行動価値関数で最適な行動を探る

AIの初心者
先生、「行動価値関数」って、難しくてよくわからないんです。状態から次の状態にいくときの行動に対する関数って、具体的にどういうことですか?

AI専門家
そうだね、難しいよね。「行動価値関数」は、ある状態である行動をとったときに、将来どれくらい良い結果が得られるかを表す関数なんだ。たとえば、迷路で考えてみよう。今の場所が「状態」で、そこから上下左右に動くのが「行動」だとする。行動価値関数は、それぞれの行動で、ゴールまでどれくらい早くたどり着けるかを表しているんだ。
AIの初心者
なるほど。つまり、今いる場所で、どの行動をすればゴールに近づくかを教えてくれる関数ってことですね。でも、ゴールまでの道のりがわからないのに、どうやってその関数がわかるんですか?
AI専門家
いい質問だね。最初はわからないけど、何度も迷路をやってみることで、だんだんわかってくるんだ。最初は手探りで行動してみて、うまくゴールにたどり着けたら、その行動の価値が高いとわかる。これを繰り返すことで、どの行動をすればいいか、つまり最適な行動がわかるようになる。これが強化学習の基本的な考え方なんだよ。
行動価値関数とは。
「人工知能」について説明します。「行動価値関数」とは、ある状況から次の状況に移るときに、とれる行動それぞれに割り当てられた値のことです。 機械学習の一つである「強化学習」では、最終的に得られる報酬の合計を最大にすることを目指します。そのためには、「状態価値関数」と「行動価値関数」が重要になります。「状態価値関数」はある状態の価値、「行動価値関数」はある状態でとる行動の価値を表します。人工知能は、行動価値関数の合計が最大になるように行動することで、最も効率的な手順で目的を達成することができます。
行動価値関数の概要

行動価値関数は、強化学習においてとても大切な考え方です。強化学習とは、機械学習の一種であり、機械が周りの環境と触れ合いながら、試行錯誤を通して物事を覚えていく方法です。この学習する者を「エージェント」と呼びます。エージェントは、ある状況の中でどのような行動をすれば良いのかを学び、その行動の結果として得られる報酬を最大化しようとします。行動価値関数は「ある状況で、特定の行動をとった時に、将来にわたってどれだけの報酬をもらえるか」という期待値を表す関数です。つまり、ある状況と行動の組み合わせに対して、どれだけの価値があるのかを評価する指標となります。
たとえば、迷路の中でエージェントが右に進むか左に進むかを考えなければならないとします。右に行けばチーズにたどり着けるかもしれませんが、左に行けば猫に出会うかもしれません。この時、行動価値関数は、右に行く行動と左に行く行動にそれぞれどれだけの価値があるのかを数値で示します。チーズは大きな報酬に繋がり、猫は報酬を減らすので、右に行く行動の価値は高く、左に行く行動の価値は低くなります。
エージェントは、この行動価値関数を基に行動を選択します。もし関数が正確であれば、エージェントは常に最も価値の高い行動、つまり最大の報酬が期待できる行動を選びます。逆に、関数が不正確であれば、エージェントは間違った行動を選び、報酬を最大化できません。そのため、この関数を正しく見積もることが、エージェントが最適な行動を選ぶために非常に重要です。 行動価値関数の推定方法は様々で、それぞれの方法に利点と欠点があります。より良い推定方法の研究は、強化学習分野における重要な課題の一つです。
| 用語 | 説明 |
|---|---|
| 強化学習 | 機械学習の一種。機械(エージェント)が環境と相互作用しながら試行錯誤を通して学習する。 |
| エージェント | 強化学習において学習する主体。 |
| 行動価値関数 | ある状況で特定の行動をとった時に、将来にわたって得られる報酬の期待値を表す関数。状況と行動の組み合わせの価値を評価する指標。 |
| 行動価値関数の役割 | エージェントが行動を選択するための基準。関数が正確であれば、エージェントは報酬を最大化する行動を選択できる。 |
| 行動価値関数の重要性 | エージェントが最適な行動を選択するために不可欠。関数の正確な推定が強化学習の重要な課題。 |
状態と行動の評価

