
スタック領域とは?メモリの仕組みとヒープ領域との違いを解説

AIの初心者
『スタック領域』って、どういう意味ですか?メモリの話になると急に難しく感じます。

AI専門家
スタックは、お皿を上に積み重ねる様子で考えると分かりやすいです。最後に置いたお皿を最初に取るように、スタック領域では後から入ったデータを先に取り出します。
AIの初心者
最後に入れたデータから使うんですね。それはプログラムのどんな場面で役に立つんですか?
AI専門家
主に関数を呼び出すときに使われます。関数で使う一時的な値や戻り先の情報を積んでおき、処理が終わったら上から順に片づけるので、実行の流れを自然に管理できます。
スタック領域とは。
スタック領域は、プログラムの実行中に必要になる一時的な情報を置くメモリ領域です。特徴は、データを入れた順番と取り出す順番が逆になることです。たとえば、リンゴ、ミカン、バナナの順に積むと、取り出すときはバナナ、ミカン、リンゴの順になります。この「後から入れたものを先に出す」仕組みが、関数呼び出しやローカル変数の管理に向いています。

スタック領域とは?メモリ上の一時置き場
コンピュータでプログラムを動かすとき、数値、文字列、計算途中の結果、関数から戻るための情報などは、どこかのメモリ領域に置かれます。その中でもスタック領域は、短い時間だけ必要になる情報を自動的に管理するための領域です。
代表的な用途は、関数の中で宣言したローカル変数、関数の引数、関数を呼び出した場所へ戻るための情報です。これらは、関数の処理中には必要ですが、関数が終われば不要になります。スタック領域は、このような「使い終わったらすぐ片づけられる情報」を扱うのに向いています。
スタック領域を理解すると、プログラムが関数をどの順番で実行し、なぜローカル変数が関数の外から使えないのか、なぜ深い再帰でエラーが起きるのかが見えやすくなります。メモリ管理の細かい実装は言語や環境によって異なりますが、基本的な考え方は多くのプログラミング言語に共通しています。
| 項目 | 内容 |
|---|---|
| 主な役割 | 一時的なデータ、関数呼び出し、戻り先、ローカル変数の管理 |
| 管理方法 | 後入れ先出し(LIFO) |
| 得意なデータ | 小さく、寿命が短く、処理の流れに沿って使い終わるデータ |
| 注意点 | 容量に限りがあり、深い再帰や大きなローカル配列で不足することがある |
後入れ先出し(LIFO)で動く基本構造
スタック領域の基本は、最後に入れたデータを最初に取り出す「後入れ先出し」です。英語では Last In, First Out といい、略して LIFO と呼ばれます。データを積む操作は push、取り出す操作は pop と表現されることもあります。
皿を積み重ねる例で考えると、下にある皿を先に取るには、上の皿をどかさなければなりません。スタック領域も同じで、基本的には一番上にある情報から順番に取り出します。この制約があるからこそ、データの置き場所を探し回る必要が少なく、処理を単純にしやすいのです。
計算の途中結果を一時的に保存するときにも、この考え方は役立ちます。まず必要な値を順に積み、次に必要なものから取り出して処理し、結果をまた上に置く。こうした流れは、複雑な処理を小さな手順へ分けて実行するプログラムと相性がよい仕組みです。
関数呼び出しでスタック領域が使われる流れ

