二乗和誤差とは?意味・計算式・使いどころをわかりやすく解説

AIの初心者
『二乗和誤差』ってなんですか?機械学習でよく出てくるのですが、意味がつかめません。

AI専門家
二乗和誤差は、AIや統計モデルの予測が実際の値からどれくらい外れたかを測る指標だよ。例えば気温を25度と予測して実際は28度だった場合、その差の3度が誤差になるんだ。
AIの初心者
ただ差を足すだけではなく、二乗するのはなぜですか?
AI専門家
差をそのまま足すと、プラスの誤差とマイナスの誤差が打ち消し合うことがある。そこで誤差を二乗してから合計し、予測のずれの大きさを一つの数値で見られるようにするんだ。
二乗和誤差とは。
二乗和誤差は、実際の値と予測した値の差をそれぞれ二乗し、それらをすべて足し合わせたものです。統計学や機械学習では、予測モデルの当たり具合を評価する基本的な指標として使われます。各データの差は「誤差」または「残差」と呼ばれ、二乗するため、実測値から予測値を引いても、予測値から実測値を引いても最終的な値は同じになります。
二乗和誤差とは
二乗和誤差とは、予測値と実測値のずれを二乗して合計した値です。英語では Sum of Squared Errors と呼ばれ、SSE と略されることもあります。
機械学習では、モデルが出した予測がどれだけ現実に近いかを数値で確認する必要があります。例えば、売上を100個と予測したのに実際は110個だった場合、誤差は10です。別のデータで80個と予測して実際は75個だった場合、誤差は5です。このような誤差をデータごとに計算し、二乗して合計したものが二乗和誤差です。
値が小さいほど、予測値と実測値の距離が全体として小さいことを意味します。反対に、値が大きい場合は、どこかで大きく外している、または全体的に予測がずれている可能性があります。そのため二乗和誤差は、回帰分析やニューラルネットワークなどでモデルを評価したり、学習中に改善方向を決めたりするために使われます。
