SegNetとは?画像分割の仕組みと活用例をわかりやすく解説

AIの初心者
『SegNet』って画像分割でよく出てきますが、どんな技術なんですか?

AI専門家
SegNetは、画像を細かい領域に分けて、それぞれが道路、人、車、建物などのどれに当たるかを画素単位で判断する深層学習モデルだよ。
AIの初心者
普通の画像認識とは何が違うんですか?
AI専門家
画像全体に1つの名前を付けるのではなく、画像内の一つひとつの画素にラベルを付ける点が違うんだ。SegNetは特徴を抜き出すエンコーダーと、元の大きさへ戻して分類結果を作るデコーダーで構成されているよ。
SegNetとは。
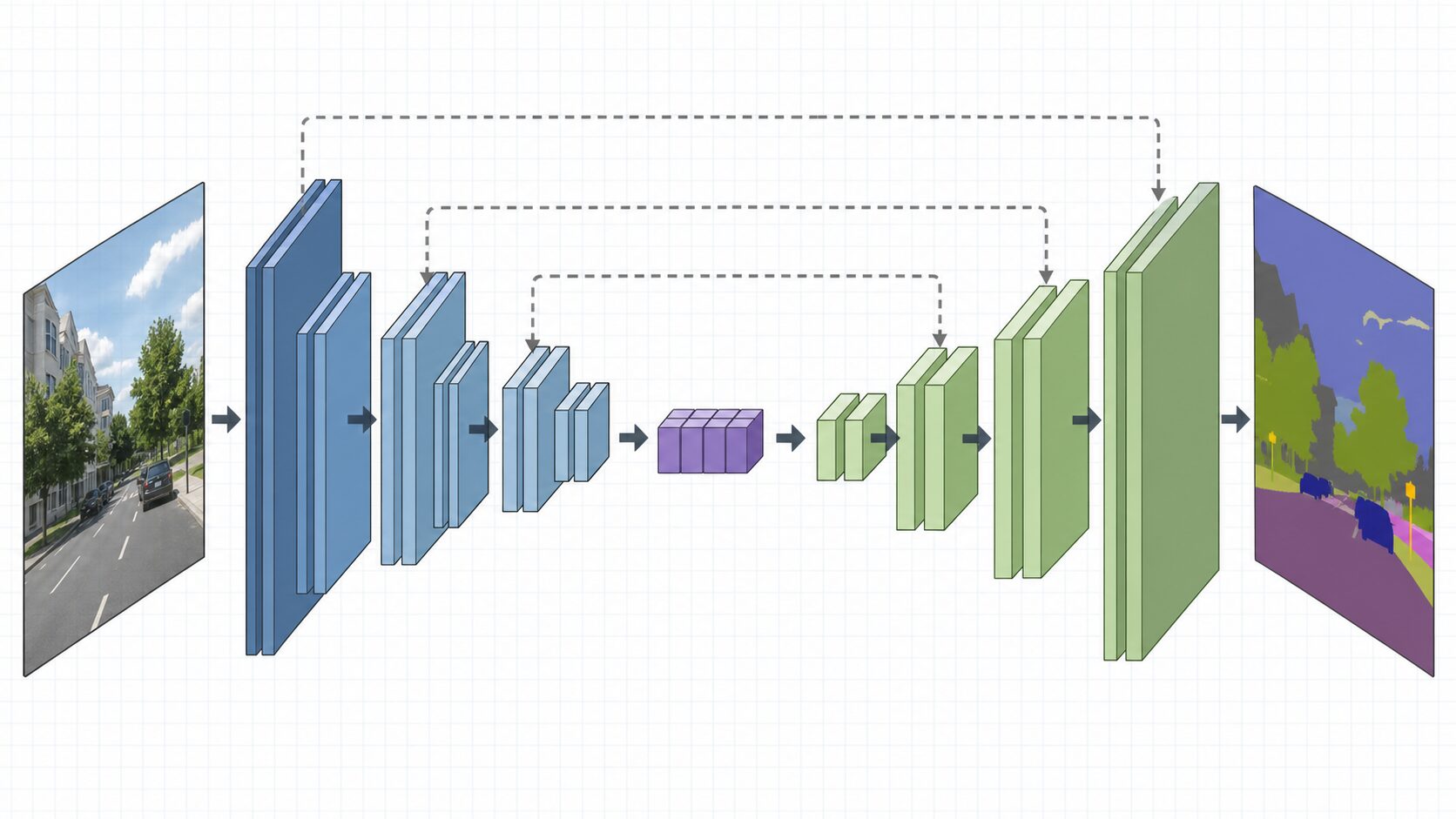
SegNetは、深層学習を使って画像を画素単位で分類するセマンティックセグメンテーションの代表的な手法です。入力画像から特徴を取り出すエンコーダーと、その特徴を元の解像度へ戻して分類地図を作るデコーダーを組み合わせ、画像のどこが道路で、どこが歩行者で、どこが建物なのかを細かく推定します。
SegNetとは?画像分割を画素単位で行う仕組み
SegNetを理解するには、まず画像分割は「画像の中身を場所ごとに分類する処理」だと押さえると分かりやすくなります。一般的な画像分類では、写真全体に「犬」「車」「料理」のようなラベルを付けます。一方、セマンティックセグメンテーションでは、画像を構成する画素ごとに「道路」「空」「人」「車」などの意味を割り当てます。