私たちは何かをするとき、それが良いことか悪いことかを考えます。例えば、目の前に美味しそうな食べ物があったとき、「食べる」という行動が良いか悪いかを判断します。この判断は、お腹が空いているか、ダイエット中かなど、置かれている状況によって変化します。人工知能も同様に、様々な状況で行動の良し悪しを判断する必要があります。これを「状態と行動の評価」と呼びます。
人工知能は「行動価値関数」を使って、状態と行動の組み合わせを評価します。行動価値関数は、現在の状態とこれからとる行動を入力として受け取り、その行動の価値を表す数値を出力します。この数値が大きいほど、その状態においてその行動をとることが良いことを意味します。
例えば、迷路を解くロボットを想像してみましょう。ロボットのいる場所が「状態」であり、上下左右に動くことが「行動」です。そして、迷路の出口に辿り着くと報酬がもらえます。このとき、出口に近い場所にいるロボットにとって、「出口の方向に進む」という行動の価値は高くなります。逆に、出口から遠い場所にいるロボットにとって、「出口と逆方向に進む」という行動の価値は低くなります。
このように、行動価値関数は、状態によって行動の価値を変えることができます。お腹が空いているときに食べ物を食べる行動の価値が高いのと同じように、出口に近い場所で出口の方向に進む行動の価値は高いのです。人工知能は、この行動価値関数を用いることで、どの行動をとるべきかを判断し、最適な行動を選びます。つまり、行動価値関数は、人工知能が賢く行動するための重要な指針となるのです。
| 概念 | 説明 | 例 |
|---|---|---|
| 状態と行動の評価 | AIが様々な状況で行動の良し悪しを判断すること | 目の前に美味しそうな食べ物がある状況で、「食べる」という行動が良いか悪いかを判断する |
| 行動価値関数 | 状態と行動の組み合わせを入力とし、行動の価値を表す数値を出力する関数。数値が大きいほど、その状態においてその行動が良い。 | 迷路を解くロボットにおいて、出口に近い場所で出口の方向に進む行動は高い価値を持つ |
| 状態 | AIが置かれている状況 | 迷路を解くロボットのいる場所 |
| 行動 | AIがとる動作 | 迷路を解くロボットの上下左右の動き、食べ物を食べる |
| 報酬 | 目標達成時に得られるもの | 迷路の出口に辿り着く |
| 行動価値関数の役割 | AIが賢く行動するための重要な指針 | AIは行動価値関数を用いて最適な行動を選択する |
最適な行動の選択

知的な機械、つまり代理人は、どのようにして状況に応じた最適な行動を選ぶのでしょうか?その鍵となるのが、行動価値関数と呼ばれるものです。これは、ある状況で特定の行動をとった場合に、将来にわたってどれだけの良い結果が得られるかを予測する関数です。
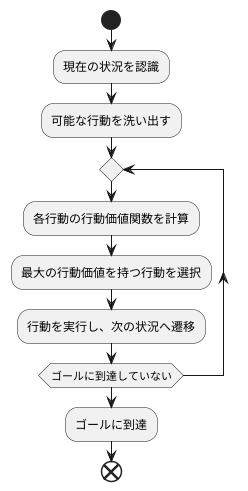
代理人は、まず現在の状況において可能なすべての行動を洗い出します。そして、それぞれの行動に対して行動価値関数を用いて、その行動をとった場合にどれだけの価値、つまり将来得られる報酬の期待値を計算します。例えば、迷路の中を進む機械を想像してみてください。現在の場所で、機械は前後左右に進むことができます。この時、機械はそれぞれの移動方向に対する行動価値を計算します。
次に、代理人は計算された行動価値の中で最も高い値を持つ行動を選択します。迷路の例では、最も高い行動価値を持つ方向に進むことになります。これは、現在の状況から見て、将来ゴールに到達する可能性が最も高い、つまり最も良い結果が期待できる行動を選択することを意味します。
この行動選択と価値計算のプロセスを繰り返すことで、代理人は次第に最適な行動戦略を学習していきます。迷路の機械は、このプロセスを繰り返すことで、行き止まりにぶつかることなく、最終的にゴールにたどり着くことができるようになります。このように、行動価値関数は、代理人が最適な行動戦略を学ぶための土台となる重要な要素であり、状況に応じて適切な行動をとるための指針となるのです。
学習と更新