| 項目 | 内容 |
|---|---|
| 意味 | 予測値と実測値の差を二乗して合計した値 |
| 目的 | 予測モデルのずれを一つの数値で評価する |
| 値の見方 | 小さいほど予測と実測の差が小さい |
| 関連語 | 残差、損失関数、回帰分析、平均二乗誤差 |
二乗和誤差の計算式と手順
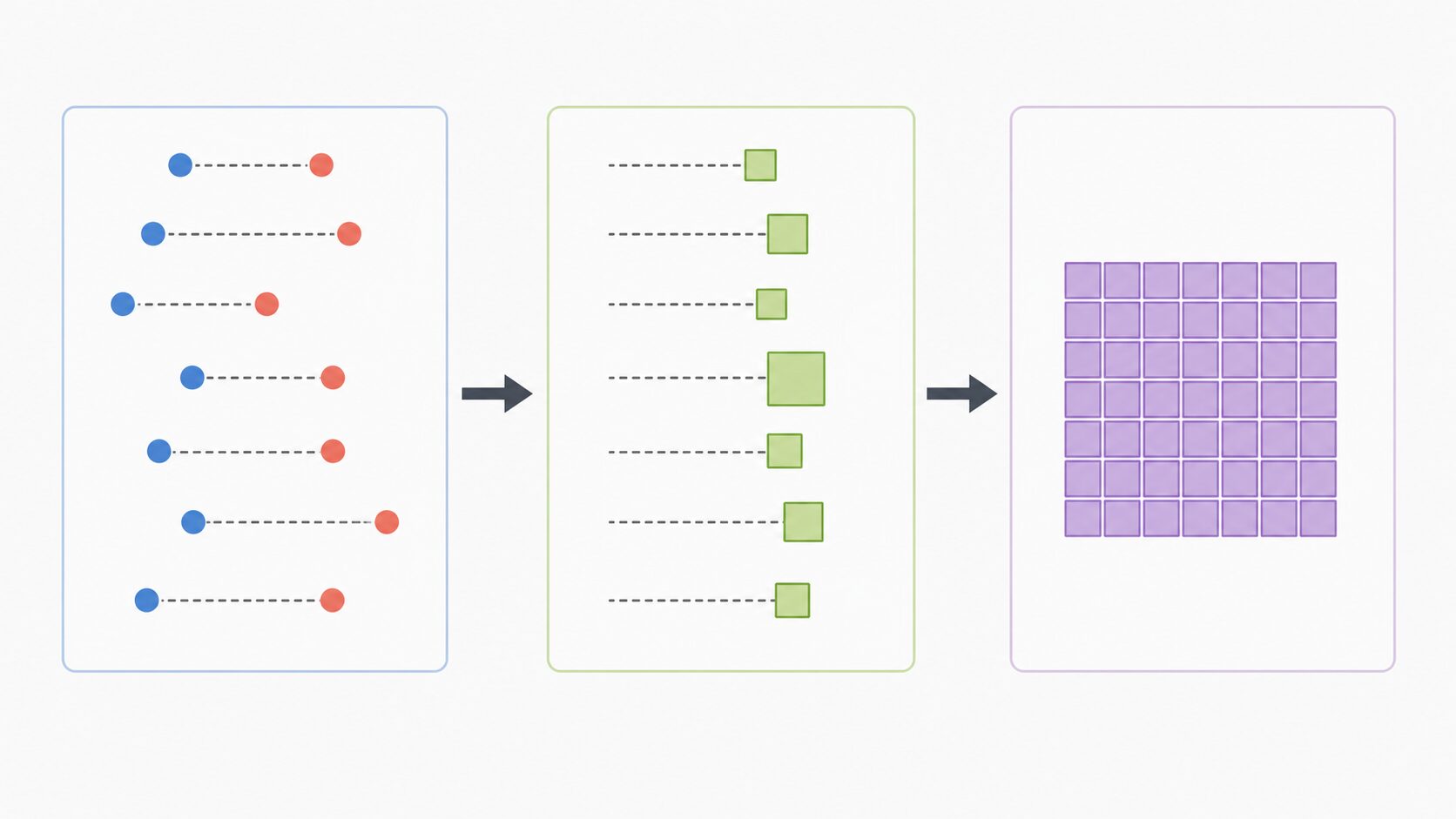
二乗和誤差の計算は、引き算、二乗、足し算の三つで考えられます。数式では、実測値を y、予測値を y のハット、データ数を n とすると、次のように表せます。
\(SSE = \sum_{i=1}^{n}(y_i – \hat{y}_i)^2\)ここで Σ は「すべて足し合わせる」という意味です。各データについて、まず実測値と予測値の差を求めます。次に、その差を二乗します。最後に、二乗した値をすべて合計します。
具体例で確認しましょう。3つのデータについて、実測値が10、20、30、予測値が12、18、33だったとします。誤差は、10 – 12 = -2、20 – 18 = 2、30 – 33 = -3です。これを二乗すると、4、4、9になります。最後に合計して、4 + 4 + 9 = 17です。この場合の二乗和誤差は17です。
実務では、データ数が多いほど二乗和誤差も大きくなりやすい点に注意が必要です。同じモデルでも、100件のデータで計算した値と1万件のデータで計算した値をそのまま比べると、データ数の影響を受けます。データ数が異なる比較では、後述する平均二乗誤差も合わせて見ると判断しやすくなります。
| 手順 | 行うこと |
|---|---|
| 1 | 各データで実測値と予測値の差を求める |
| 2 | 差を二乗して、すべて正の値として扱う |