SegNetはこのセマンティックセグメンテーションを行うニューラルネットワークです。たとえば道路の画像を入力すると、画像全体を見ながら、道路、歩道、車両、歩行者、標識、建物といった領域を色分けしたような分類マップを出力します。単に「車が写っている」と答えるのではなく、車が画像内のどの範囲にあるかまで推定する点が重要です。
物体検出との違いもよく混同されます。物体検出は対象物を四角い枠で囲むのに対し、画像分割は対象物の形に沿って画素単位で分類します。医療画像の病変領域や、自動運転における走行可能領域のように、境界や面積を細かく知りたい場面では、SegNetのような画像分割モデルが役立ちます。
SegNetの全体像:エンコーダーとデコーダーで分類地図を作る

SegNetの構造は、大きくエンコーダーとデコーダーに分けられます。エンコーダーは入力画像から重要な特徴を抽出し、画像の情報を段階的に圧縮します。デコーダーは圧縮された特徴マップを受け取り、元の画像サイズに近い解像度へ戻しながら、各画素のクラスを予測します。
この流れは、画像を一度「要点メモ」にまとめてから、そのメモを使って「どの場所が何に当たるか」を復元する作業に似ています。エンコーダー側では線、角、模様、部品、物体のまとまりといった抽象度の高い特徴が作られます。デコーダー側では、それらの特徴を使って、元画像上の位置に対応する分類結果へ変換します。
SegNetの特徴は、単に縮小と拡大を行うだけではありません。エンコーダーで最大プーリングを行うときに、どの位置の値が選ばれたかを記録しておき、デコーダーでその位置情報を再利用します。これにより、復元時に余計なパラメータを増やしすぎず、効率よく分類マップを作れるようにしています。
