F値とは?機械学習モデルの評価指標を初心者向けに解説

AIの初心者
「F値」って、1に近いほど良いと聞きます。どうして1に近いほど良い指標になるんですか?

AI専門家
F値は、適合率と再現率という2つの指標をまとめた値だからだよ。どちらも高いとF値も高くなり、両方が完全なときにだけ1になるんだ。
AIの初心者
適合率と再現率のどちらを重視すればよいのか、いつも迷ってしまいます。
AI専門家
そこでF値が役立つんだ。たとえば病気の検査なら、陽性と判定した人が本当に病気だった割合と、病気の人をどれだけ見つけられたかの両方が大切になるよね。
F値とは。
F値は、機械学習や情報検索で使われる評価指標のひとつです。分類モデルが「どれだけ正確に当てたか」と「どれだけ見逃さずに拾えたか」を同時に見るために使われ、特に正解データが偏っている場面で重要になります。
F値とは?適合率と再現率のバランスを見る指標
F値とは、適合率と再現率を調和平均でまとめた機械学習モデルの評価指標です。英語では F-measure と呼ばれ、適合率と再現率を同じ重みで扱う場合はF1スコア、F1-score とも呼ばれます。
機械学習の分類モデルは、入力データに対して「正例か、負例か」のような予測を行います。たとえば、メールを「迷惑メール」か「通常メール」かに分けたり、検査画像を「病気の疑いあり」か「疑いなし」かに分けたりします。このとき単に当たった数だけを見ると、見逃しや誤検出の問題が隠れてしまうことがあります。
そこで使うのが、適合率と再現率です。適合率は「モデルが正例と判断したもののうち、実際に正例だった割合」、再現率は「実際の正例のうち、モデルが正例として見つけられた割合」です。F値はこの2つを1つの数値にまとめることで、正確さと見逃しにくさのバランスを確認しやすくします。
正解率だけでは不十分な場面では、F値が特に役立ちます。たとえば全体の99%が正常データで、異常データが1%しかない場合、すべてを正常と予測しても正解率は高く見えます。しかし異常をまったく検出できないため、実務上は役に立たないモデルです。F値は、こうした偏りのあるデータでモデルの弱点を見つける助けになります。
| 指標 | 見るもの | 直感的な意味 |
|---|---|---|
| 適合率 | 予測した正例の中で、本当に正例だった割合 | 誤って拾っていないか |
| 再現率 | 実際の正例の中で、正しく見つけられた割合 | 見逃していないか |
| F値 | 適合率と再現率の調和平均 | 両方のバランスが取れているか |
適合率と再現率を初心者向けに整理
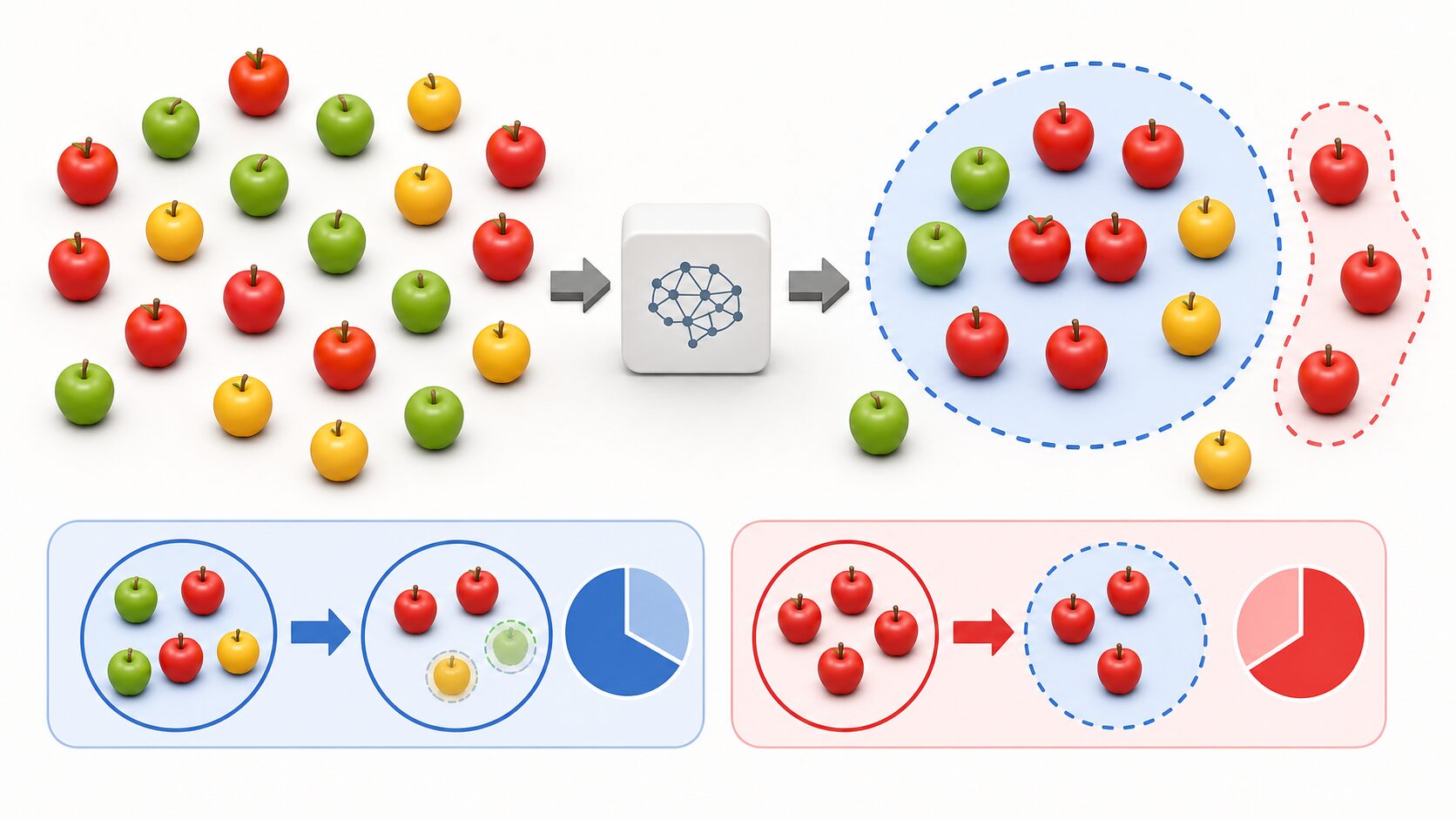
F値を理解するには、まず適合率と再現率を分けて考えると分かりやすくなります。例として、10個のリンゴの中から赤いリンゴを見つけるモデルを考えます。モデルが7個を「赤いリンゴ」として選び、そのうち5個が本当に赤いリンゴだった場合、適合率は5/7です。
一方、実際には赤いリンゴが全部で8個あり、そのうちモデルが5個を見つけられたとします。この場合、再現率は5/8です。つまり適合率は「選んだものの正しさ」、再現率は「本当に見つけるべきものをどれだけ拾えたか」を表します。
機械学習では、誤りを偽陽性と偽陰性に分けて考えることもあります。偽陽性は、本当は違うのに正例だと判断する誤りです。迷惑メール判定なら、通常メールを迷惑メールに入れてしまうことです。偽陰性は、本当は正例なのに見逃す誤りです。迷惑メールを通常メールとして通してしまうことがこれに当たります。
