまとめることを目指します。
ここで大切なのは、次元を減らすことが単に情報を乱暴に捨てる作業ではない点です。オートエンコーダは、圧縮した表現から元の入力を復元する課題を解きながら、何を残せば復元しやすいかを学びます。そのため、うまく学習できれば、データの本質に近い特徴を取り出せます。
仕組み:圧縮するエンコーダと復元するデコーダ

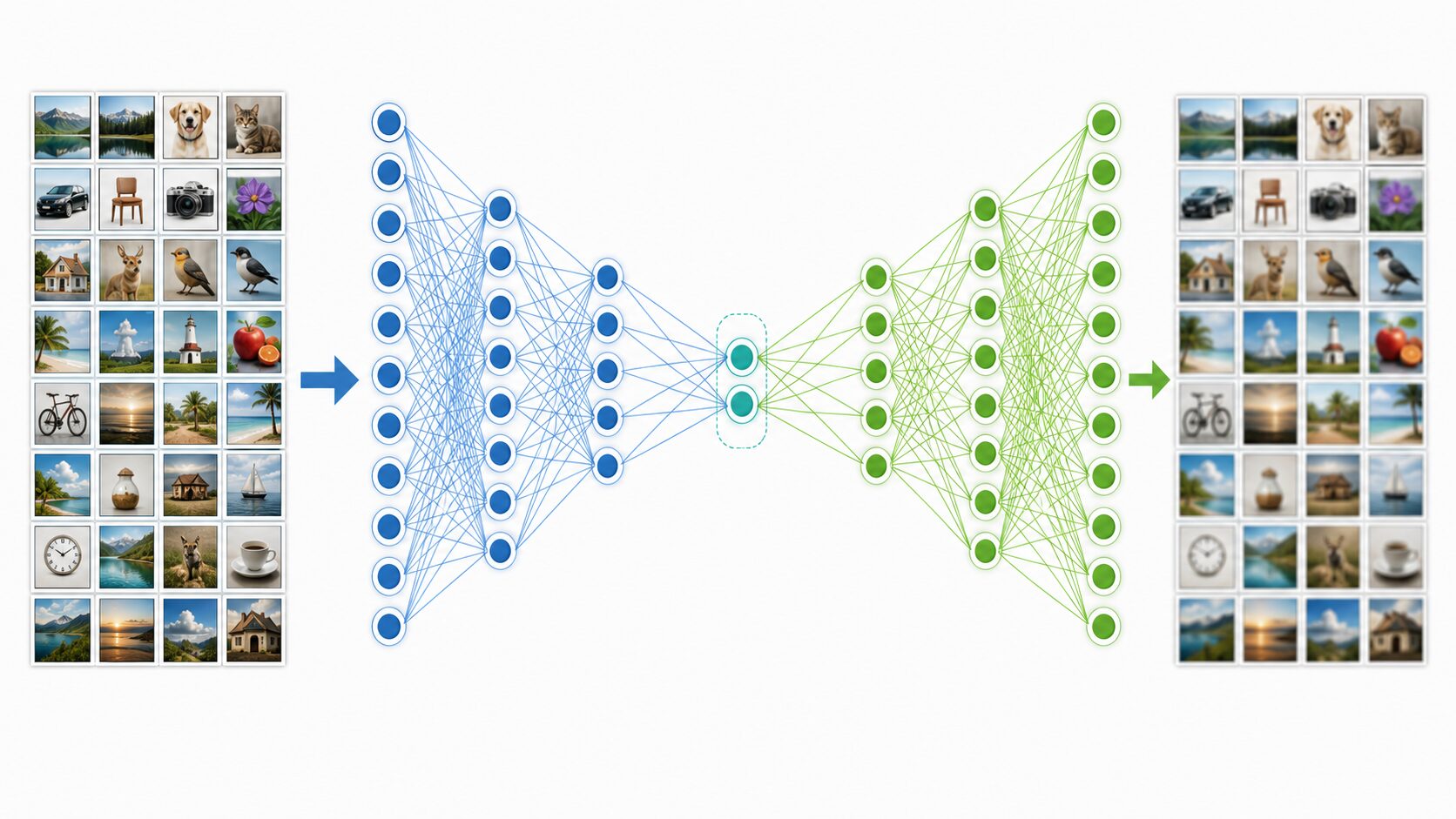
オートエンコーダは、大きく分けるとエンコーダ、潜在表現、デコーダで構成されます。エンコーダは入力を小さな表現へ変換する部分、デコーダはその小さな表現から元の入力に近いデータを再構成する部分です。中央にある小さな表現は、潜在表現、潜在変数、ボトルネック層などと呼ばれます。
学習では、入力と出力ができるだけ近くなるように重みを調整します。たとえば画像を入力した場合、出力画像が元画像に近づくように学習します。このとき中央の層が入力より小さければ、ネットワークはすべての情報を丸写しできません。限られた容量の中に、復元に役立つ情報を詰め込む必要があります。
この制約が、次元削減として働きます。入力が1000個の値で表されるデータだとしても、中央の潜在表現を50個の値にすれば、データは50次元の表現へ圧縮されます。もちろん、中央を狭くしすぎると必要な情報まで失われ、復元結果が悪くなります。反対に広すぎると、単なる丸暗記に近くなり、特徴抽出の効果が弱くなります。
| 構成要素 | 役割 | 初心者向けの見方 |
|---|---|---|
| エンコーダ | 入力データを低次元の表現へ変換する | 情報を要約する部分 |
| 潜在表現 | 圧縮された特徴を保持する | 要点だけを書いたメモ |
| デコーダ | 潜在表現から入力に近いデータを復元する | 要点メモから元の内容を再現する部分 |
| 再構成誤差 | 入力と復元結果の違いを測る | どれくらい元に戻せたかのズレ |
なぜ抽象的な特徴表現が得られるのか
オートエンコーダが抽象的な特徴表現を学びやすい理由は、狭い潜在表現を通しても復元できる情報を優先して残すからです。画像であれば、画素一つひとつの細かな揺らぎよりも、輪郭、色のまとまり、形の配置のような情報が復元に役立つことがあります。文章なら、個々の単語だけでなく、話題や意味のまとまりが重要になる場合があります。
たとえば顔画像を考えると、目や鼻の厳密な位置だけでなく、表情、顔の向き、明るさの傾向なども復元に影響します。オートエンコーダは、このような複数の要素を低次元の潜在表現に押し込むため、結果として「笑顔らしさ」「輪郭の丸さ」「明暗の傾向」のような抽象度の高い特徴を内部で扱うことがあります。
ただし、潜在表現が必ず人間にとってわかりやすい意味を持つとは限りません。モデルにとって復元に役立つ表現と、人間が説明しやすい表現は別物です。そのため実務では、低次元表現を可視化したり、下流タスクで性能を確認したりして、目的に合った特徴が得られているかを確かめます。
次元削減で得られる主な効果
次元削減の代表的な効果は、計算量と保存容量を減らせることです。特徴量の数が少なくなれば、学習や推論で扱う値の数も減ります。大規模な画像データや顧客データを扱う場合、この差は処理時間や必要なメモリに大きく影響します。