エンコーダー:畳み込みとプーリングで特徴を抽出する
エンコーダーは、入力画像から特徴を取り出す部分です。主に畳み込み層とプーリング層を組み合わせて、画像の重要なパターンを段階的に抽出します。畳み込み層は、画像の中にある線、角、輪郭、模様などを検出するフィルターのように働きます。
最初の層では、縦線や横線のような単純な特徴が見つかります。層が深くなるにつれて、輪郭、部品、物体の一部のように、より複雑で抽象的な特徴が扱われるようになります。これは、人が写真を見るときに細かい線や色だけでなく、全体の形や文脈から「道路」「車」「建物」を判断する流れに近い考え方です。
プーリング層は、特徴マップのサイズを小さくしながら重要な情報を残す処理です。画像サイズを縮小することで計算量を抑え、多少の位置ずれにも強い特徴を作れます。ただし、解像度を下げると細かい位置情報が失われやすくなります。SegNetでは、この弱点を補うために最大プーリングの位置情報を保存します。
| 処理 | 役割 | SegNetでの意味 |
|---|---|---|
| 畳み込み | 線、輪郭、模様などの特徴を抽出する | 画像の内容を判断する材料を作る |
| 最大プーリング | 領域内の代表値を残して特徴マップを縮小する | 計算量を抑えつつ、後で使う位置情報を記録する |
デコーダー:特徴マップを元の大きさへ戻して分類する
デコーダーは、エンコーダーで小さくなった特徴マップを元の画像サイズへ近づけ、画素ごとの分類結果を作る部分です。エンコーダーが「画像を理解するための特徴を圧縮する役」だとすれば、デコーダーは「その特徴を使って分類マップを組み立て直す役」です。