この2つの誤りのどちらが問題になるかは、用途によって変わります。医療診断では病気の見逃しを避けるため再現率を重視することが多く、迷惑メール判定では重要なメールを誤って迷惑メール扱いしないため適合率も重要になります。F値は、こうした2つの観点をまとめて把握したいときに使います。
| 用語 | 意味 | 例 |
|---|---|---|
| 真陽性 | 正例を正例と予測できた | 迷惑メールを迷惑メールと判定 |
| 偽陽性 | 負例を正例と誤って予測した | 通常メールを迷惑メールと判定 |
| 偽陰性 | 正例を負例と誤って予測した | 迷惑メールを通常メールと判定 |
F値の計算方法と調和平均を使う理由

F値は、適合率と再現率の調和平均で計算します。適合率を P、再現率を R とすると、F値の代表的な計算式は次の通りです。
\(F1 = 2 \times \frac{P \times R}{P + R}\)先ほどのリンゴの例では、適合率が5/7、再現率が5/8でした。この値を式に入れると、F値はおよそ0.665になります。1に近いほど良い指標なので、このモデルは一定の性能があるものの、まだ見逃しや誤検出を減らす余地があると読めます。
\(F1 = 2 \times \frac{\frac{5}{7} \times \frac{5}{8}}{\frac{5}{7} + \frac{5}{8}} \approx 0.665\)調和平均を使う理由は、どちらか一方だけが高いモデルを過大評価しにくくするためです。たとえば適合率が1.0で再現率が0.0の場合、算術平均なら0.5になります。しかし実際には、正例をまったく見つけられていないため、良いモデルとは言えません。F値ではこの場合0になります。
この性質により、F値は適合率と再現率の片方だけを極端に改善しても高くなりにくい指標です。分類モデルを改善するときは、F値を見ながら「誤検出を減らす改善なのか」「見逃しを減らす改善なのか」を合わせて確認すると、モデルの挙動を理解しやすくなります。
| 適合率 | 再現率 | F値の読み方 |
|---|---|---|
| 高い | 高い | 正確で見逃しも少ない |
| 高い | 低い | 厳しく選びすぎて見逃しが多い |
| 低い | 高い | 広く拾うが誤検出が多い |
| 低い | 低い | 分類性能が低い |
F値の範囲と理想値
F値は0から1までの値を取ります。1に近いほど、適合率と再現率の両方が高く、バランスの良いモデルだと判断できます。F値が1になるのは、正例と予測したものがすべて正しく、さらに実際の正例をすべて見つけられている状態です。
ただし、現実のデータでF値が完全に1になることは多くありません。データにはノイズが含まれ、正解ラベルに揺れがあり、正例と負例の境界があいまいなこともあります。そのため、F値は「1でなければ悪い」と見るのではなく、用途、リスク、比較対象のモデル、データの難しさと一緒に解釈します。
また、適合率と再現率はしばしばトレードオフの関係になります。病気の検査で判定基準を緩くすれば、病気の人を見つけやすくなり再現率は上がりますが、健康な人を陽性と判定する誤りも増え、適合率が下がる可能性があります。逆に判定基準を厳しくすれば、誤検出は減っても見逃しが増えることがあります。
F値は、このような調整の結果を1つの目安として比較するために便利です。複数のモデルやしきい値を比較するとき、F値が高い組み合わせは、適合率と再現率のバランスが比較的良い候補だと考えられます。
F値が役立つ活用例