| 3 | 二乗した値をすべて合計する |
なぜ誤差を二乗するのか
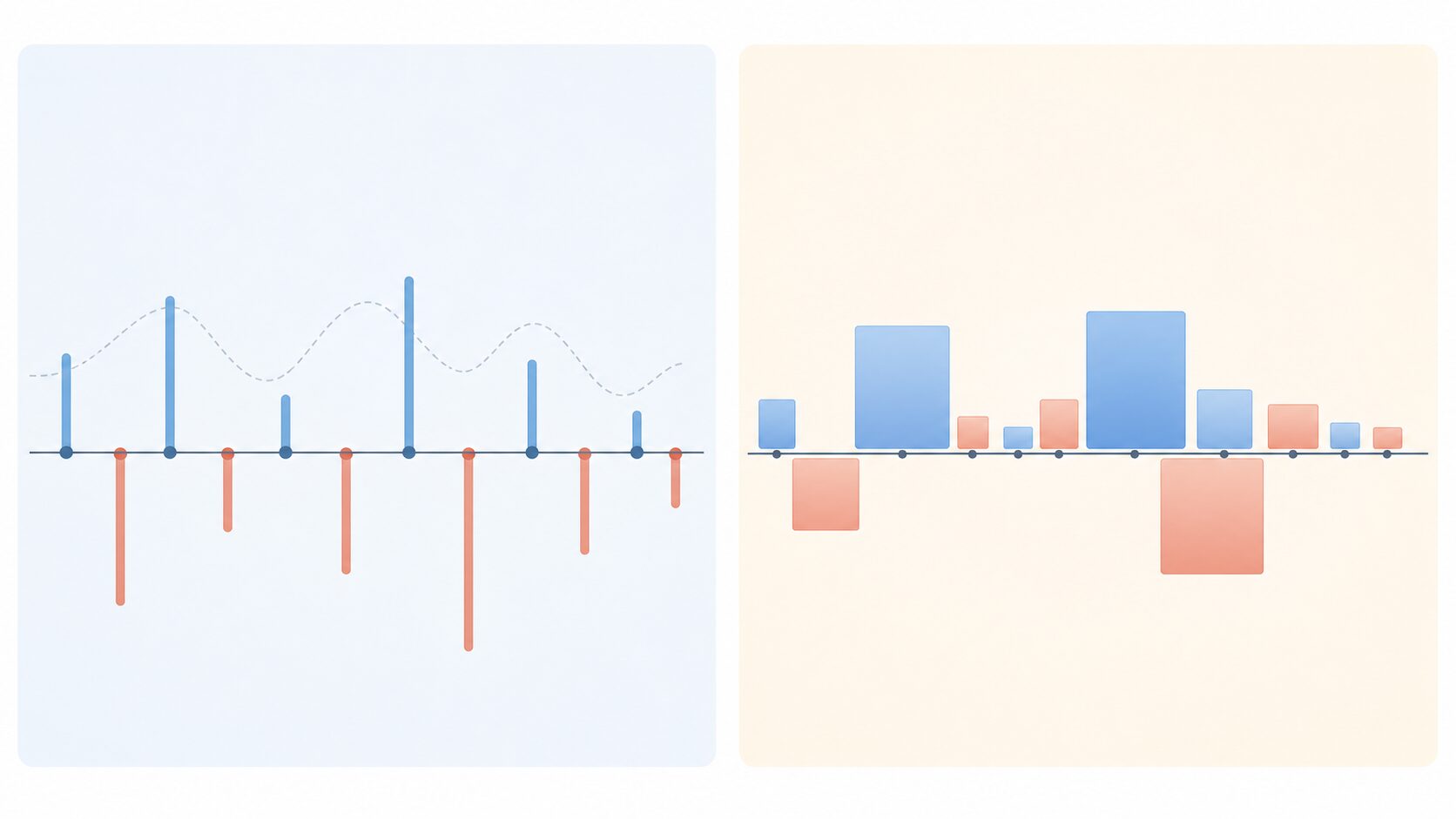
誤差を二乗する主な理由は二つあります。一つ目は、プラスの誤差とマイナスの誤差が打ち消し合うのを防ぐためです。予測が実測値より大きい場合と小さい場合をそのまま足すと、実際には外れているのに合計が小さく見えることがあります。
例えば、ある製品の長さの誤差が +5mm、-3mm、+2mm、-4mm、+1mm だったとします。単純に足すと合計は +1mm です。一見するとほとんど誤差がないように見えますが、個別には5mmや4mmのずれがあります。これらを二乗すると、25、9、4、16、1となり、合計は55です。単純な合計よりも、実際のずれの大きさを反映しやすくなります。
二つ目は、大きな誤差をより重く扱えるためです。誤差が2なら二乗後は4ですが、誤差が10なら二乗後は100になります。つまり、少しのずれよりも大きな外れを強く罰する性質があります。これは、重大な予測ミスを避けたい場面では有効です。
ただし、この性質は長所であると同時に短所にもなります。外れ値が一つあるだけで二乗和誤差が大きく動くため、データに異常値や測定ミスが混ざっている場合は、二乗和誤差だけで判断しないことが大切です。
機械学習での使いどころ
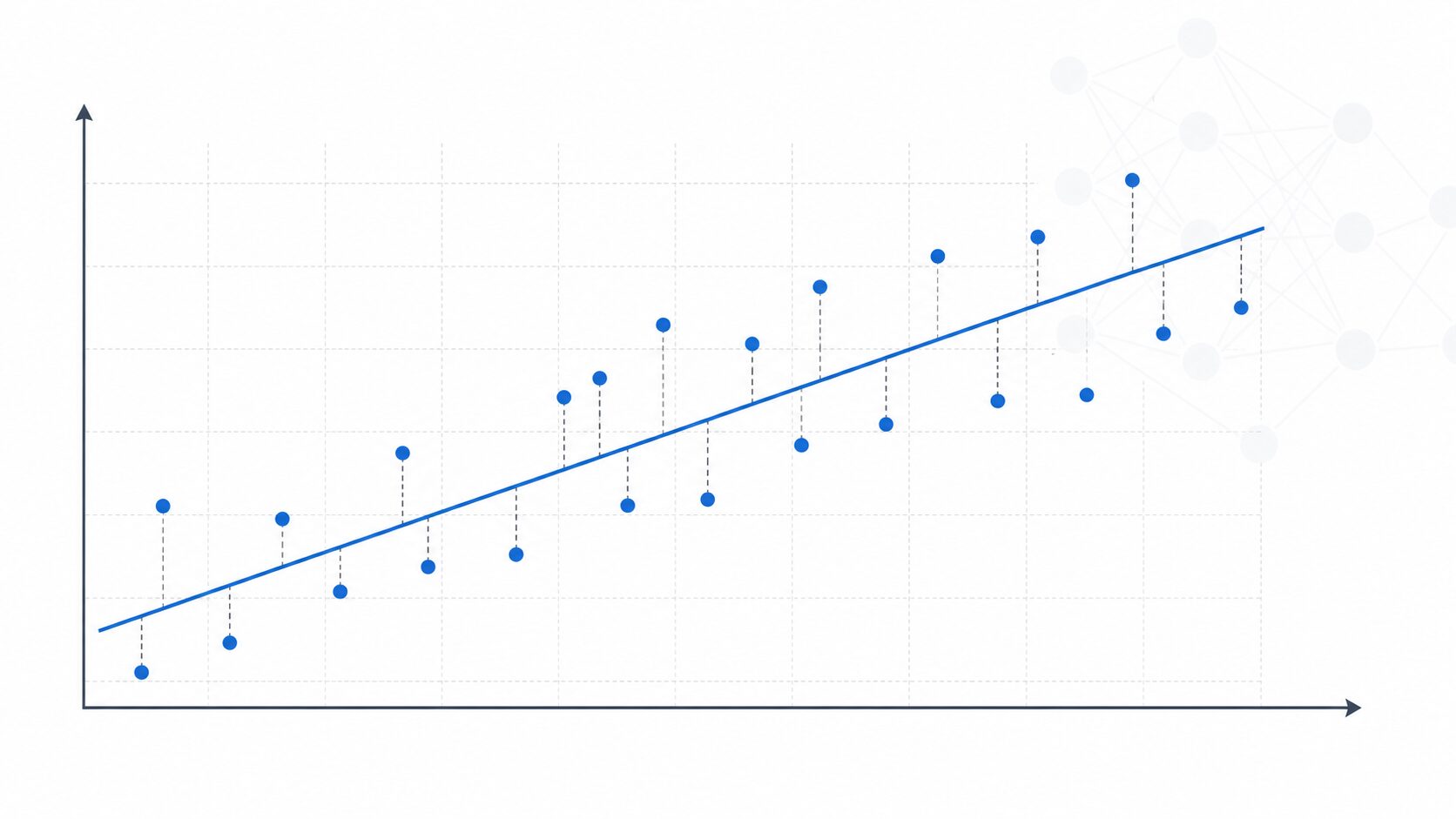
二乗和誤差は、特に回帰分析でよく使われます。回帰分析は、売上、気温、需要、価格のような連続した数値を予測するための方法です。線形回帰では、データ点に最もよく合う直線を探します。この「よく合う」を数値化する基準として、二乗和誤差が使われます。
直線から各データ点までの縦方向のずれを残差と考え、それぞれを二乗して合計します。その合計が最も小さくなる直線を選ぶと、全体としてデータに近いモデルを得やすくなります。これが最小二乗法の基本的な考え方です。