復元の過程では、アップサンプリングによって特徴マップの解像度を上げます。SegNetでは、エンコーダーで保存しておいた最大プーリングインデックスを使い、どの位置へ特徴を戻すかを決めます。その後、畳み込みを行って周囲の情報を整え、最終的に各画素がどのクラスに属するかを予測します。
たとえば道路画像であれば、デコーダーは「この画素は道路」「この画素は歩行者」「この画素は車両」という判断を画像全体に対して行います。出力は、元画像と同じような縦横サイズを持つ分類地図になります。画像の見た目をそのまま復元するのではなく、意味ごとに分けられた地図を作ることが目的です。
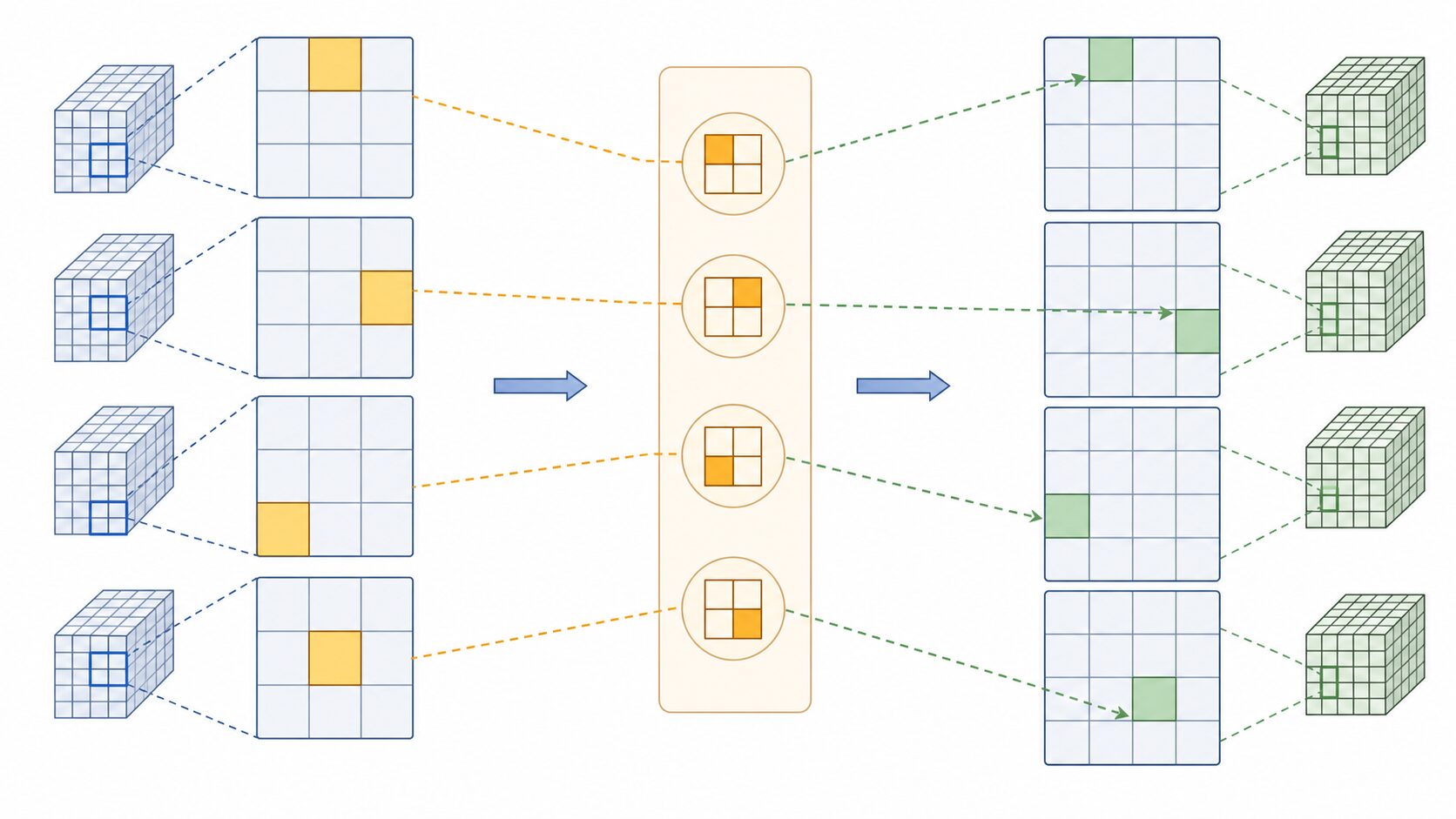
最大プーリングインデックスがSegNetの重要な工夫
SegNetを特徴づけるポイントが、最大プーリングインデックスの利用です。最大プーリングでは、小さな領域の中から最も大きな値を選び、特徴マップを縮小します。このときSegNetは、値そのものだけでなく、どの位置から最大値が選ばれたかを記録します。
デコーダーで特徴マップを拡大するとき、この位置情報があると、特徴をどこへ戻せばよいかの手がかりになります。位置情報を使わずに拡大すると、境界がぼやけたり、必要以上に多くの学習パラメータが必要になったりします。SegNetはプーリングインデックスを再利用することで、メモリや計算量を抑えながら、実用的な分割結果を得る設計になっています。