もう一つの効果は、データの見通しがよくなることです。高次元データはそのままでは人間が理解しにくいですが、2次元や3次元に近い形へ圧縮できれば、散布図などで全体の傾向を確認しやすくなります。顧客の購買履歴を低次元にまとめれば、似た行動をする顧客グループを見つける手がかりになります。
さらに、不要な情報やノイズの影響を弱められる場合があります。復元に必要な特徴を中心に残すことで、背景の乱れやセンサーの細かな揺らぎが落ち、後続の分類や予測が安定することがあります。ただし、重要な情報まで消してしまう可能性もあるため、圧縮率やモデル構造は目的に合わせて調整する必要があります。
| 効果 | 説明 | 例 |
|---|---|---|
| 計算量の削減 | 扱う特徴量を減らし、学習や推論を軽くする | 画像特徴を低次元にして分類モデルへ渡す |
| 可視化 | 高次元データの分布を見やすくする | 顧客データを散布図で確認する |
| ノイズ低減 | 復元に不要な細かな揺らぎを落とす | 医療画像や古い写真を見やすくする |
| 特徴抽出 | 後続タスクに使いやすい表現を作る | 推薦や異常検知の入力特徴として使う |
ニューラルネットワークと過学習の関係
ニューラルネットワークは、多数の重みを調整しながらデータの特徴を学習します。表現力が高い一方で、学習データに含まれる偶然のパターンやノイズまで覚えてしまうことがあります。これが過学習です。過去問だけを丸暗記して、少し形の違う問題に対応できなくなる状態に似ています。
オートエンコーダのボトルネック層は、入力をそのまま通すのではなく、少ない情報量へ圧縮します。この制約により、細かなノイズをすべて覚えるよりも、復元に共通して役立つ特徴を残す方向に学習が進みやすくなります。その意味で、オートエンコーダは過学習を抑える考え方と相性があります。
ただし、オートエンコーダを使えば必ず過学習が防げるわけではありません。モデルが大きすぎる、学習データが少ない、圧縮が弱い、といった条件では、入力をほぼ丸写しするように学習することもあります。実務では、検証データで再構成誤差を確認し、正則化、ドロップアウト、早期終了なども組み合わせて調整します。
オートエンコーダの代表的な応用例
オートエンコーダは、次元削減だけでなく、圧縮と復元の性質を利用したさまざまな用途に使われます。代表例の一つがノイズ除去です。ノイズを含む画像を入力し、きれいな画像を復元するように学習させると、不要なざらつきや欠損を抑えた出力を得られる場合があります。
異常検知でもよく使われます。正常なデータだけでオートエンコーダを学習させると、正常な入力はうまく復元できます。一方、見慣れない異常データは復元が難しく、入力と出力の差である再構成誤差が大きくなります。この差を利用して、工場の不良品検出、センサー異常、ネットワークの不審な挙動などを検知します。
推薦システムでは、ユーザーの閲覧履歴や購入履歴を圧縮し、隠れた好みを表す特徴として扱うことがあります。単に同じ商品を見たかどうかだけでなく、似た行動パターンやジャンルの好みを低次元表現にまとめることで、関連性の高い商品やコンテンツを提案しやすくなります。