ニューラルネットワークでも、予測値と正解値のずれを表す損失関数として、二乗誤差や平均二乗誤差が使われることがあります。学習では、損失関数の値が小さくなるようにパラメータを少しずつ調整します。つまり二乗和誤差は、モデルを評価するだけでなく、学習の方向を決める手がかりにもなります。
一方で、すべての問題に二乗和誤差が向いているわけではありません。分類問題では交差エントロピーのような別の損失関数がよく使われます。また、外れ値が多い回帰問題では、平均絶対誤差のほうが目的に合う場合もあります。
他の誤差指標との違い
モデル評価では、二乗和誤差だけでなく、平均二乗誤差や平均絶対誤差もよく使われます。名前が似ているため混同しやすいですが、見ている性質は少し異なります。
平均二乗誤差は、二乗和誤差をデータ数で割ったものです。データ数の影響をならすため、異なるデータ数の評価を比べたいときに使いやすくなります。さらに平均二乗誤差の平方根を取ったものが平方根平均二乗誤差で、元データに近い単位で誤差を見たい場合に使われます。
平均絶対誤差は、誤差の絶対値を平均したものです。誤差を二乗しないため、二乗和誤差や平均二乗誤差ほど外れ値に強く反応しません。極端な値の影響を抑えて、平均的なずれを見たい場合に向いています。
| 指標 | 計算の考え方 | 特徴 | 向いている場面 |
|---|---|---|---|
| 二乗和誤差 | 誤差を二乗して合計 | 大きな誤差を強く反映する | 同じデータ条件でモデルを比べる |
| 平均二乗誤差 | 二乗和誤差をデータ数で割る | データ数の影響をならす | データ数が異なる評価を比べる |
| 平均絶対誤差 | 誤差の絶対値を平均 | 外れ値の影響を受けにくい | 平均的なずれを安定して見たい |