この工夫は、計算資源が限られる環境や、比較的軽量な画像分割を行いたい場面で意味を持ちます。ただし、すべての位置情報が完全に保たれるわけではありません。細い物体の境界や小さな対象を高精度に分けたい場合は、データ、解像度、後処理、ほかのセグメンテーション手法との比較も必要です。
SegNetの利点と知っておきたい注意点
SegNetの利点は、構造が比較的分かりやすく、エンコーダーとデコーダーの役割を追いやすいことです。畳み込みニューラルネットワークの基礎を学んだ人にとって、画像を縮小して特徴を抽出し、元の解像度へ戻して分類する流れは理解しやすい構成です。
また、最大プーリングインデックスを使うため、デコーダー側で大量のパラメータを増やさずにアップサンプリングを行えます。これにより、メモリ効率や計算効率の面でメリットがあります。自動運転の周辺認識、医療画像の領域抽出、衛星画像の土地分類など、画素単位の判断が必要な分野で応用しやすい技術です。
一方で、SegNetだけを万能な最新手法として見るのは避けた方がよいでしょう。画像分割の分野では、U-Net、DeepLab系、Transformerを使った手法など、多くのモデルが使われています。SegNetは基本構造を学ぶうえで有用ですが、実務ではデータ量、推論速度、境界精度、学習コスト、利用環境を見てモデルを選ぶ必要があります。
| 観点 | SegNetの見方 |
|---|---|
| 強み | エンコーダー・デコーダー構造が分かりやすく、プーリングインデックスにより効率よく復元できる |