| 応用分野 | 使い方 | 活用例 |
|---|---|---|
| ノイズ除去 | ノイズ入り入力から、きれいなデータを復元する | 古い写真、医療画像、センサーデータの補正 |
| 異常検知 | 再構成誤差が大きいデータを異常候補として見る | 不良品検出、不正アクセス検知、設備監視 |
| 推薦システム | 行動履歴を低次元の好み表現へ圧縮する | ECサイト、動画配信、ニュース推薦 |
PCAなど他の次元削減との違い
次元削減の手法としては、PCA(主成分分析)もよく知られています。PCAは、データのばらつきが大きい方向を見つけ、線形変換によって少数の軸にまとめる方法です。仕組みが比較的シンプルで、結果を解釈しやすい点が強みです。
一方、オートエンコーダはニューラルネットワークを使うため、非線形な関係も表現しやすいのが特徴です。画像や音声のように、単純な直線的関係だけでは説明しにくいデータでは、柔軟な表現を学習できる可能性があります。その反面、モデル設計、学習データ、ハイパーパラメータの影響を受けやすく、結果の解釈も難しくなりがちです。
初心者向けには、まずPCAを「軽くて解釈しやすい基本手法」、オートエンコーダを「学習が必要だが複雑な特徴を捉えやすい手法」と整理すると理解しやすくなります。どちらが常に優れているわけではなく、データの性質、目的、必要な説明可能性によって使い分けます。
使うときの注意点
オートエンコーダを次元削減に使うときは、潜在表現の次元数を慎重に決める必要があります。小さすぎると復元に必要な情報まで失われ、大きすぎると圧縮の意味が薄れます。再構成誤差だけでなく、圧縮した特徴を使った分類、検索、異常検知などの目的タスクで役立つかを確認することが重要です。
また、学習データの偏りにも注意が必要です。正常データだけで学習した異常検知モデルは、正常の範囲をうまく覚えられる一方で、学習データに含まれていない正常パターンを異常と誤判定することがあります。データの収集範囲、前処理、評価方法をそろえなければ、現場で期待した性能が出ないことがあります。
さらに、低次元表現は便利ですが、その各軸が人間にとって明確な意味を持つとは限りません。説明が必要な業務では、可視化、特徴量の確認、シンプルな手法との比較を行い、モデルの判断を過信しない運用が求められます。
まとめ
オートエンコーダで次元削減を行うと、入力データを低次元の潜在表現へ圧縮し、そこから復元する学習を通じて、データの重要な特徴を取り出せます。中央のボトルネック層が、すべてを丸ごと保持するのではなく、復元に必要な情報を残す制約として働く点がポイントです。
この仕組みは、計算量の削減、データの可視化、ノイズ除去、異常検知、推薦システムなどに応用できます。ただし、次元数やモデル構造を誤ると必要な情報を失ったり、逆に丸暗記に近くなったりします。PCAなどの手法とも比較しながら、目的に合った特徴表現が得られているかを評価することが大切です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年1月31日 | 初回公開 |
| 2026年5月27日 | 仕組み、応用例、PCAとの違いを補い構成を調整 |