スタック領域が特に重要になるのは、関数を呼び出す場面です。関数が呼び出されると、その関数で使うローカル変数、引数、戻り先などの情報がまとめて積まれます。このまとまりは、一般にスタックフレームと呼ばれます。
たとえば、関数Aの中で関数Bを呼び、関数Bの中で関数Cを呼ぶとします。このときスタック領域には、Aの情報の上にBの情報が積まれ、さらにその上にCの情報が積まれます。処理が終わる順番は逆で、まずCの情報が取り除かれ、次にB、最後にAへ戻ります。
この仕組みによって、プログラムは「今どの関数を実行しているか」「処理が終わったらどこへ戻るか」を管理できます。関数内のローカル変数が、関数の終了後に使えなくなるのも、対応するスタックフレームが取り除かれるためです。
スタック領域の利点
スタック領域の大きな利点は、メモリの確保と解放が処理の流れに沿って自動的に行われることです。関数が始まると必要な領域が用意され、関数が終わるとその領域が片づけられます。開発者が毎回「ここで確保して、ここで解放する」と細かく指示しなくてもよい場面が多いため、扱いやすい領域です。
また、スタック領域はデータの出し入れが単純です。上に積む、上から外す、という決まった流れで管理できるため、一時的なデータを高速に扱いやすいという特徴があります。頻繁に呼び出される関数や、小さなローカル変数の管理に適しているのはこのためです。
手動管理が必要な領域では、解放し忘れによるメモリリークや、解放済み領域へのアクセスといった不具合が起きることがあります。スタック領域では、関数の終了とともに対応する領域が外れるため、こうした問題を避けやすくなります。ただし、これは「スタック領域ならどんな使い方でも安全」という意味ではありません。容量制限を意識する必要があります。
| 利点 | 説明 |
|---|---|
| 自動的に管理される | 関数の開始と終了に合わせて、必要な領域の確保と解放が行われる |
| 処理が速い | 上から積んで上から外す単純な操作で扱えるため、探索や管理の負担が少ない |
| 短命なデータに向く | ローカル変数や計算途中の値など、関数の中だけで使う情報を管理しやすい |
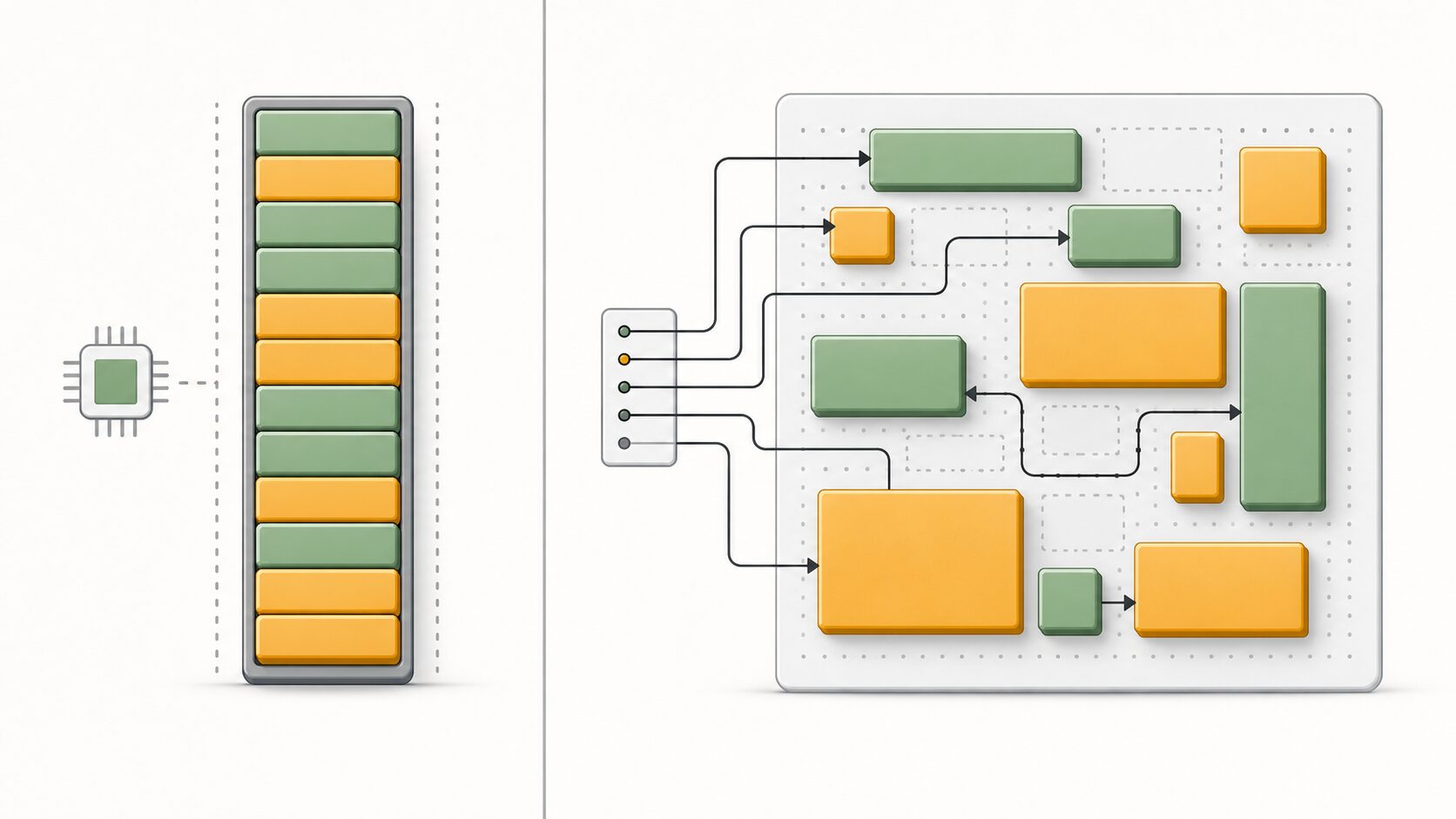
スタック領域の注意点とスタックオーバーフロー
スタック領域には、あらかじめ使える容量の上限があります。そのため、必要な情報を積み続けて上限を超えると、スタックオーバーフローが発生します。スタックオーバーフローは、プログラムの異常終了や予期しない動作につながる重要なエラーです。
よくある原因の一つは、再帰呼び出しが深くなりすぎることです。再帰とは、関数が自分自身を呼び出す書き方です。終了条件が間違っていると関数呼び出しが止まらず、呼び出しのたびに新しいスタックフレームが積まれていきます。結果として、スタック領域が足りなくなります。
もう一つの注意点は、大きなデータをローカル変数として置くことです。小さな数値や短い一時データなら問題になりにくいですが、大きな配列や巨大な構造体をスタック領域に置くと、すぐに容量を圧迫する場合があります。大量のデータ、サイズが実行時に変わるデータ、長く保持したいデータは、ヒープ領域など別の管理方法を検討します。
| 原因 | 対策 |
|---|---|
| 再帰呼び出しが深すぎる | 終了条件を明確にし、必要に応じてループ処理へ置き換える |
| 大きなローカル配列を作る | ヒープ領域や動的確保、外部バッファの利用を検討する |
| 関数呼び出しの入れ子が過度に深い | 処理を整理し、呼び出し階層を浅くできないか見直す |
ヒープ領域との違い