| 注意点 | 細かい境界や小さい対象では、用途に応じて他手法との比較が必要 |
| 学習上の位置づけ | 画像分割モデルの基本構造を理解するための良い題材になる |
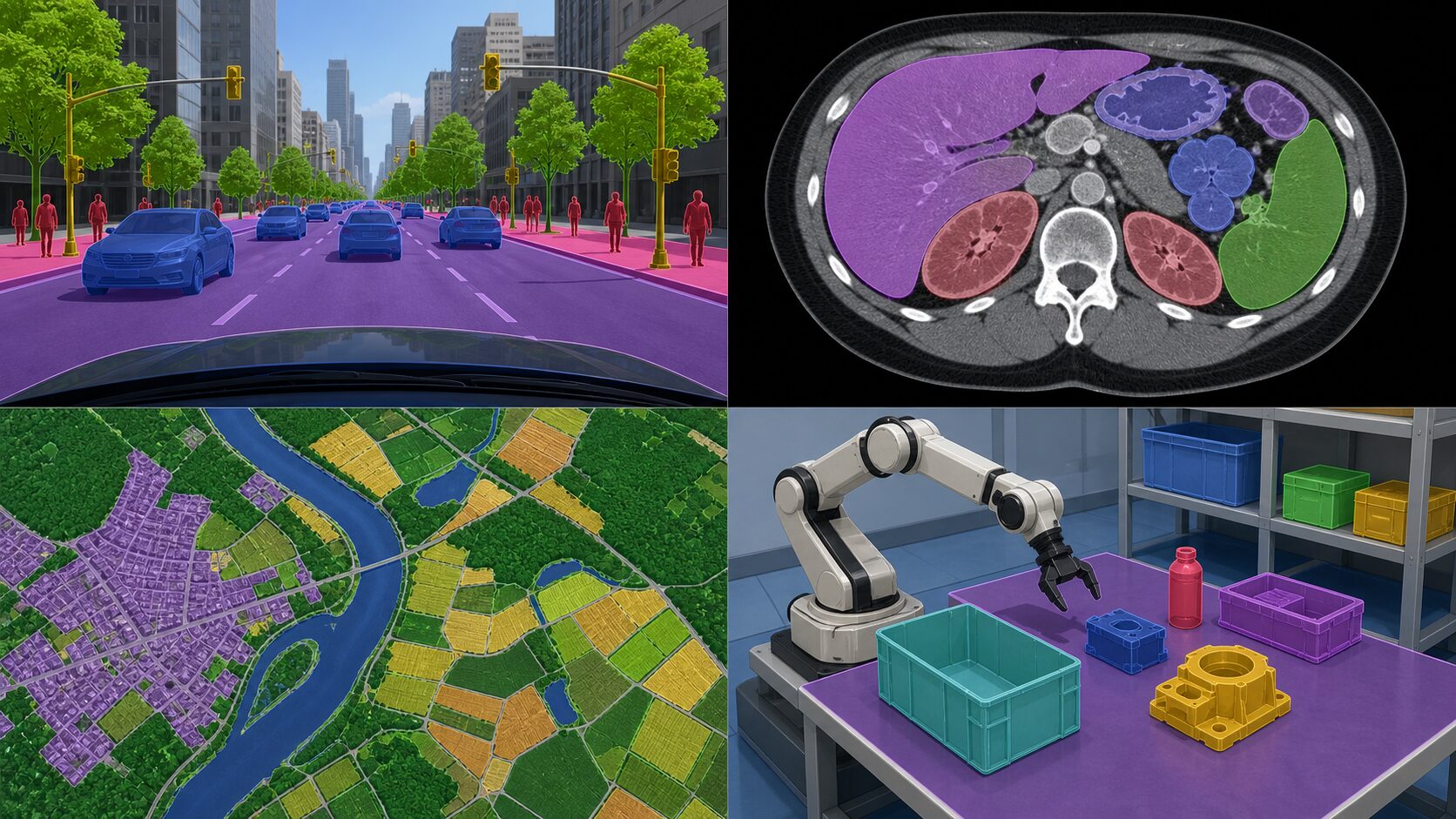
SegNetの主な応用分野
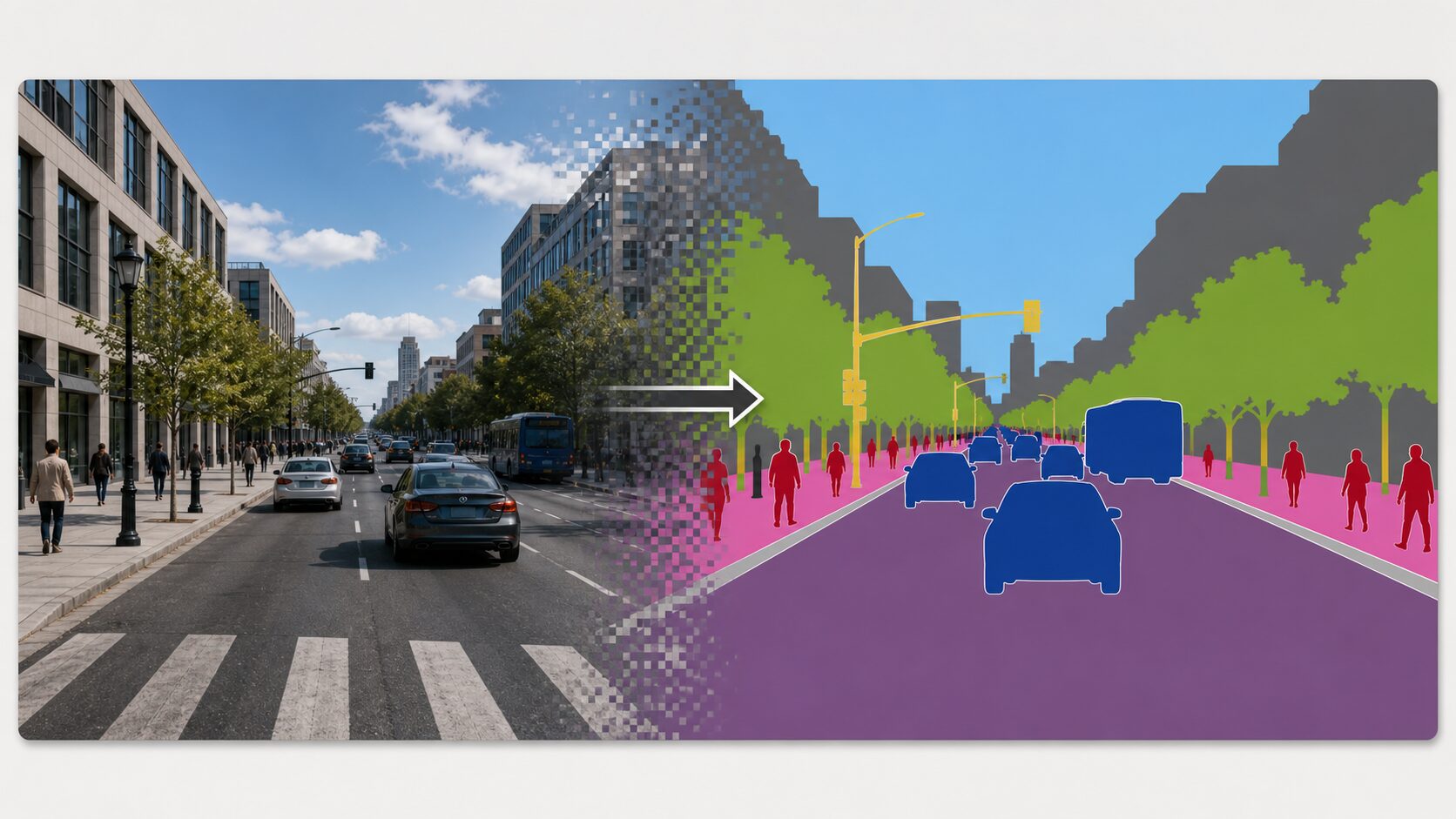
SegNetは、画像内の領域を細かく分類したい分野で活用できます。代表例は自動運転です。車載カメラの画像から、道路、歩道、車両、歩行者、信号、建物などを区別できれば、車両が周囲の状況を理解するための重要な情報になります。
医療画像では、CT、MRI、顕微鏡画像などから、腫瘍や病変の候補領域を抽出する用途が考えられます。医師の判断を置き換えるものではありませんが、診断支援や確認作業の効率化に役立つ可能性があります。衛星画像では、森林、水域、農地、道路、建物などを分類し、土地利用の把握や環境モニタリングに使えます。
ロボット工学でも、周囲の物体や床、障害物を認識するために画像分割が使われます。工場、倉庫、災害現場のように状況が変化する環境では、物体の有無だけでなく、どの領域を移動できるか、どこに障害物があるかを理解することが重要です。SegNetは、こうした「画像を意味のある領域に分ける」考え方を学ぶうえで、今でも押さえておきたいモデルです。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年1月31日 | 初回公開 |
| 2026年5月28日 | 構造と応用例を補い、画像分割での位置づけを追記 |