使うときの注意点
二乗和誤差を使うときは、まず単位に注意します。誤差を二乗するため、元のデータが「円」なら二乗後の単位は円の二乗、元のデータが「度」なら度の二乗のようになります。直感的に解釈しにくい場合は、平均二乗誤差や平方根平均二乗誤差も確認すると理解しやすくなります。
次に、外れ値の影響を確認します。大きく外れたデータが一つあると、二乗和誤差は大きく増えます。これは、重大なミスを見逃したくない場面では役立ちますが、測定ミスや一時的な異常値まで強く評価してしまうこともあります。モデルを比較する前に、データの分布や外れ値の理由を確認しておくと判断を誤りにくくなります。
また、二乗和誤差は値が小さいほどよいという見方はできますが、「いくつ以下なら必ず良い」と一律に決められる指標ではありません。扱うデータの単位、データ数、予測対象のばらつきによって値の大きさは変わります。実務では、複数のモデルを同じ条件で比較したり、別の評価指標と組み合わせたりして使うのが現実的です。
まとめ
二乗和誤差は、予測値と実測値の差を二乗して合計する、機械学習と統計の基本的な評価指標です。誤差を二乗することで、正負の誤差の相殺を防ぎ、大きな予測ミスを強く反映できます。
計算手順は、誤差を求める、二乗する、合計する、という流れです。線形回帰では最もデータに合う直線を探す基準として使われ、ニューラルネットワークでも損失関数の考え方と関係します。
一方で、外れ値の影響を受けやすいことや、データ数が違う比較では値の大きさをそのまま比べにくいことには注意が必要です。平均二乗誤差や平均絶対誤差との違いを理解しておくと、目的に合った指標を選びやすくなります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月11日 | 式の読み方、指標比較、外れ値への注意を補って更新 |