F値は、正例を見つけることが重要で、なおかつ誤検出も無視できない場面でよく使われます。代表例は迷惑メール判定です。迷惑メールを見逃すとユーザーに被害が出ますが、通常メールを迷惑メールに入れてしまうと重要な連絡を失う可能性があります。F値は、この両方の問題をまとめて評価する助けになります。
医療画像診断でも、F値はモデルの評価に使われます。病気を見逃す偽陰性は重大なリスクですが、健康な人を病気と判定する偽陽性も追加検査や不安につながります。実際の運用では再現率をより重視する場合もありますが、F値を見ることで全体のバランスを確認できます。
不正検知では、不正取引を見逃さないことと、正常な取引を不正扱いしすぎないことの両方が求められます。商品推薦では、ユーザーが関心を持つ商品を見逃さず、関心の薄い商品を大量に出さないことが重要です。このように、F値は「拾うべきものを拾いながら、余計なものを拾いすぎない」性能を見たいときに有効です。
| 分野 | 避けたい偽陰性 | 避けたい偽陽性 |
|---|---|---|
| 迷惑メール判定 | 迷惑メールを見逃す | 通常メールを迷惑メールにする |
| 医療診断 | 病気を見逃す | 健康な人を病気と判定する |
| 不正検知 | 不正取引を見逃す | 正常取引を止める |
| 商品推薦 | 興味のある商品を出せない | 興味の薄い商品を薦めすぎる |
F値を見るときの注意点
F値は便利な指標ですが、F値だけでモデルの良し悪しを決めるのは危険です。モデル評価では、正解率、適合率、再現率、AUC、混同行列、業務上のコストを合わせて見る必要があります。特にデータが偏っている場合、どのクラスを正例として評価しているのかを確認しないと、数字の意味を取り違えることがあります。
正解率は全体の予測がどれだけ当たったかを見る指標です。一方、F値は特定の正例をどれだけうまく見つけたかに注目します。そのため、不均衡データではF値のほうが実態をつかみやすいことがありますが、すべての場面でF値が最適というわけではありません。
また、F1スコアは適合率と再現率を同じ重みで扱います。しかし実務では、見逃しのコストが誤検出より大きい場合や、その逆の場合があります。再現率をより重視したいときはF2スコア、適合率をより重視したいときはF0.5スコアのように、Fβスコアを使うこともあります。
重要なのは、先に「何を失敗とみなすのか」を決めることです。病気の見逃しを減らしたいのか、誤検出による確認作業を減らしたいのかによって、見るべき指標やしきい値の調整方針は変わります。F値はその判断材料のひとつとして使うと、モデル改善に役立ちます。
まとめ
F値は、適合率と再現率を調和平均でまとめた、機械学習モデルの重要な評価指標です。1に近いほど、正例を正確に見つけ、かつ見逃しも少ないモデルだと考えられます。
特に、迷惑メール判定、医療診断、不正検知、商品推薦のように、偽陽性と偽陰性の両方を考えたい場面でF値は役立ちます。正解率だけでは良く見えてしまう不均衡データでも、F値を見ることでモデルの弱点を把握しやすくなります。
ただし、F値は万能ではありません。評価の目的に応じて、正解率、AUC、混同行列、適合率、再現率、Fβスコアなども合わせて確認しましょう。F値を正しく理解すると、機械学習モデルをより納得感のある形で比較・改善できるようになります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月4日 | F値の定義、適合率・再現率との関係、計算方法、活用例、注意点を初心者向けに再構成 |