学習と更新は、人工知能の行動学習において重要な役割を果たします。行動の価値を数値で表したものを行動価値関数と呼びますが、はじめはこの関数はでたらめな値に設定されています。人工知能は、環境とのやり取りを通じて経験を積み重ね、その経験に基づいて行動価値関数を更新していきます。
具体的には、人工知能が何らかの行動をとると、環境はその行動に対する結果を返します。この結果には、報酬と呼ばれる数値が含まれています。報酬は、行動の良さを示す指標であり、値が大きいほど良い行動であったことを意味します。人工知能は、受け取った報酬に基づいて、とった行動の価値を更新します。もし報酬が大きければ、その行動の価値は上がり、次もその行動をとる可能性が高くなります。逆に、報酬が小さければ、その行動の価値は下がり、次にとる可能性は低くなります。
この学習方法は、試行錯誤を通じて最適な行動価値関数を学習し、最適な行動を見つけ出す方法です。迷路を進むロボットを例に考えてみましょう。ロボットは、はじめはどの道が正しいか分からず、様々な道を試します。ゴールにたどり着いた場合には、大きな報酬が与えられます。ゴールまでの道筋の中で、正しい方向へ進んだ行動の価値は上がり、間違った方向へ進んだ行動の価値は下がります。このように、ロボットは何度も迷路に挑戦することで、成功した道筋における行動の価値を高めていき、最終的には最短経路を見つけることができます。
このように、学習と更新は、人工知能が環境に適応し、最適な行動を学習するための重要な仕組みです。
| 用語 | 説明 | 例 |
|---|---|---|
| 行動価値関数 | 行動の価値を数値で表したもの。最初はランダムな値。 | 迷路で、各分岐点でどの道を選ぶかの価値 |
| 報酬 | 行動の良さを示す数値。大きいほど良い行動。 | 迷路のゴールに到達したら大きな報酬 |
| 試行錯誤 | 最適な行動価値関数を学習し、最適な行動を見つける方法。 | ロボットが迷路の様々な道を試す |
| 学習と更新 | AIが環境に適応し、最適な行動を学習する仕組み。 | ロボットが迷路で試行錯誤し、ゴールへの経路を学習 |
将来への展望

行動価値関数は、将来に向けて大きな可能性を秘めた技術であり、様々な分野での活用が期待されています。簡単に言うと、行動価値関数とは、ある状況において特定の行動をとった場合に、将来どれだけの良い結果が得られるかを予測する関数のことです。この関数を用いることで、機械は様々な状況の中で最適な行動を選択できるようになります。
例えば、ロボット制御の分野では、ロボットが目的を達成するために最適な動作を選択するために活用できます。周囲の環境や自身の状態を把握し、行動価値関数を用いてそれぞれの行動の価値を評価することで、ロボットはより効率的に目的を達成するための行動を選択できるようになります。また、ゲームにおいても、コンピューターがプレイヤーに勝つための戦略を学習するために利用できます。過去の対戦データやゲームのルールに基づいて行動価値関数を学習させることで、コンピューターはより高度な戦略を立てることができるようになります。
自動運転の分野では、安全で効率的な運転を実現するために不可欠な技術となるでしょう。交通状況や道路状況、天候などの様々な情報を考慮しながら、行動価値関数を用いて最適な運転操作を選択することで、事故を未然に防ぎ、スムーズな交通を実現することが期待されます。また、医療診断の分野でも、患者の症状や検査結果に基づいて最適な治療方針を決定するために活用できる可能性があります。医師の経験や知識に加えて、行動価値関数を用いることで、より正確で客観的な診断が可能になり、患者一人一人に最適な医療を提供できるようになるでしょう。
今後、計算機の処理能力の向上や学習アルゴリズムの進化に伴い、行動価値関数はさらに複雑な状況にも対応できるようになり、その応用範囲はますます広がっていくと考えられます。人工知能の基盤技術として、様々な社会問題の解決に貢献していくことが期待されます。
| 分野 | 行動価値関数の活用 | 期待される効果 |
|---|---|---|
| ロボット制御 | ロボットが目的を達成するために最適な動作を選択 | より効率的な目的達成 |
| ゲーム | コンピューターがプレイヤーに勝つための戦略を学習 | より高度な戦略 |
| 自動運転 | 安全で効率的な運転を実現するために最適な運転操作を選択 | 事故防止、スムーズな交通 |
| 医療診断 | 患者の症状や検査結果に基づいて最適な治療方針を決定 | より正確で客観的な診断、患者一人一人に最適な医療 |