メモリ領域を理解するとき、スタック領域と一緒に出てくるのがヒープ領域です。スタック領域は、関数の実行順に沿って自動的に積み上げ、終わったものから外す領域です。一方、ヒープ領域は、プログラムの実行中に必要な大きさを確保し、必要がなくなったタイミングで解放するための領域です。
スタック領域は、管理が単純で高速ですが、容量が限られ、データの寿命も関数の実行範囲に結びつきやすいという特徴があります。ヒープ領域は、大きなデータや可変長のデータ、関数をまたいで長く使うデータに向いています。ただし、言語によっては確保と解放を開発者が意識する必要があり、メモリリークなどの問題に注意しなければなりません。
たとえば、関数内で一時的に使うカウンタや小さな計算結果はスタック領域に向いています。一方、画像データ、大きなリスト、実行中にサイズが変わるデータ構造は、ヒープ領域に置かれることが多くなります。どちらが優れているかではなく、データの大きさ、寿命、管理方法に合わせて使い分けることが重要です。
| 項目 | スタック領域 | ヒープ領域 |
|---|---|---|
| 管理方法 | 関数呼び出しに合わせて自動的に管理される | 必要なときに確保し、不要になったら解放する |
| データの出し入れ | 後入れ先出し(LIFO) | 比較的自由 |
| 向いているデータ | 小さく短命なデータ、ローカル変数、戻り先情報 | 大きいデータ、可変長データ、長く保持するデータ |
| 注意点 | 容量制限、スタックオーバーフロー | メモリリーク、断片化、管理コスト |
学習時に押さえたい使い分け
初心者がまず押さえたいのは、「ローカル変数だから必ずスタック」「オブジェクトだから必ずヒープ」と単純に決めつけすぎないことです。実際の配置は言語、処理系、最適化、実行環境によって変わることがあります。ただし、考え方としては、短い範囲で使い終わる小さなデータはスタック領域、大きいデータや長く保持するデータはヒープ領域、という整理が役立ちます。
CやC++のようにメモリ管理を強く意識する言語では、スタック領域とヒープ領域の違いがバグの原因に直結します。Java、Python、JavaScriptのように実行環境が多くを管理する言語でも、関数呼び出しの深さや再帰の限界を理解するうえでスタック領域の知識は有効です。
実務や学習では、エラー名としての「stack overflow」を見たときに、まず再帰の終了条件、呼び出し階層、大きなローカルデータを疑うと原因を追いやすくなります。メモリの仕組みを細部まで暗記するより、どの情報がいつ必要になり、いつ不要になるのかを考えることが大切です。
まとめ
スタック領域は、プログラム実行中の一時的な情報を管理するためのメモリ領域です。後から入れたデータを先に取り出す後入れ先出し(LIFO)の仕組みによって、関数呼び出し、ローカル変数、戻り先情報を効率よく扱えます。
利点は、管理が自動的で処理が速く、短命なデータに向いていることです。一方で、容量には上限があり、深すぎる再帰や大きなローカル配列はスタックオーバーフローの原因になります。便利な領域だからこそ、何でも置けばよいわけではありません。
ヒープ領域は、大きなデータや実行中にサイズが変わるデータを扱うときに重要です。スタック領域とヒープ領域の違いを理解しておくと、プログラムの動作、エラーの原因、メモリ管理の考え方をより具体的に理解できます。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月2日 | 初回公開 |
| 2026年5月21日 | LIFO、関数呼び出し、ヒープ比較の説明を補強 |